

 新火種
2023-10-19
新火種
2023-10-19 


最新3DGAN可生成三維幾何數據了!速度提升7倍|英偉達&斯坦福
明敏 發自 凹非寺量子位 報道 | 公眾號 QbitAI2D圖片變3D,還能給出3D幾何數據?英偉達和斯坦福大學聯合推出的這個GAN,真是刷新了3D GAN的新高度。而且生成畫質也更高,視角隨便搖,面部都沒有變形。 與過去傳統的方法相比,它在速度上能快出7倍,而占用的內存卻不到其十六分之一。最厲害的莫過于還可給出3D幾何數據,像這些石像效果,就是根據提取的位置信息再渲染而得到的。
與過去傳統的方法相比,它在速度上能快出7倍,而占用的內存卻不到其十六分之一。最厲害的莫過于還可給出3D幾何數據,像這些石像效果,就是根據提取的位置信息再渲染而得到的。 甚至還能實時交互編輯。
甚至還能實時交互編輯。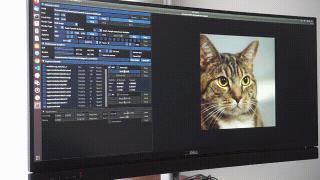 該框架一經發布,就在推特上吸引了大量網友圍觀,點贊量高達600+。
該框架一經發布,就在推特上吸引了大量網友圍觀,點贊量高達600+。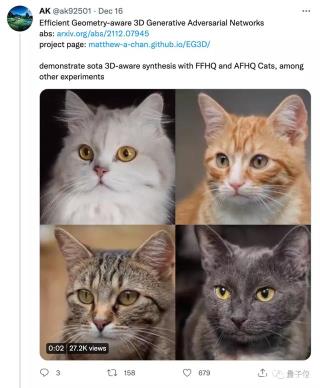 怎么樣?是不是再次刷新你對2D升3D的想象了?顯隱混合+雙重鑒別事實上,只用一張單視角2D照片生成3D效果,此前已經有許多模型框架可以實現。但是它們要么需要計算量非常大,要么給出的近似值與真正的3D效果不一致。這就導致生成的效果會出現畫質低、變形等問題。為了解決以上的問題,研究人員提出了一種顯隱混合神經網絡架構(hybrid explicit-implicit network architecture)。這種方法可以繞過計算上的限制,還能不過分依賴對圖像的上采樣。
怎么樣?是不是再次刷新你對2D升3D的想象了?顯隱混合+雙重鑒別事實上,只用一張單視角2D照片生成3D效果,此前已經有許多模型框架可以實現。但是它們要么需要計算量非常大,要么給出的近似值與真正的3D效果不一致。這就導致生成的效果會出現畫質低、變形等問題。為了解決以上的問題,研究人員提出了一種顯隱混合神經網絡架構(hybrid explicit-implicit network architecture)。這種方法可以繞過計算上的限制,還能不過分依賴對圖像的上采樣。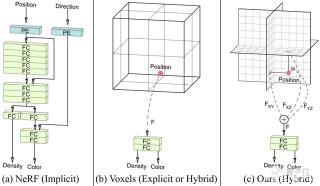 從對比中可以看出,純隱式神經網絡(如NeRF)使用帶有位置編碼(PE)的完全連接層(FC)來表示場景,會導致確定位置的速度很慢。純顯式神經網絡混合了小型隱式解碼器的框架,雖然速度更快,但是卻不能保證高分辨率的輸出效果。
從對比中可以看出,純隱式神經網絡(如NeRF)使用帶有位置編碼(PE)的完全連接層(FC)來表示場景,會導致確定位置的速度很慢。純顯式神經網絡混合了小型隱式解碼器的框架,雖然速度更快,但是卻不能保證高分辨率的輸出效果。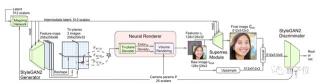 而英偉達和斯坦福大學提出的這個新方法EG3D,就將顯式和隱式的表示優點結合在了一起。它主要包括一個以StyleGAN2為基礎的特征生成器和映射網絡,一個輕量級的特征解碼器,一個神經渲染模塊、一個超分辨率模塊和一個可以雙重識別位置的StyleGAN2鑒別器。其中,神經網絡的主干為顯式表示,它能夠輸出3D坐標;解碼器部分則為隱式表示。與典型的多層感知機制相比,該方法在速度上可快出7倍,而占用的內存卻不到其十六分之一。與此同時,該方法還繼承了StyleGAN2的特性,比如效果良好的隱空間(latent space)。比如,在數據集FFHQ中插值后,EG3D的表現非常nice:
而英偉達和斯坦福大學提出的這個新方法EG3D,就將顯式和隱式的表示優點結合在了一起。它主要包括一個以StyleGAN2為基礎的特征生成器和映射網絡,一個輕量級的特征解碼器,一個神經渲染模塊、一個超分辨率模塊和一個可以雙重識別位置的StyleGAN2鑒別器。其中,神經網絡的主干為顯式表示,它能夠輸出3D坐標;解碼器部分則為隱式表示。與典型的多層感知機制相比,該方法在速度上可快出7倍,而占用的內存卻不到其十六分之一。與此同時,該方法還繼承了StyleGAN2的特性,比如效果良好的隱空間(latent space)。比如,在數據集FFHQ中插值后,EG3D的表現非常nice: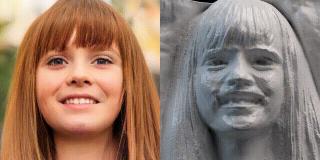 該方法使用中等分辨率(128 x 128)進行渲染,再用2D圖像空間卷積來提高最終輸出的分辨率和圖像質量。這種雙重鑒別,可以確保最終輸出圖像和渲染輸出的一致性,從而避免在不同視圖下由于卷積層不一致而產生的問題。
該方法使用中等分辨率(128 x 128)進行渲染,再用2D圖像空間卷積來提高最終輸出的分辨率和圖像質量。這種雙重鑒別,可以確保最終輸出圖像和渲染輸出的一致性,從而避免在不同視圖下由于卷積層不一致而產生的問題。 △兩圖中左半邊為最終輸出效果,右半邊為渲染輸出而沒有使用雙重鑒別的方法,在嘴角這種細節上就會出現一些扭曲。
△兩圖中左半邊為最終輸出效果,右半邊為渲染輸出而沒有使用雙重鑒別的方法,在嘴角這種細節上就會出現一些扭曲。 △左圖未使用雙重鑒別;右圖為EG3D方法效果數據上,與此前方法對比,EG3D方法在256分辨率、512分辨率下的距離得分(FID)、識別一致性(ID)、深度準確性和姿態準確性上,表現都更好。
△左圖未使用雙重鑒別;右圖為EG3D方法效果數據上,與此前方法對比,EG3D方法在256分辨率、512分辨率下的距離得分(FID)、識別一致性(ID)、深度準確性和姿態準確性上,表現都更好。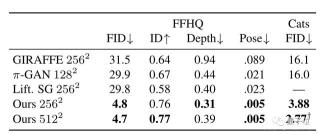 團隊介紹此項研究由英偉達和斯坦福大學共同完成。共同一作共有4位,分別是:Eric R. Chan、Connor Z. Lin、Matthew A. Chan、Koki Nagano。其中,Eric R. Chan是斯坦福大學的一位博士研究生,此前曾參與過一些2D圖像變3D的方法,比如pi-GAN。
團隊介紹此項研究由英偉達和斯坦福大學共同完成。共同一作共有4位,分別是:Eric R. Chan、Connor Z. Lin、Matthew A. Chan、Koki Nagano。其中,Eric R. Chan是斯坦福大學的一位博士研究生,此前曾參與過一些2D圖像變3D的方法,比如pi-GAN。 Connor Z. Lin是斯坦福大學的一位正在讀博二的研究生,本科和碩士均就讀于卡內基梅隆大學,研究方向為計算機圖形學、深度學習等。
Connor Z. Lin是斯坦福大學的一位正在讀博二的研究生,本科和碩士均就讀于卡內基梅隆大學,研究方向為計算機圖形學、深度學習等。 Matthew A. Chan則是一位研究助理,以上三人均來自斯坦福大學計算機成像實驗室(Computational Imaging Lab)。Koki Nagano目前就職于英偉達,擔任高級研究員,研究方向為計算機圖形學,本科畢業于東京大學。
Matthew A. Chan則是一位研究助理,以上三人均來自斯坦福大學計算機成像實驗室(Computational Imaging Lab)。Koki Nagano目前就職于英偉達,擔任高級研究員,研究方向為計算機圖形學,本科畢業于東京大學。 論文地址:https://arxiv.org/abs/2112.07945參考鏈接:https://matthew-a-chan.github.io/EG3D/
論文地址:https://arxiv.org/abs/2112.07945參考鏈接:https://matthew-a-chan.github.io/EG3D/
與過去傳統的方法相比,它在速度上能快出7倍,而占用的內存卻不到其十六分之一。最厲害的莫過于還可給出3D幾何數據,像這些石像效果,就是根據提取的位置信息再渲染而得到的。甚至還能實時交互編輯。該框架一經發布,就在推特上吸引了大量網友圍觀,點贊量高達600+。怎么樣?是不是再次刷新你對2D升3D的想象了?顯隱混合+雙重鑒別事實上,只用一張單視角2D照片生成3D效果,此前已經有許多模型框架可以實現。但是它們要么需要計算量非常大,要么給出的近似值與真正的3D效果不一致。這就導致生成的效果會出現畫質低、變形等問題。為了解決以上的問題,研究人員提出了一種顯隱混合神經網絡架構(hybrid explicit-implicit network architecture)。這種方法可以繞過計算上的限制,還能不過分依賴對圖像的上采樣。從對比中可以看出,純隱式神經網絡(如NeRF)使用帶有位置編碼(PE)的完全連接層(FC)來表示場景,會導致確定位置的速度很慢。純顯式神經網絡混合了小型隱式解碼器的框架,雖然速度更快,但是卻不能保證高分辨率的輸出效果。而英偉達和斯坦福大學提出的這個新方法EG3D,就將顯式和隱式的表示優點結合在了一起。它主要包括一個以StyleGAN2為基礎的特征生成器和映射網絡,一個輕量級的特征解碼器,一個神經渲染模塊、一個超分辨率模塊和一個可以雙重識別位置的StyleGAN2鑒別器。其中,神經網絡的主干為顯式表示,它能夠輸出3D坐標;解碼器部分則為隱式表示。與典型的多層感知機制相比,該方法在速度上可快出7倍,而占用的內存卻不到其十六分之一。與此同時,該方法還繼承了StyleGAN2的特性,比如效果良好的隱空間(latent space)。比如,在數據集FFHQ中插值后,EG3D的表現非常nice:該方法使用中等分辨率(128 x 128)進行渲染,再用2D圖像空間卷積來提高最終輸出的分辨率和圖像質量。這種雙重鑒別,可以確保最終輸出圖像和渲染輸出的一致性,從而避免在不同視圖下由于卷積層不一致而產生的問題。△兩圖中左半邊為最終輸出效果,右半邊為渲染輸出而沒有使用雙重鑒別的方法,在嘴角這種細節上就會出現一些扭曲。△左圖未使用雙重鑒別;右圖為EG3D方法效果數據上,與此前方法對比,EG3D方法在256分辨率、512分辨率下的距離得分(FID)、識別一致性(ID)、深度準確性和姿態準確性上,表現都更好。團隊介紹此項研究由英偉達和斯坦福大學共同完成。共同一作共有4位,分別是:Eric R. Chan、Connor Z. Lin、Matthew A. Chan、Koki Nagano。其中,Eric R. Chan是斯坦福大學的一位博士研究生,此前曾參與過一些2D圖像變3D的方法,比如pi-GAN。Connor Z. Lin是斯坦福大學的一位正在讀博二的研究生,本科和碩士均就讀于卡內基梅隆大學,研究方向為計算機圖形學、深度學習等。Matthew A. Chan則是一位研究助理,以上三人均來自斯坦福大學計算機成像實驗室(Computational Imaging Lab)。Koki Nagano目前就職于英偉達,擔任高級研究員,研究方向為計算機圖形學,本科畢業于東京大學。論文地址:https://arxiv.org/abs/2112.07945參考鏈接:https://matthew-a-chan.github.io/EG3D/
Tags:
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
