

 新火種
2023-11-01
新火種
2023-11-01 


DeepMind:誰說卷積網絡不如ViT?
本文通過評估按比例擴大的 NFNets,挑戰了 ConvNets 在大規模上表現不如 ViTs 的觀點。
深度學習的早期成功可歸功于卷積神經網絡(ConvNets)的發展。近十年來,ConvNets 主導了計算機視覺基準測試。然而近年來,它們越來越多地被 ViTs(Vision Transformers)所取代。
很多人認為,ConvNets 在小型或中等規模的數據集上表現良好,但在那種比較大的網絡規模的數據集上卻無法與 ViTs 相競爭。
與此同時,CV 社區已經從評估隨機初始化網絡在特定數據集 (如 ImageNet) 上的性能轉變為評估從網絡收集的大型通用數據集上預訓練的網絡的性能。這就提出了一個重要的問題:在類似的計算預算下,Vision Transformers 是否優于預先訓練的 ConvNets 架構?
本文,來自 Google DeepMind 的研究者對這一問題進行了探究,他們通過在不同尺度的 JFT-4B 數據集(用于訓練基礎模型的大型標簽圖像數據集)上對多種 NFNet 模型進行預訓練,從而獲得了類似于 ViTs 在 ImageNet 上的性能。

論文地址:https://arxiv.org/pdf/2310.16764.pdf
本文考慮的預訓練計算預算在 0.4k 到 110k TPU-v4 核計算小時之間,并通過增加 NFNet 模型家族的深度和寬度來訓練一系列網絡。本文觀察到這一現象,即 held out 損失與計算預算之間存在 log-log 擴展率(scaling law)。
例如,本文將在 JFT-4B 上預訓練的 NFNet 從 0.4k 擴展到 110k TPU-v4 核小時(core hours)。經過微調后,最大的模型達到了 90.4% 的 ImageNet Top-1,在類似的計算預算下與預訓練的 ViT 相競爭。
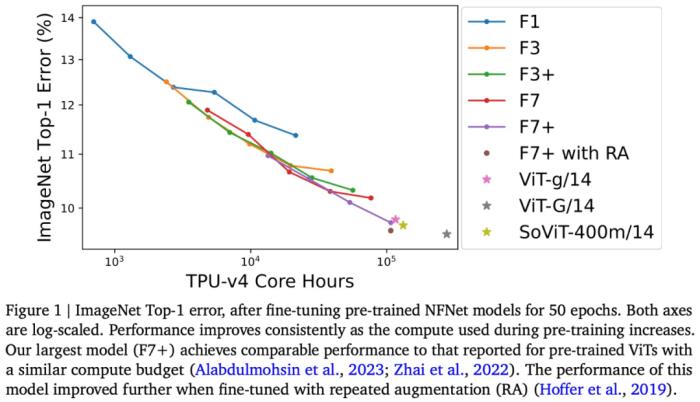
可以說,本文通過評估按比例擴大的 NFNets,挑戰了 ConvNets 在大規模數據集上表現不如 ViTs 的觀點。此外,在足夠的數據和計算條件下,ConvNets 仍然具有競爭力,模型設計和資源比架構更重要。
看到這項研究后,圖靈獎得主 Yann LeCun 表示:「計算是你所需要的,在給定的計算量下,ViT 和 ConvNets 相媲美。盡管 ViTs 在計算機視覺方面的成功令人印象深刻,但在我看來,沒有強有力的證據表明,在公平評估時,預訓練的 ViT 優于預訓練的 ConvNets。」
不過有網友評論 LeCun,他認為 ViT 在多模態模型中的使用可能仍然使它在研究中具有優勢。
來自 Google DeepMind 的研究者表示:ConvNets 永遠不會消失。

接下來我們看看論文具體內容。
預訓練的 NFNets 遵循擴展定律
本文在 JFT-4B 上訓練了一系列不同深度和寬度的 NFNet 模型。
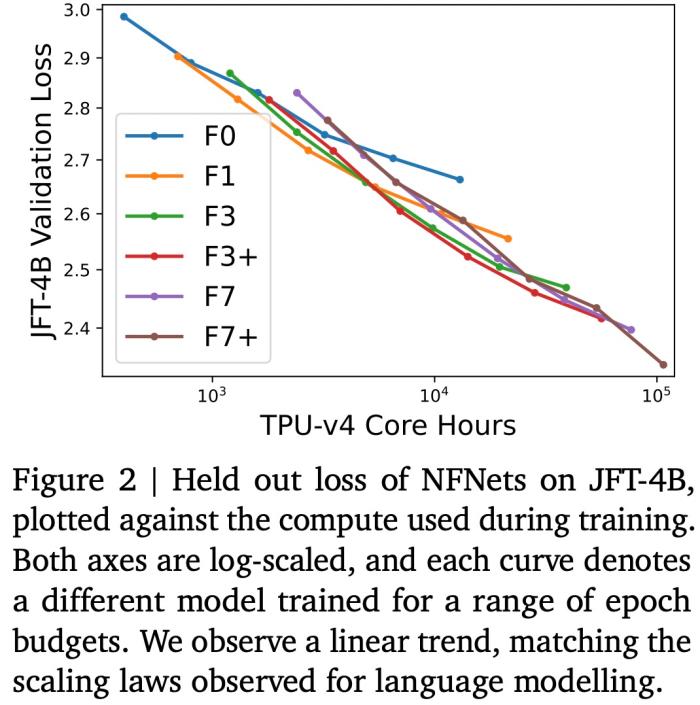
如下圖 2 所示,驗證損失與訓練模型的計算預算呈線性關系,這與使用 Transformer 進行語言建模(Brown et al., 2020; Hoffmann et al., 2022)時觀察到的雙對數(log-log)擴展定律相匹配。最佳模型大小和最佳 epoch 預算(實現最低驗證損失)都會隨著計算預算的增加而增加。
下圖 3 繪制了 3 個模型在一系列 epoch 預算中觀察到的最佳學習率(最大限度地減少驗證損失)。研究團隊發現對于較低的 epoch 預算,NFNet 系列模型都顯示出類似的最佳學習率
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
