

 新火種
2023-11-09
新火種
2023-11-09 


OpenAI開源全新解碼器,極大提升StableDiffusion性能
原文來源:AIGC開放社區

圖片來源:由無界 AI生成
在11月7日OpenAI的首屆開發者大會上,除了推出一系列重磅產品之外,還開源了兩款產品,全新解碼器Consistency Decoder(一致性解碼器)和最新語音識別模型Whisper v3。
據悉,Consistency Decoder可以替代Stable Diffusion VAE解碼器。該解碼器可以改善所有與Stable Diffusion 1.0+ VAE兼容的圖像,尤其是在文本、面部和直線方面有大幅度提升。僅上線一天的時間,在Github就收到1100顆星。
Whisper large-v3是OpenAI之前開源的whisper模型的最新版本,在各種語言上的性能都有顯著提升。OpenAI會在未來的API計劃中提供Whisper v3。
解碼器地址:https://github.com/openai/consistencydecoder
Whisper v3地址:https://github.com/openai/whisper
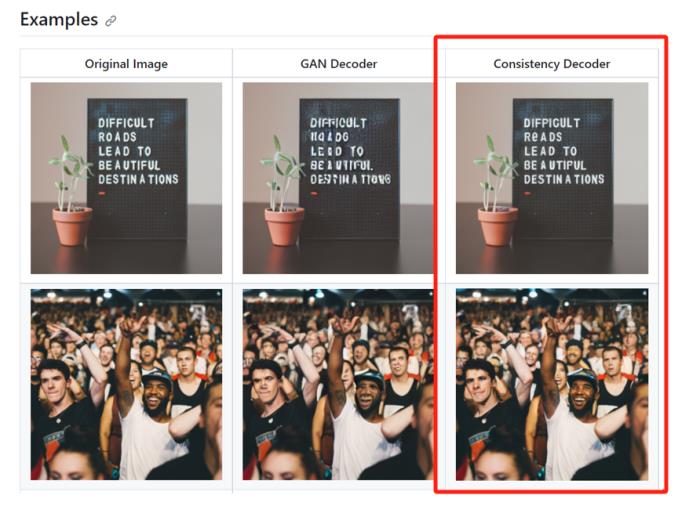
Consistency Decoder效果展示
Consistency Decoder算是OpenAI“一致性”家族里的新成員,所以,「AIGC開放社區」想為大家介紹一下OpenAI之前開源的另一個創新模型——Consistency Models。
擴散模型的出現極大推動了文生圖片、視頻、音頻等領域的發展,涌現了GAN、VAE等知名模型。但是這些模型在推理的過程中,過于依賴迭代采樣過程,導致生成效率非常緩慢或生成圖片質量太差。
OpenAI為了突破這個技術瓶頸,提出了Consistency Models(一致性模型)框架并將其開源。該技術的最大優勢是支持單步高質量生成,同時保留迭代生成的優點。簡單來說,可以使文生圖模型在推理的過程中又快又準攻守兼備。
此外,Consistency Models可以通過提取預先訓練的擴散模型來使用,也可以作為獨立的生成模型來訓練,兼容性強且靈活。
開源地址:https://github.com/openai/consistency_models
論文:https://arxiv.org/abs/2303.01469
為了讓大家更好的理解Consistency Models技術特點,「AIGC開放社區」先簡單的介紹一下擴散模型的原理。
什么是擴散模型
擴散模型主要通過模擬擴散過程來生成數據,核心技術是將數據看作是由一個簡單的隨機過程(例如,高斯白噪聲)經過一系列平滑變換得到的結果。
擴散模型主要由正向過程和反向過程兩大塊組成。正向過程(擴散過程):首先將原始數據通過添加噪聲逐漸擴散,直到變成無法識別的噪聲。
具體來說,每一步都會添加一點噪聲,噪聲的強度通常會隨著步驟的進行而增大。這個過程可以用一個隨機微分方程來描述。
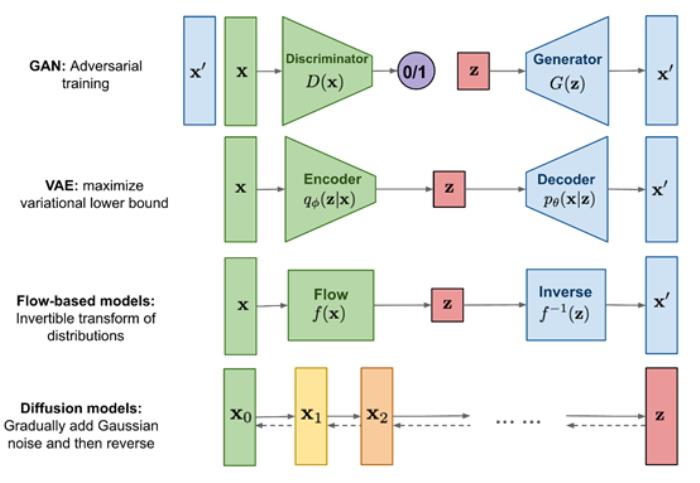
反向過程(去噪聲過程):然后使用一個學習到的模型從噪聲數據中重建原始數據。
這個過程通常通過優化一個目標函數來進行,目標是讓重建的數據與原始數據盡可能相似。
Consistency Models簡單介紹
Consistency Models受擴散模型技術思路啟發,直接將噪聲映射到數據分布,無需迭代過程直接生成高質量圖像。實驗證明,如果模型輸出在同一軌跡上的點保持一致,可以有效學習此映射。

簡單來說,Consistency Models直接放棄了逐步去噪過程,而是直接學習把隨機的噪聲映射到復雜的圖像上,同時加上了一致性的規則約束,避免生成的圖像出現“驢唇不對馬嘴”的情況。
說的更直白一點,我們如果要做一道麻婆豆腐,需要先切豆腐、配菜,然后放在馬勺里進行大火翻炒,再放上調料最后出鍋。
而Consistency Models的方法是直接就變出一盤麻婆豆腐,省去了所有制作流程,并且口味、菜品都是按照用戶標準來的,這就是該技術的神奇之處。
基于上述技術概念,OpenAI的研究人員使用了知識蒸餾和直接訓練兩種方法來訓練Consistency Models。
知識蒸餾:使用一個預先訓練好的擴散模型(如Diffusion),生成一些數據對,然后訓練Consistency Models時讓這些數據對的輸出盡可能接近,來跟擴散模型進行知識蒸餾。

直接訓練法:直接從訓練集樣本中學習數據到噪聲的映射,不需要依賴預訓練模型。主要是加入噪聲進行數據增強,然后優化增強前后的輸出一致性。
實驗數據
研究人員在多個圖像數據集上測試了Consistency Models,包括CIFAR-10、ImageNet 64x64和LSUN 256x256。
結果表明,知識蒸餾訓練的Consistency Models效果最好,在所有數據集和步數下均優于現有最好的蒸餾技術Progressive Distillation。
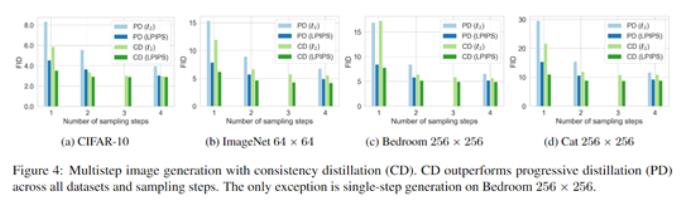
例如,在CIFAR-10上,單步生成達到新記錄的FID 3.55,兩步生成達到2.93;在ImageNet 64x64上,單步生成FID為6.20,兩步生成為4.70,均刷新記錄。
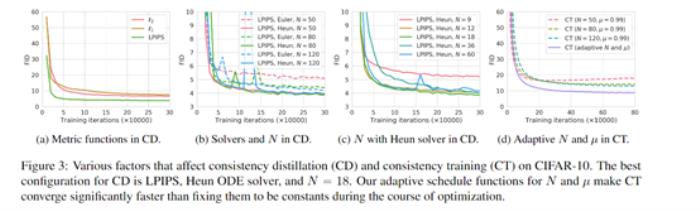
直接訓練方式下,Consistency Models也顯示出強大的能力,在CIFAR-10上打敗了大多數單步生成模型,質量接近Progressive Distillation。
此外,該模型支持進行零樣本圖像編輯,可實現圖像去噪、插值、上色、超分辨率生成、筆觸生成等多種任務,而無需專門訓練。
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
