

 新火種
2025-01-08
新火種
2025-01-08 

首頁 >
AI資訊 >
行業(yè)動(dòng)態(tài) >
AI大模型權(quán)威評(píng)測(cè):豆包中文對(duì)話最強(qiáng),OpenAIo1推理和數(shù)學(xué)占優(yōu)
AI大模型權(quán)威評(píng)測(cè):豆包中文對(duì)話最強(qiáng),OpenAIo1推理和數(shù)學(xué)占優(yōu)
作者 | 徐豫
編輯 | 漠影
還有不到一周就2025年了,各大社交音娛平臺(tái)相繼自動(dòng)彈出“年度報(bào)告”的搜索選項(xiàng)。身處AI元年,AI模型這份年終答卷,自然也少不了。
智東西12月25日?qǐng)?bào)道,智源研究院12月19日發(fā)布了FlagEval“百模”評(píng)測(cè)結(jié)果,今年國(guó)產(chǎn)大模型與海外大模型戰(zhàn)況焦灼。
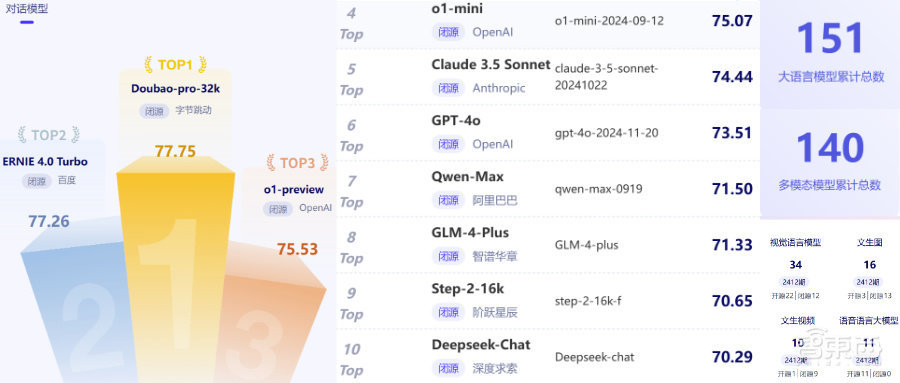
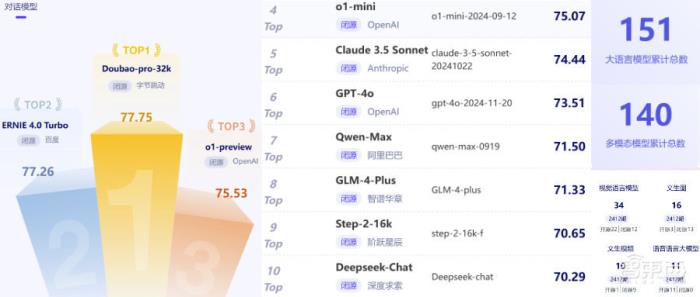
在其閉源大模型評(píng)測(cè)能力總榜中,字節(jié)跳動(dòng)的豆包通用模型pro拿到主觀評(píng)測(cè)最高分,OpenAI的o1-mini拿到客觀評(píng)測(cè)最高分;多模態(tài)模型評(píng)測(cè)總榜前三名依次是OpenAI的GPT-4o、字節(jié)跳動(dòng)的豆包視覺理解模型、Anthropic的Claude 3.5 Sonnet。

▲大語言模型評(píng)測(cè)能力榜單前三名(圖片來源:智源研究院)
此次評(píng)測(cè)包含國(guó)內(nèi)外累計(jì)100多個(gè)開源和商業(yè)閉源的語言、視覺語言、文生圖、文生視頻、語音語言大模型,新增了對(duì)于AI模型任務(wù)解決能力、真實(shí)金融量化交易場(chǎng)景應(yīng)用能力、辯論能力的考量標(biāo)準(zhǔn)。
同時(shí),為了盡可能降低數(shù)據(jù)集泄露風(fēng)險(xiǎn),并減少數(shù)據(jù)集飽和度問題,本次評(píng)測(cè)吸納了近期發(fā)布的數(shù)據(jù)集、持續(xù)動(dòng)態(tài)更新評(píng)測(cè)數(shù)據(jù)、替換了98%的題目以及提升了題目的難度。
其實(shí)去年6月,智源研究院就上線了大模型評(píng)測(cè)平臺(tái)FlagEval,到現(xiàn)在該平臺(tái)已有基于AI的輔助評(píng)測(cè)模型FlagJudge、多模態(tài)評(píng)測(cè)框架FlagEvalMM和針對(duì)大模型新能力的評(píng)測(cè)集。其與北京大學(xué)共建的HalluDial是目前全球規(guī)模最大的、對(duì)話場(chǎng)景下的幻覺評(píng)測(cè)集,包含超18000個(gè)輪次對(duì)話和超14萬個(gè)回答。
從智源評(píng)測(cè)最新結(jié)果可以看出,今年下半年大模型發(fā)展更側(cè)重綜合能力提升與實(shí)際應(yīng)用;多模態(tài)模型快速發(fā)展,該領(lǐng)域內(nèi)涌現(xiàn)了不少新廠商與新AI模型;語言模型的發(fā)展則相對(duì)放緩。
得益于多模態(tài)能力的提升,AI模型最新K12學(xué)科測(cè)驗(yàn)綜合得分相較于半年前提升了12.86%,但是仍與北京海淀學(xué)生平均水平存在差距。不過,AI模型普遍存在“文強(qiáng)理弱”的偏科情況,在英語和歷史文科試題的表現(xiàn)上,已有AI模型超越了人類考生的平均分。
谷歌Gemini 1.5 Pro、阿里巴巴Qwen-VL-Max、Anthropic Claude 3.5 Sonnet、階躍星辰Step 1V、南洋理工大學(xué)LLaVA-Onevision等7家AI模型的英語學(xué)科綜合得分高于人類考生;階躍星辰Step 1V、阿里巴巴Qwen-VL和Qwen-VL-Max、谷歌Gemini 1.5 Pro、南洋理工大學(xué)LLaVA-Onevision等12家AI模型的歷史學(xué)科綜合得分高于人類考生。

▲大模型K12學(xué)科測(cè)驗(yàn)歷史學(xué)科卷面分?jǐn)?shù)榜單前五名(圖片來源:智源研究院)
一、豆包中文對(duì)話能力最強(qiáng),OpenAI o1系列推理水平斷層領(lǐng)先
基于智源評(píng)測(cè)結(jié)果,今年多款國(guó)產(chǎn)大模型綜合能力超過海外知名大模型。
在閉源大模型主觀評(píng)測(cè)中,豆包通用模型pro和百度ERNIE 4.0 Turbo的綜合評(píng)分均領(lǐng)先于OpenAI的o1-preview、o1-mini、GPT-4o;而在開源大模型主觀評(píng)測(cè)中,阿里巴巴Qwen2.5的綜合評(píng)分高于Meta Llama 3.3和Llama 3.1。
主觀評(píng)測(cè)更偏重考察大模型中文能力,而國(guó)產(chǎn)大模型在中文語言能力上具有普遍優(yōu)勢(shì)。
因此,從實(shí)際綜合評(píng)分可以看出,國(guó)產(chǎn)大模型占據(jù)了閉源大模型主觀評(píng)測(cè)榜單的大半壁江山。其前20名中共有15款國(guó)產(chǎn)大模型,占比75%,包括豆包通用模型pro、百度ERNIE 4.0 Turbo、阿里巴巴Qwen-Max、智譜華章GLM-4-Plus、階躍星辰Step 2等。

▲大語言模型評(píng)測(cè)能力榜單主觀評(píng)測(cè)前五名(圖片來源:智源研究院)
不過,如果把大模型放在客觀評(píng)測(cè)池子里比較,國(guó)產(chǎn)大模型的表現(xiàn)仍與海外大模型有著一定差距。
OpenAI的o1-mini獲得客觀評(píng)測(cè)的最高分64.57,同樣屬于o1系列的o1-preview,以60.36的綜合評(píng)分位列榜單第二。該項(xiàng)評(píng)測(cè)中阿里巴巴的Qwen-Max和豆包通用模型pro各自的綜合評(píng)分為57.60和56.49,與o1-mini之間大概有7分的分差,與o1-preview之間大概有3分的分差。

▲大語言模型評(píng)測(cè)能力榜單客觀評(píng)測(cè)前五名(圖片來源:智源研究院)
結(jié)合各項(xiàng)細(xì)分能力的評(píng)分來看,國(guó)產(chǎn)大模型更“重文輕理”,主要在推理、數(shù)學(xué)、代碼等方面落后于OpenAI的大模型。例如,即便是側(cè)重中文語境,OpenAI o1-preview仍拿到主觀評(píng)測(cè)任務(wù)解決板塊的最高分85.37,與第二名的79.52分和第三名的77.41分相比領(lǐng)先優(yōu)勢(shì)較為明顯。
二、多模態(tài)評(píng)測(cè),國(guó)產(chǎn)大模型各擅勝場(chǎng)
據(jù)智源研究院調(diào)研,今年市面上頭部模型的多模態(tài)能力得到大幅提升,上半年參評(píng)的模型普遍無法生成正確的中文文字,但年末參評(píng)的頭部模型已經(jīng)具備中文文字生成能力。
從此次多模態(tài)模型評(píng)測(cè)數(shù)據(jù)來看,視覺語言模型平均排名前三分別是OpenAI的GPT-4o、豆包視覺理解模型和Anthropic的Claude 3.5 Sonnet。這三者中豆包的通用知識(shí)、文字識(shí)別等中文能力與其他兩家拉開了較大差距,若單看英文圖表理解表現(xiàn)則Claude的排名最靠前。

▲視覺語言模型排行榜前三名(圖片來源:智源研究院)
面對(duì)文本、圖片、視頻、語音等多模態(tài)數(shù)據(jù)的處理時(shí),豆包文生圖模型、豆包視頻生成模型“即夢(mèng)P2.0 pro”分別在相應(yīng)測(cè)試中位列全球第二,騰訊Hunyuan Image文生圖水平全球第一,快手可靈1.5(高品質(zhì)版)文生視頻水平全球第一,阿里巴巴Qwen2-Audio語音語言水平全球第一。

▲文生視頻模型排行榜前三名(左),文生圖模型排行榜前三名(右)(圖片來源:智源研究院)
目前,AI文生圖的技術(shù)整體趨于成熟,但AI文生視頻領(lǐng)域仍有較多挑戰(zhàn)。現(xiàn)階段,熱門的AI文生視頻模型有可靈1.5(高品質(zhì)版)、即夢(mèng)P2.0 pro、愛詩科技PixVerse V3、Minimax海螺AI、Pika同名AI模型Pika 1.5等。
其中,位列榜單第一、二名的可靈和即夢(mèng)均可生成時(shí)長(zhǎng)10s的視頻,所生成的視頻在圖文一致性上也打成平手,但前者在AI視頻真實(shí)性和視頻質(zhì)量略勝一籌,后者則在AI視頻美學(xué)質(zhì)量和分辨率上實(shí)現(xiàn)反超。
上述幾家多模態(tài)模型中,只有阿里巴巴的走開源路線。對(duì)于多模態(tài)開源模型的實(shí)際效果,智源研究院方面稱,雖然開源模型架構(gòu)趨同,即通常采用語言塔和視覺塔的架構(gòu),但具體表現(xiàn)不一。其中較好的開源模型,在圖文理解任務(wù)上正在縮小與頭部閉源模型的能力差距,而長(zhǎng)尾視覺知識(shí)與文字識(shí)別,以及復(fù)雜圖文數(shù)據(jù)分析能力仍有提升空間。
三、AI模型更擅長(zhǎng)反駁辯題,還可任職金融行業(yè)初級(jí)崗位
智源研究院在AI模型的年末評(píng)測(cè)中,新設(shè)置了對(duì)其辯論能力和金融量化交易能力的考核維度。
不到3個(gè)月前,智源研究院推出了一個(gè)名為FlagEval Debate的AI模型辯論平臺(tái)。該平臺(tái)主要從邏輯推理、觀點(diǎn)理解和語言表達(dá)等核心能力維度,深入評(píng)估AI語言模型的能力差異。
據(jù)最新評(píng)測(cè)結(jié)果,一方面AI大模型普遍缺乏辯論框架意識(shí),不具備圍繞辯題、以整體邏輯綜合闡述的能力;另一方面AI大模型在辯論中仍然存在“幻覺”問題,給出的論據(jù)通常經(jīng)不起推敲。
相比于“正方”,AI大模型似乎更適合做辯論賽的“反方”。此次評(píng)測(cè)結(jié)果表明AI大模型更擅長(zhǎng)反駁,各個(gè)模型所突出的辯論維度趨同。不過,遇到不同的辯題時(shí)AI模型間的表現(xiàn)差距會(huì)較為顯著。
總體來看,在FlagEval Debate評(píng)測(cè)中,Anthropic Claude 3.5 Sonnet、零一萬物Yi-Lighting、OpenAI o1-preview的綜合水平排行前三。
而在金融量化交易領(lǐng)域,此次評(píng)測(cè)發(fā)現(xiàn)大模型已具備生成有回撤收益的策略代碼的能力,能開發(fā)量化交易典型場(chǎng)景里的代碼,頭部AI模型能力已接近初級(jí)量化交易員的水平。
該榜單前5名依次是深度求索的DeepSeek-V2.5、OpenAI的GPT-4o、OpenAI的o1-mini、谷歌的Gemini 1.5 Pro和智譜華章的GLM-4-Plus。此外,百度、騰訊、字節(jié)跳動(dòng)、商湯、阿里巴巴、百川智能和零一萬物等7家國(guó)產(chǎn)大模型開發(fā)商均有產(chǎn)品上榜。

▲金融量化交易評(píng)測(cè)榜單前五名(圖片來源:智源研究院)
智源研究院主要用知識(shí)問答、交易策略的跑通率和夏普指數(shù)、指標(biāo)計(jì)算的跑通率和準(zhǔn)確率、計(jì)算性能的跑通率這6項(xiàng)指標(biāo),來比較AI模型的金融量化交易能力。
其中,在知識(shí)問答方面,AI模型整體差異較小且整體分?jǐn)?shù)偏高,大部分得分介于0.97到1之間,最低分為Meta Llama 3.1的0.69。然而,面對(duì)實(shí)際代碼生成任務(wù)時(shí),各AI模型差異較大,并且整體能力偏弱。
結(jié)語:國(guó)產(chǎn)大模型競(jìng)爭(zhēng)加劇,下半場(chǎng)比拼商用質(zhì)量
在這場(chǎng)“百家爭(zhēng)鳴”中,國(guó)產(chǎn)大模型開發(fā)商們不僅鞏固了其AI模型的中文能力優(yōu)勢(shì),還進(jìn)一步開發(fā)了文生圖、文生視頻、文生語音等多模態(tài)模型潛力。
過去一年,大模型領(lǐng)域也迎來了諸多新拐點(diǎn),Scaling Law相對(duì)放緩、AI模型的數(shù)學(xué)能力從中學(xué)生水平躍升到博士生水平、OpenAI 12月底剛發(fā)布的推理模型o3性能接近甚至超過了人類水平、背靠AI模型的AI Agent概念和產(chǎn)品熱度攀升。
下一步,AI模型將從卷參數(shù)量邁向卷應(yīng)用場(chǎng)景,催熟商業(yè)化落地的效率和效益。
相關(guān)推薦



- 免責(zé)聲明
- 本文所包含的觀點(diǎn)僅代表作者個(gè)人看法,不代表新火種的觀點(diǎn)。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對(duì)本文可能提及或鏈接的任何項(xiàng)目不表示認(rèn)可。 交易和投資涉及高風(fēng)險(xiǎn),讀者在采取與本文內(nèi)容相關(guān)的任何行動(dòng)之前,請(qǐng)務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨(dú)立判斷。新火種不對(duì)因依賴本文觀點(diǎn)而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
