

 新火種
2025-01-22
新火種
2025-01-22 

「DeepSeek接班OpenAI」,最新開源的R1推理模型,讓AI圈爆了
OpenAI 的最初愿景,最終被一家國內(nèi)創(chuàng)業(yè)公司實(shí)現(xiàn)了?昨晚,大模型領(lǐng)域再次「熱鬧起來」,月之暗面發(fā)布在數(shù)學(xué)、代碼、多模態(tài)推理能力層面全面對標(biāo) OpenAI 的滿血版 o1 的多模態(tài)思考模型 K1.5。而最近大熱的 DeepSeek 正式推出了 DeepSeek-R1,同樣在數(shù)學(xué)、代碼和自然語言推理等任務(wù)上比肩 OpenAI o1 正式版。去年 12 月開源的大模型 DeepSeek-V3 剛剛掀起了一陣熱潮,實(shí)現(xiàn)了諸多的不可能。這次開源的 R1 大模型則在一開始就讓一眾 AI 研究者感到「震驚」,人們紛紛在猜測這是如何做到的。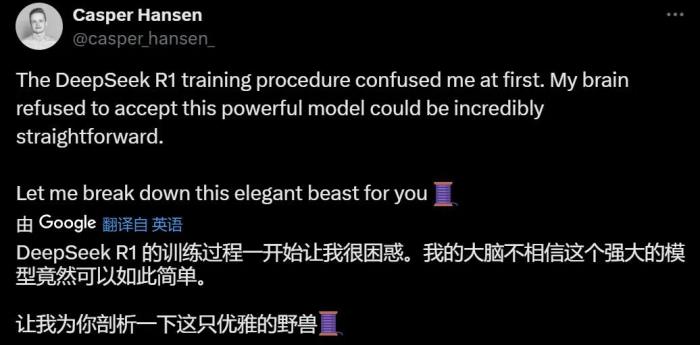
AutoAWQ 作者 Casper Hansen 表示,DeepSeek-R1 使用一種多階段循環(huán)的訓(xùn)練方式:基礎(chǔ)→ RL →微調(diào)→ RL →微調(diào)→ RL。UC Berkeley 教授 Alex Dimakis 則認(rèn)為 DeepSeek 現(xiàn)在已經(jīng)處于領(lǐng)先位置,美國公司可能需要迎頭趕上了。
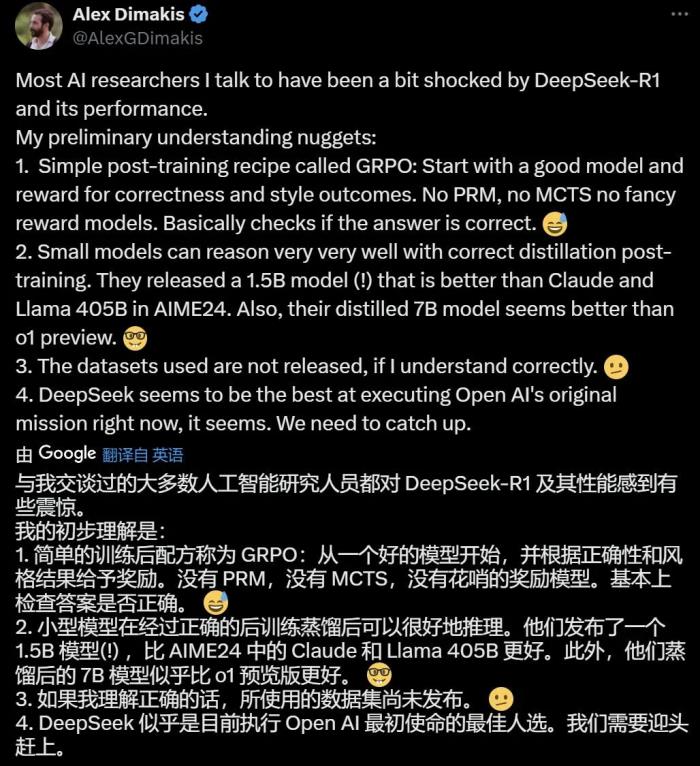
目前,DeepSeek 在網(wǎng)頁端、App 端和 API 端全面上線了 R1,下圖為網(wǎng)頁端對話界面,選擇 DeepSeek-R1 就能直接體驗(yàn)。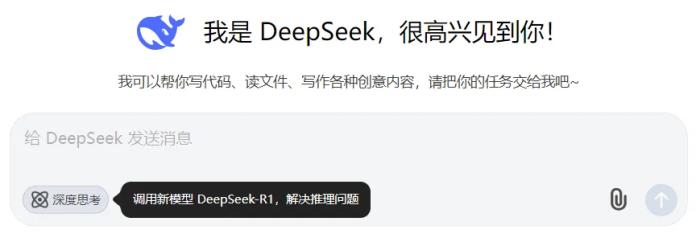
體驗(yàn)地址:https://www.deepseek.com/此次,DeepSeek 發(fā)布了兩個(gè)參數(shù)為 660B 的 DeepSeek-R1-Zero 和 DeepSeek-R1,并選擇開源了模型權(quán)重,同時(shí)允許用戶使用 R1 來訓(xùn)練其他模型。在技術(shù)層面,R1 在后訓(xùn)練階段大規(guī)模使用了強(qiáng)化學(xué)習(xí)(RL)技術(shù),在僅用非常少標(biāo)注數(shù)據(jù)的情況下,極大提升了模型推理能力。下圖為 R1 與 o1-1217、o1-mini、自家 DeepSeek-V3 在多個(gè)數(shù)據(jù)集上的性能比較,可以看到,R1 與 o1-1217 不相上下、互有勝負(fù)。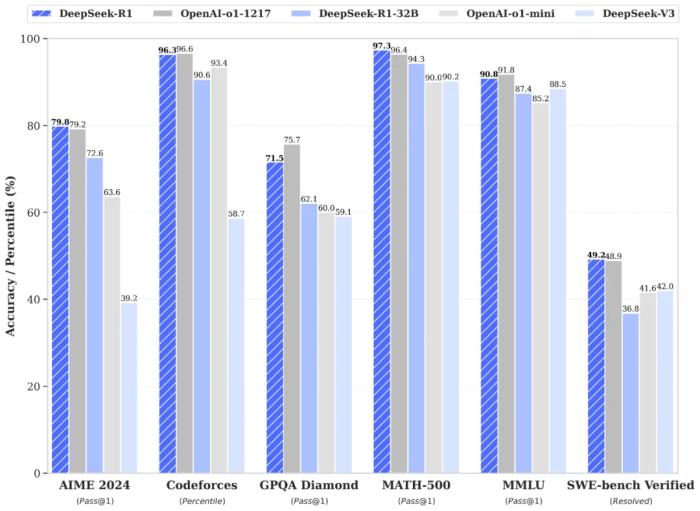
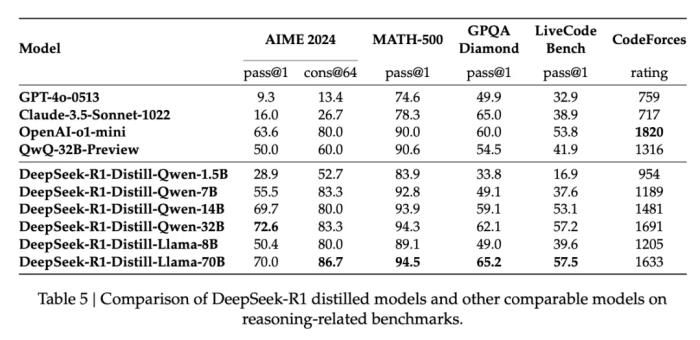
另外,DeepSeek-R1 蒸餾出了六個(gè)小模型,參數(shù)從小到大分別為 1.5B、7B、8B、14B、32B 以及 70B。這六個(gè)模型同樣完全開源,旨在回饋開源社區(qū),推動(dòng)「Open AI」的邊界。
模型下載地址:https://huggingface.co/deepseek-ai?continueFlag=f18057c998f54575cb0608a591c993fb性能方面,蒸餾后的 R1 32B 和 70B 版本遠(yuǎn)遠(yuǎn)超過了 GPT-4o、Claude 3.5 Sonnet 和 QwQ-32B,并逼近 o1-mini。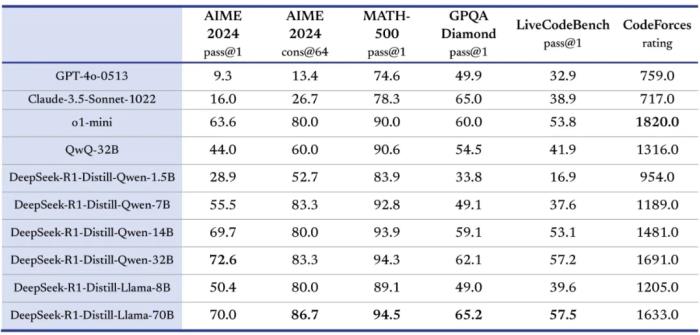
至于很多開發(fā)者關(guān)心的 DeepSeek-R1 API 價(jià)格,可以說是一如既往地給力。DeepSeek-R1 API 服務(wù)的定價(jià)為每百萬輸入 tokens 1 元(緩存命中)/ 4 元(緩存未命中),每百萬輸出 tokens 16 元。
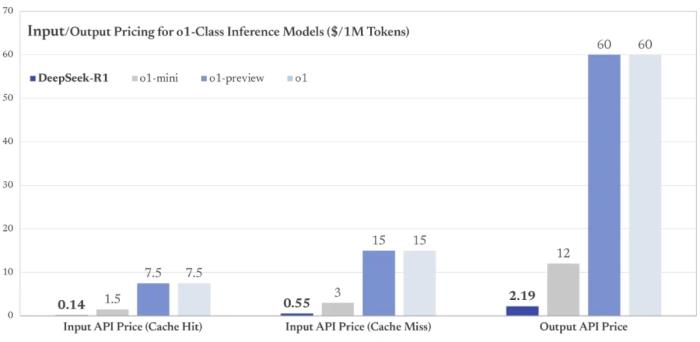
顯然,與 o1 的 API 定價(jià)比起來(每百萬輸入 tokens 15 美元、每百萬輸出 tokens 60 美元),DeepSeek 具有極高的性價(jià)比。
DeepSeek 秉持了開源到底的決心,將 R1 模型的訓(xùn)練技術(shù)全部開放,放出了背后的研究論文。

論文鏈接:https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdfR1 技術(shù)報(bào)告以往的研究主要依賴大量的監(jiān)督數(shù)據(jù)來提升模型性能。DeepSeek 的開發(fā)團(tuán)隊(duì)則開辟了一種全新的思路:即使不用監(jiān)督微調(diào)(SFT)作為冷啟動(dòng),通過大規(guī)模強(qiáng)化學(xué)習(xí)也能顯著提升模型的推理能力。如果再加上少量的冷啟動(dòng)數(shù)據(jù),效果會(huì)更好。為了做到這一點(diǎn),他們開發(fā)了 DeepSeek-R1-Zero。具體來說,DeepSeek-R1-Zero 主要有以下三點(diǎn)獨(dú)特的設(shè)計(jì):首先是采用了群組相對策略優(yōu)化(GRPO)來降低訓(xùn)練成本。GRPO 不需要使用與策略模型同樣大小的評估模型,而是直接從群組分?jǐn)?shù)中估算基線。對于每個(gè)輸入問題 q,GRPO 算法會(huì)從舊策略中采樣一組輸出 {o1, o2, ..., oG},形成評估群組,然后通過最大化目標(biāo)函數(shù)來優(yōu)化策略模型:
其中,優(yōu)勢值 A_i 通過標(biāo)準(zhǔn)化每個(gè)輸出的獎(jiǎng)勵(lì)來計(jì)算: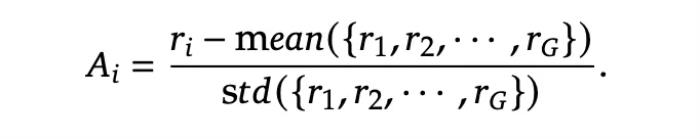
其次是獎(jiǎng)勵(lì)設(shè)計(jì)。如何設(shè)計(jì)獎(jiǎng)勵(lì),決定著 RL 優(yōu)化的方向。DeepSeek 給出的解法是采用準(zhǔn)確度和格式兩種互補(bǔ)的獎(jiǎng)勵(lì)機(jī)制。準(zhǔn)確度獎(jiǎng)勵(lì)用于評估回答的正確性。在數(shù)學(xué)題中,模型需要用特定格式給出答案以便驗(yàn)證;在編程題中,則通過編譯器運(yùn)行測試用例獲取反饋。第二種是格式獎(jiǎng)勵(lì),模型需要將思考過程放在 '
DeepSeek-R1-Zero 的提升也非常顯著。如圖 2 所示,做 2024 年的 AIME 數(shù)學(xué)奧賽試卷,DeepSeek-R1-Zero 的平均 pass@1 分?jǐn)?shù)從最初的 15.6% 顯著提升到了 71.0%,達(dá)到了與 OpenAI-o1-0912 相當(dāng)?shù)乃健T诙鄶?shù)投票機(jī)制中,DeepSeek-R1-Zero 在 AIME 中的成功率進(jìn)一步提升到了 86.7%,甚至超過了 OpenAI-o1-0912 的表現(xiàn)。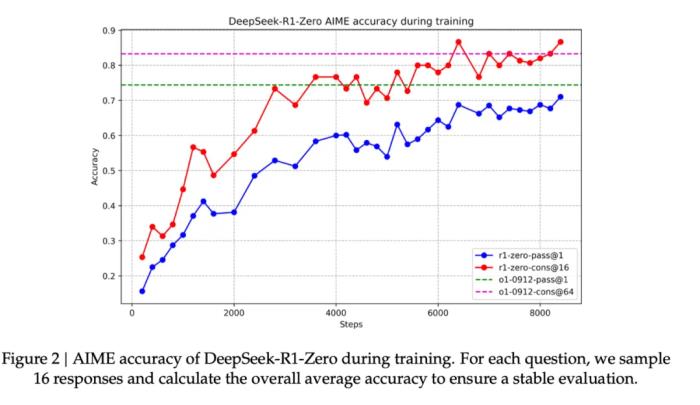
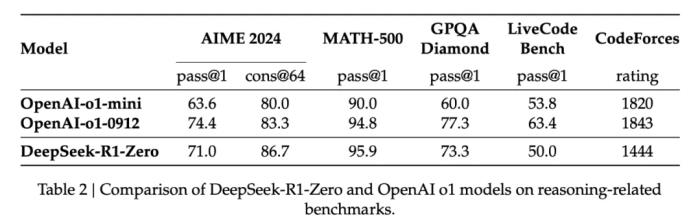
DeepSeek-R1-Zero 與 OpenAI 的 o1-0912 在多個(gè)推理相關(guān)基準(zhǔn)測試上的得分對比。在訓(xùn)練過程中,DeepSeek-R1-Zero 展現(xiàn)出了顯著的自我進(jìn)化能力。它學(xué)會(huì)了生成數(shù)百到數(shù)千個(gè)推理 token,能夠更深入地探索和完善思維過程。隨著訓(xùn)練的深入,模型也發(fā)展出了一些高級行為,比如反思能力和探索不同解題方法的能力。這些都不是預(yù)先設(shè)定的,而是模型在強(qiáng)化學(xué)習(xí)環(huán)境中自然產(chǎn)生的。特別值得一提的是,開發(fā)團(tuán)隊(duì)觀察到了一個(gè)有趣的「Aha Moment」。在訓(xùn)練的中期階段,DeepSeek-R1-Zero 學(xué)會(huì)了通過重新評估初始方法來更合理地分配思考時(shí)間。這可能就是強(qiáng)化學(xué)習(xí)的魅力:只要提供正確的獎(jiǎng)勵(lì)機(jī)制,模型就能自主發(fā)展出高級的解題策略。不過 DeepSeek-R1-Zero 仍然存在一些局限性,如回答的可讀性差、語言混雜等問題。利用冷啟動(dòng)進(jìn)行強(qiáng)化學(xué)習(xí)與 DeepSeek-R1-Zero 不同,為了防止基礎(chǔ)模型在 RL 訓(xùn)練早期出現(xiàn)不穩(wěn)定的冷啟動(dòng)階段,開發(fā)團(tuán)隊(duì)針對 R1 構(gòu)建并收集了少量的長 CoT 數(shù)據(jù),以作為初始 RL actor 對模型進(jìn)行微調(diào)。為了收集此類數(shù)據(jù),開發(fā)團(tuán)隊(duì)探索了幾種方法:以長 CoT 的少樣本提示為例、直接提示模型通過反思和驗(yàn)證生成詳細(xì)答案、以可讀格式收集 DeepSeek-R1-Zero 輸出、以及通過人工注釋者的后處理來細(xì)化結(jié)果。DeepSeek 收集了數(shù)千個(gè)冷啟動(dòng)數(shù)據(jù),以微調(diào) DeepSeek-V3-Base 作為 RL 的起點(diǎn)。與 DeepSeek-R1-Zero 相比,冷啟動(dòng)數(shù)據(jù)的優(yōu)勢包括:可讀性:DeepSeek-R1-Zero 的一個(gè)主要限制是其內(nèi)容通常不適合閱讀。響應(yīng)可能混合多種語言或缺乏 markdown 格式來為用戶突出顯示答案。相比之下,在為 R1 創(chuàng)建冷啟動(dòng)數(shù)據(jù)時(shí),開發(fā)團(tuán)隊(duì)設(shè)計(jì)了一個(gè)可讀模式,在每個(gè)響應(yīng)末尾包含一個(gè)摘要,并過濾掉不友好的響應(yīng)。潛力:通過精心設(shè)計(jì)具有人類先驗(yàn)知識的冷啟動(dòng)數(shù)據(jù)模式,開發(fā)團(tuán)隊(duì)觀察到相較于 DeepSeek-R1-Zero 更好的性能。開發(fā)團(tuán)隊(duì)相信迭代訓(xùn)練是推理模型的更好方法。推理導(dǎo)向的強(qiáng)化學(xué)習(xí)在利用冷啟動(dòng)數(shù)據(jù)上對 DeepSeek-V3-Base 進(jìn)行微調(diào)后,開發(fā)團(tuán)隊(duì)采用與 DeepSeek-R1-Zero 相同的大規(guī)模強(qiáng)化學(xué)習(xí)訓(xùn)練流程。此階段側(cè)重于增強(qiáng)模型的推理能力,特別是在編碼、數(shù)學(xué)、科學(xué)和邏輯推理等推理密集型任務(wù)中。為了緩解語言混合的問題,開發(fā)團(tuán)隊(duì)在 RL 訓(xùn)練中引入了語言一致性獎(jiǎng)勵(lì),其計(jì)算方式為 CoT 中目標(biāo)語言單詞的比例。雖然消融實(shí)驗(yàn)表明這種對齊會(huì)導(dǎo)致模型性能略有下降,但這種獎(jiǎng)勵(lì)符合人類偏好,更具可讀性。最后,開發(fā)團(tuán)隊(duì)將推理任務(wù)的準(zhǔn)確率和語言一致性的獎(jiǎng)勵(lì)直接相加,形成最終獎(jiǎng)勵(lì)。然后對微調(diào)后的模型進(jìn)行強(qiáng)化學(xué)習(xí) (RL) 訓(xùn)練,直到它在推理任務(wù)上實(shí)現(xiàn)收斂。拒絕采樣和監(jiān)督微調(diào)當(dāng)面向推理導(dǎo)向的強(qiáng)化學(xué)習(xí)收斂時(shí),開發(fā)團(tuán)隊(duì)利用生成的檢查點(diǎn)為后續(xù)輪次收集 SFT(監(jiān)督微調(diào))數(shù)據(jù)。此階段結(jié)合了來自其他領(lǐng)域的數(shù)據(jù),以增強(qiáng)模型在寫作、角色扮演和其他通用任務(wù)中的能力。開發(fā)團(tuán)隊(duì)通過從上述強(qiáng)化學(xué)習(xí)訓(xùn)練的檢查點(diǎn)執(zhí)行拒絕采樣來整理推理提示并生成推理軌跡。此階段通過合并其他數(shù)據(jù)擴(kuò)展數(shù)據(jù)集,其中一些數(shù)據(jù)使用生成獎(jiǎng)勵(lì)模型,將基本事實(shí)和模型預(yù)測輸入 DeepSeek-V3 進(jìn)行判斷。此外,開發(fā)團(tuán)隊(duì)過濾掉了混合語言、長段落和代碼塊的思路鏈。對于每個(gè)提示,他們會(huì)抽取多個(gè)答案,并僅保留正確的答案。最終,開發(fā)團(tuán)隊(duì)收集了約 60 萬個(gè)推理相關(guān)的訓(xùn)練樣本。用于所有場景的強(qiáng)化學(xué)習(xí)為了進(jìn)一步使模型與人類偏好保持一致,這里還要實(shí)施第二階段強(qiáng)化學(xué)習(xí),旨在提高模型的有用性和無害性,同時(shí)完善其推理能力。具體來說,研究人員使用獎(jiǎng)勵(lì)信號和各種提示分布的組合來訓(xùn)練模型。對于推理數(shù)據(jù),遵循 DeepSeek-R1-Zero 中概述的方法,該方法利用基于規(guī)則的獎(jiǎng)勵(lì)來指導(dǎo)數(shù)學(xué)、代碼和邏輯推理領(lǐng)域的學(xué)習(xí)過程;對于一般數(shù)據(jù),則采用獎(jiǎng)勵(lì)模型來捕捉復(fù)雜而微妙的場景中的人類偏好。最終,獎(jiǎng)勵(lì)信號和多樣化數(shù)據(jù)分布的整合使我們能夠訓(xùn)練出一個(gè)在推理方面表現(xiàn)出色的模型,同時(shí)優(yōu)先考慮有用性和無害性。蒸餾:讓小模型具備推理能力為了使更高效的小模型具備 DeekSeek-R1 那樣的推理能力,開發(fā)團(tuán)隊(duì)還直接使用 DeepSeek-R1 整理的 80 萬個(gè)樣本對 Qwen 和 Llama 等開源模型進(jìn)行了微調(diào)。研究結(jié)果表明,這種簡單的蒸餾方法顯著增強(qiáng)了小模型的推理能力。得益于以上多項(xiàng)技術(shù)的創(chuàng)新,開發(fā)團(tuán)隊(duì)的大量基準(zhǔn)測試表明,DeepSeek-R1 實(shí)現(xiàn)了比肩業(yè)內(nèi) SOTA 推理大模型的硬實(shí)力,具體可以參考以下結(jié)果: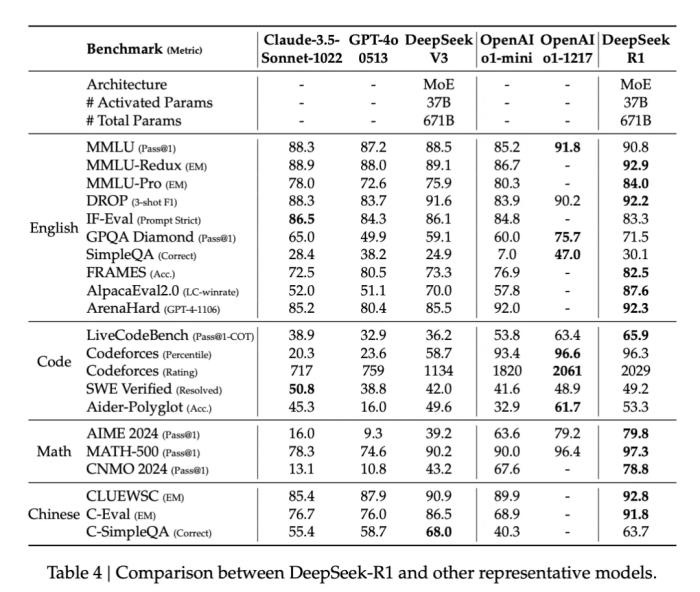
更多技術(shù)細(xì)節(jié)請參閱原論文。
Tags:
相關(guān)推薦

- 免責(zé)聲明
- 本文所包含的觀點(diǎn)僅代表作者個(gè)人看法,不代表新火種的觀點(diǎn)。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對本文可能提及或鏈接的任何項(xiàng)目不表示認(rèn)可。 交易和投資涉及高風(fēng)險(xiǎn),讀者在采取與本文內(nèi)容相關(guān)的任何行動(dòng)之前,請務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨(dú)立判斷。新火種不對因依賴本文觀點(diǎn)而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
