

 新火種
2023-10-10
新火種
2023-10-10 


升級(jí)到PyTorch 2.0的技巧總結(jié)

來源:DeepHub IMBA本文約6400字,建議閱讀12分鐘在本文將演示 PyTorch 2.0新功能的使用,以及介紹在使用它時(shí)可能遇到的一些問題。PyTorch 2.0 發(fā)布也有一段時(shí)間了,大家是不是已經(jīng)開始用了呢?PyTorch 2.0 通過引入 torch.compile,可以顯著提高訓(xùn)練和推理速度。與 eagerly 模式相反,編譯 API 將模型轉(zhuǎn)換為中間計(jì)算圖(FX graph),然后以某種方式將其編譯為低級(jí)計(jì)算內(nèi)核,這樣可以提高運(yùn)行速度。

對(duì)于PyTorch 2.0 而言,你看到的可能是:
“只是用 torch.compile 調(diào)用包裝它們就可以提高運(yùn)行速度”
但是其實(shí)有許多因素會(huì)干擾計(jì)算圖編譯和/或達(dá)到所需的性能改進(jìn)。所以需要調(diào)整模型和達(dá)到最佳性能可能需要重新設(shè)計(jì)項(xiàng)目或修改一些編碼習(xí)慣。
在本文中,我們將演示這個(gè)新功能的使用,以及介紹在使用它時(shí)可能遇到的一些問題。我們將分享在調(diào)整 torch.compile API 時(shí)遇到的問題的幾個(gè)例子。這些例子并不全面,再實(shí)際運(yùn)用是很可能會(huì)遇到此處未提及的問題,并且還要 torch.compile 仍在積極開發(fā)中,還有改進(jìn)的空間。
Torch 編譯背后有許多創(chuàng)新技術(shù),包括 TorchDynamo、FX Graph、TorchInductor、Triton 等。我們不會(huì)在這篇文章中深入探討不同的組件,如果你對(duì)這些感興趣,可以查看PyTorch 文檔,里面介紹的非常詳細(xì)。
TensorFlow 與 PyTorch 的兩個(gè)不重要的對(duì)比
1、在過去,PyTorch 和 TensorFlow 之間有著明顯的區(qū)別。PyTorch 使用了 eager execution 模式,TensorFlow 使用了 graph 模式,大家都在各自發(fā)展。但后來 TensorFlow 2 引入了eager execution作為默認(rèn)執(zhí)行模式,TensorFlow 變得有點(diǎn)像 PyTorch。現(xiàn)在 PyTorch 也引入了自己的graph 模式解決方案,變得有點(diǎn)像 TensorFlow。TensorFlow 與 PyTorch 的競(jìng)爭仍在繼續(xù),但兩者之間的差異正在慢慢消失。
2、人工智能開發(fā)是一個(gè)時(shí)髦的行業(yè)。但是流行的 AI 模型、模型架構(gòu)、學(xué)習(xí)算法、訓(xùn)練框架等隨時(shí)間變化發(fā)展的。就論文而言,幾年前我們處理的大部分模型都是用 TensorFlow 編寫的。但是人們經(jīng)常抱怨高級(jí) model.fit API 限制了他們的開發(fā)靈活性,并且graph 模式使他們無法調(diào)試。然后就有好多人轉(zhuǎn)向了PyTorch,他們說,“PyTorch可以以任何想要的方式構(gòu)建模型并輕松調(diào)試”。但是更靈活的的自定義操作會(huì)導(dǎo)致開發(fā)的復(fù)雜性,PyTorch Lightening等高級(jí)的API的出現(xiàn)就是復(fù)制了model.fit API的特性,然后同樣的人又說還有人說“我們必須適應(yīng) PyTorch Lightening,我們必須用 torch.compile 加速我們的訓(xùn)練”。既要靈活,又要簡單是不可能同時(shí)實(shí)現(xiàn)的。
正文開始
下面開始介紹關(guān)于如何使用PyTorch 2編譯API的技巧集合,以及一些你可能面臨的潛在問題。使模型適應(yīng)PyTorch的graph 模式可能需要付出不小的努力。希望這篇文章能幫助你更好地評(píng)估這一努力,并決定采取這一步的最佳方式。
安裝PyTorch2
從PyTorch安裝文檔來看,安裝PyTorch 2似乎與安裝任何其他PyTorch版本沒有什么不同,但是在實(shí)踐中,可能會(huì)遇到一些問題。首先,PyTorch 2.0(截至本文時(shí))需要Python 3.8或更高版本。然后就是PyTorch 2包含以前版本中不存在的包依賴項(xiàng)(最明顯的是PyTorch-triton,這是什么我也不知道,哈),需要注意可能會(huì)會(huì)引入新的沖突。
所以如果你對(duì)Docker熟悉,建議直接使用容器,這樣會(huì)簡單很多。
PyTorch2兼容性
PyTorch2的優(yōu)點(diǎn)之一是它完全向后兼容,所以我們即使不使用torch.compile,仍然可以使用PyTorch 2.0并從其他新功能和增強(qiáng)中受益。最多就是享受不到速度的提升,但是不會(huì)有兼容性的問題。但是如果你想進(jìn)一步提升速度,那么請(qǐng)往下看。
簡單例子
讓我們從一個(gè)簡單的圖像分類模型的例子開始。在下面的代碼塊中,我們使用timm Python包(版本0.6.12)構(gòu)建一個(gè)基本的Vision Transformer (ViT)模型,并在一個(gè)假數(shù)據(jù)集上訓(xùn)練它500步(不是輪次)。這里定義了use_compile標(biāo)志來控制是否執(zhí)行模型編譯(torch.compile),use_amp來控制是使用自動(dòng)混合精度(AMP)還是全精度(FP)運(yùn)行。
import time, os import torch from torch.utils.data import Dataset from timm.models.vision_transformer import VisionTransformer use_amp = True # toggle to enable/disable amp use_compile = True # toggle to use eager/graph execution mode # use a fake dataset (random data) class FakeDataset(Dataset): def __len__(self): return 1000000 def __getitem__(self, index): rand_image = torch.randn([3, 224, 224], dtype=torch.float32) label = torch.tensor(data=[index % 1000], dtype=torch.int64) return rand_image, label def train(): device = torch.cuda.current_device() dataset = FakeDataset() batch_size = 64 # define an image classification model with a ViT backbone model = VisionTransformer() if use_compile: model = torch.compile(model) model.to(device) optimizer = torch.optim.Adam(model.parameters()) data_loader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, num_workers=4) loss_function = torch.nn.CrossEntropyLoss() t0 = time.perf_counter() summ = 0 count = 0 for idx, (inputs, target) in enumerate(data_loader, start=1): inputs = inputs.to(device) targets = torch.squeeze(target.to(device), -1) optimizer.zero_grad() with torch.cuda.amp.autocast( enabled=use_amp, dtype=torch.bfloat16 ): outputs = model(inputs) loss = loss_function(outputs, targets) loss.backward() optimizer.step() batch_time = time.perf_counter() - t0 if idx > 10: # skip first few steps summ += batch_time count += 1 t0 = time.perf_counter() if idx > 500: break print(f'average step time: {summ/count}') if __name__ == '__main__': train()在下表記錄了比較性能結(jié)果。這些結(jié)果根據(jù)環(huán)境不同而有很大的變化,所以及供參考
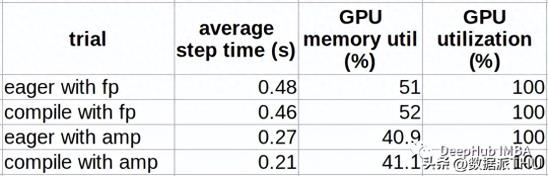
可以看到,使用AMP(28.6%)比使用FP(4.5%)時(shí),模型編譯帶來的性能提升要明顯得多。這是一個(gè)眾所周知的差異。如果你還沒有使用AMP進(jìn)行訓(xùn)練,那么其實(shí)對(duì)于訓(xùn)練速度的提升是從FP過渡到AMP,所以先推薦你使用AMP。另外就是性能提升伴隨著GPU內(nèi)存利用率的非常輕微的增加。
當(dāng)擴(kuò)展到多個(gè)gpu時(shí),由于在編譯圖上實(shí)現(xiàn)分布式訓(xùn)練的方式,比較性能可能會(huì)發(fā)生變化。具體細(xì)節(jié)看官方文檔。
/uploads/pic/20231010/fcmpxkwo2js data-track="50">
高級(jí)選項(xiàng)
compile API包含許多用于控制graph創(chuàng)建的選項(xiàng),能夠針對(duì)特定模型對(duì)編譯進(jìn)行微調(diào),并可能進(jìn)一步提高性能。下面的代碼塊是官方的函數(shù)介紹:
def compile(model: Optional[Callable] = None, *, fullgraph: builtins.bool = False, dynamic: builtins.bool = False, backend: Union[str, Callable] = "inductor", mode: Union[str, None] = None, options: Optional[Dict[str, Union[str, builtins.int, builtins.bool]]] = None, disable: builtins.bool = False) -> Callable: """ Optimizes given model/function using TorchDynamo and specified backend. Args: model (Callable): Module/function to optimize fullgraph (bool): Whether it is ok to break model into several subgraphs dynamic (bool): Use dynamic shape tracing backend (str or Callable): backend to be used mode (str): Can be either "default", "reduce-overhead" or "max-autotune" options (dict): A dictionary of options to pass to the backend. disable (bool): Turn torch.compile() into a no-op for testing """mode 編譯模式:允許您在最小化編譯所需的開銷(“reduce-overhead”)和最大化潛在的性能提升(“max-autotune”)之間進(jìn)行選擇。
下表比較了不同編譯模式下編譯上述ViT模型的結(jié)果。
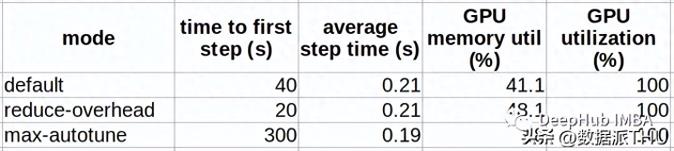
可以看到編譯模式的行為與命名的非常相似,“reduce-overhead”以額外的內(nèi)存利用為代價(jià)減少了編譯時(shí)間,“max-autotune”以高編譯時(shí)間開銷為代價(jià)獲得了最佳性能。
backend 編譯器后端:API使用哪個(gè)后端將中間表示(IR)計(jì)算圖(FX graph)轉(zhuǎn)換為低級(jí)內(nèi)核操作。這個(gè)選項(xiàng)對(duì)于調(diào)試graph編譯問題和更好地理解torch.compile的內(nèi)部非常有用。在大多數(shù)情況下,默認(rèn)的Inductor后端似乎能夠提供最佳的訓(xùn)練性能結(jié)果。有很多后端列表,我們可以使用下面命令查看:
from torch import _dynamo print(_dynamo.list_backends())我們測(cè)試使用nvprims-nvfuser后端,可以獲得比eager模式13%的性能提升(與默認(rèn)后端28.6%的性能提升相比)。具體區(qū)別還是要看Pytorch文檔,我們這里就不細(xì)說了,因?yàn)槲臋n都有。
fullgraph 強(qiáng)制單個(gè)圖:這個(gè)參數(shù)是非常有用,可以確保沒有任何不希望的圖截?cái)唷?/p>
dynamic 動(dòng)態(tài)形狀:目前 2.0對(duì)具有動(dòng)態(tài)形狀的張量的編譯支持在某種程度上是有限的。編譯具有動(dòng)態(tài)形狀的模型的一個(gè)常見解決方案是重新編譯,但會(huì)大大增加開銷并大大降低訓(xùn)練速度。如果您的模型確實(shí)包含動(dòng)態(tài)形狀,將動(dòng)態(tài)標(biāo)志設(shè)置為True將帶來更好的性能,特別是減少重新編譯的次數(shù)。
都有什么是動(dòng)態(tài)形狀呢,最簡單的就是時(shí)間序列或文本長度不同,如果不進(jìn)行對(duì)齊操作的話序列長度不同就是動(dòng)態(tài)的形狀。
性能分析
PyTorch Profiler是用來分析PyTorch模型性能的關(guān)鍵工具之一,可以評(píng)估和分析圖編譯優(yōu)化訓(xùn)練步驟的方式。在下面的代碼塊中,我們用profiler生成TensorBoard的結(jié)果,來查看訓(xùn)練的性能:
out_path = os.path.join(os.environ.get('SM_MODEL_DIR','/tmp'),'profile') from torch.profiler import profile, ProfilerActivity with profile( activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA], schedule=torch.profiler.schedule( wait=20, warmup=5, active=10, repeat=1), on_trace_ready=torch.profiler.tensorboard_trace_handler( dir_name=out_path) ) as p: for idx, (inputs, target) in enumerate(data_loader, start=1): inputs = inputs.to(device) targets = torch.squeeze(target.to(device), -1) optimizer.zero_grad() with torch.cuda.amp.autocast( enabled=use_amp, dtype=torch.bfloat16 ): outputs = model(inputs) loss = loss_function(outputs, targets) loss.backward() optimizer.step() p.step()下圖是從PyTorch Profiler生成的TensorBoard 中截取的。它提供了在上面編譯模型試驗(yàn)的訓(xùn)練步驟中在GPU上運(yùn)行的內(nèi)核的詳細(xì)信息。
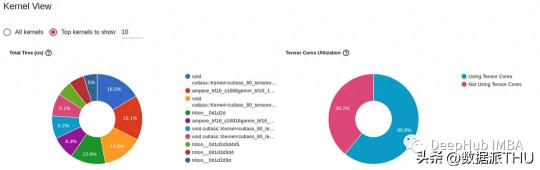
我們能夠看到torch.compile 增加了GPU張量核心的利用率(從51%到60%),并且它引入了使用Triton開發(fā)的GPU內(nèi)核。
調(diào)試模型編譯問題
torch.compile 目前處于測(cè)試階段,如果你遇到問題,并且幸運(yùn)的話,會(huì)得到一個(gè)信息錯(cuò)誤,我們可以直接搜索解決,或者問問chatgpt。但是如果你不那么幸運(yùn),就需要自己尋找問題的根源。
這里解決編譯問題的主要資源是 TorchDynamo 故障排除文檔,其中包括調(diào)試工具列表并提供診斷錯(cuò)誤的分步指南。但是目前這些工具和技術(shù)似乎更多地針對(duì) PyTorch 開發(fā)人員而不是 PyTorch 用戶的。它們也許可以幫助解決導(dǎo)致編譯問題的根本問題,但是非常大的可能是它們實(shí)際上跟本沒有任何幫助,那怎么辦呢?
這里我們演示一個(gè)自行解決問題的過程,按照這樣的思路,可以解決一些問題。
下面是一個(gè)簡單的分布式模型,其中包括對(duì) torch.distributed.all_reduce 的調(diào)用。模型在 eager 模式下按預(yù)期運(yùn)行,但在graph編譯期間失敗并出現(xiàn)“attribute error”(torch.classes.c10d.ProcessGroup does not have a field with name ‘shape’)。我們需要將日志級(jí)別提高到 INFO,然后發(fā)現(xiàn)發(fā)現(xiàn)錯(cuò)誤在計(jì)算的“第 3 步”中,即 TorchInductor。然后通過驗(yàn)證“eager”和“aot_eager”后端的編譯是否成功, 最后創(chuàng)建一個(gè)最小的代碼示例,使用 PyTorch Minifier 重現(xiàn)失敗。
import os, logging import torch from torch import _dynamo # enable debug prints torch._dynamo.config.log_level = logging.INFO torch._dynamo.config.verbose=True # uncomment to run minifier # torch._dynamo.config.repro_after="aot" def build_model(): import torch.nn as nn import torch.nn.functional as F class DumbNet(nn.Module): def __init__(self): super().__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.fc1 = nn.Linear(1176, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = torch.flatten(x, 1) x = self.fc1(x) with torch.no_grad(): sum_vals = torch.sum(x,0) # this is the problematic line of code torch.distributed.all_reduce(sum_vals) # add noise x = x + 0.1*sum_vals return x net = DumbNet() return net def train(): os.environ['MASTER_ADDR'] = os.environ.get('MASTER_ADDR', 'localhost') os.environ['MASTER_PORT'] = os.environ.get('MASTER_PORT', str(2222)) torch.distributed.init_process_group('nccl', rank=0, world_size=1) torch.cuda.set_device(0) device = torch.cuda.current_device() model = build_model() model = torch.compile(model) # replace with this to verfiy that error is not in TorchDynamo # model = torch.compile(model, 'eager') # replace with this to verfiy that error is not in AOTAutograd # model = torch.compile(model, 'aot_eager') model.to(device) rand_image = torch.randn([4, 3, 32, 32], dtype=torch.float32).to(device) model(rand_image) if __name__ == '__main__': train()在這個(gè)的示例中,運(yùn)行生成的 minifier_launcher.py 腳本會(huì)導(dǎo)致不同的屬性錯(cuò)誤(比如Repro’ object has no attribute ‘_tensor_constant0’),這個(gè)對(duì)于我們的演示沒有太大幫助,我們暫時(shí)忽略他,這也說明了,torch.compile 還不完善,還需要更大的改進(jìn)空間,或者說如果解決不要問題,那就別用了,至少“慢”要比不能用好,對(duì)吧(而且速度提升也有限)
常見的圖截?cái)鄦栴}
Pytorch eager 模式優(yōu)勢(shì)之一是能夠?qū)⒓?Pythonic 代碼與 PyTorch 操作交織在一起。但是這種自由在使用 torch.compile 時(shí)受到很大限制。因?yàn)?Pythonic 操作導(dǎo)致 TorchDynamo 將計(jì)算圖拆分為多個(gè)組件,從而阻礙了性能提升的潛力。而我們代碼優(yōu)化的目標(biāo)是盡可能減少此類圖截?cái)唷W詈唵蔚霓k法是用 fullgraph 標(biāo)志編譯模型。這楊可以提示刪除導(dǎo)致圖截?cái)嗟娜魏未a,而且還會(huì)告訴我們?nèi)绾巫詈玫剡m應(yīng)PyTorch2的開發(fā)習(xí)慣。但是要運(yùn)行分布式代碼,則必須將他設(shè)為False,因?yàn)楫?dāng)前實(shí)現(xiàn) GPU 之間通信的方式需要圖拆分。我們也可以使用 torch._dynamo.explain 序來分析圖截?cái)唷?/p>
以下代碼塊演示了一個(gè)簡單模型,在其前向傳遞中有四個(gè)潛在的圖截?cái)啵沁@種在使用方式在典型的 PyTorch 模型中并不少見。
import torch from torch import _dynamo import numpy as np def build_model(): import torch.nn as nn import torch.nn.functional as F class DumbNet(nn.Module): def __init__(self): super().__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.fc1 = nn.Linear(1176, 10) self.fc2 = nn.Linear(10, 10) self.fc3 = nn.Linear(10, 10) self.fc4 = nn.Linear(10, 10) self.d = {} def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = torch.flatten(x, 1) assert torch.all(x >= 0) # graph break x = self.fc1(x) self.d['fc1-out'] = x.sum().item() # graph break x = self.fc2(x) for k in np.arange(1): # graph break x = self.fc3(x) print(x) # graph break x = self.fc4(x) return x net = DumbNet() return net def train(): model = build_model() rand_image = torch.randn([4, 3, 32, 32], dtype=torch.float32) explanation = torch._dynamo.explain(model, rand_image) print(explanation) if __name__ == '__main__': train()圖截?cái)嗖粫?huì)導(dǎo)致編譯失敗(除非設(shè)置了fullgraph標(biāo)志)。所以很有可能模型正在編譯和運(yùn)行,但實(shí)際上包含多個(gè)圖截?cái)啵@會(huì)減慢它的速度。
訓(xùn)練問題故障排除
在目前來說,使用Pytorch2成功編譯的模型就可以認(rèn)為是一項(xiàng)值得慶祝的成就,但這并不能保證訓(xùn)練一定會(huì)成功。
在 GPU 上運(yùn)行的低級(jí)內(nèi)核在 eager 模式和graph模式之間會(huì)有所不同。某些高級(jí)操作可能會(huì)表現(xiàn)出不同的行為。你可能會(huì)發(fā)現(xiàn)在eager 模式下運(yùn)行的操作在graph 模式下會(huì)失敗(例如torch.argmin)。或者會(huì)發(fā)現(xiàn)計(jì)算中的數(shù)值差異會(huì)影響訓(xùn)練。
graph模式下的調(diào)試比 eager 模式下的調(diào)試?yán)щy得多。在 eager 模式下,每一行代碼都是獨(dú)立執(zhí)行的,我們可以在代碼中的任意點(diǎn)放置斷點(diǎn)獲得前張量值。而在graph 模式下,代碼定義的模型在處理之前會(huì)經(jīng)歷多次轉(zhuǎn)換,設(shè)置的斷點(diǎn)可能不會(huì)被觸發(fā)。
所以可以先使用eager 模式,模型跑通以后,再將torch.compile 分別應(yīng)用于每個(gè)部分,或者通過插入打印和/或 Tensor.numpy 調(diào)用來生成圖截?cái)啵@樣我們可能會(huì)會(huì)成功觸發(fā)代碼中的斷點(diǎn)。也就是說如果用torch.compile的話對(duì)于開發(fā)來說,要耗費(fèi)更長的時(shí)間,所以訓(xùn)練和開發(fā)速度的取舍就要看你自己的選擇了。
但是別忘了我們上面說的你的模型在添加了torch.compile后也不一定能正確運(yùn)行,這又是一個(gè)無形的成本。
在圖中包含損失函數(shù)
通過使用torch.compile調(diào)用包裝PyTorch模型(或函數(shù))來啟用graph模式。但是損失函數(shù)不是編譯調(diào)用的一部分,也不是生成圖的一部分。所以損失函數(shù)是訓(xùn)練步驟中相對(duì)較小的一部分,如果使用eager 模式運(yùn)行它不會(huì)產(chǎn)生太多開銷。但是如果有一個(gè)計(jì)算量他別大的損失函數(shù),也是可以通過將其包含在編譯的計(jì)算圖中來進(jìn)一步提高性能的。
在下面的代碼中,我們定義了一個(gè)損失函數(shù),用于執(zhí)行從大型ViT模型(具有24個(gè)ViT塊)到較小的ViT模型(具有12個(gè)ViT塊)的模型蒸餾。
import torch from timm.models.vision_transformer import VisionTransformer class ExpensiveLoss(torch.nn.Module): def __init__(self): super(ExpensiveLoss, self).__init__() self.expert_model = VisionTransformer(depth=24) if torch.cuda.is_available(): self.expert_model.to(torch.cuda.current_device()) self.mse_loss = torch.nn.MSELoss() def forward(self, input, outputs): expert_output = self.expert_model(input) return self.mse_loss(outputs, expert_output)這是一個(gè)比CrossEntropyLoss計(jì)算量大得多的損失函數(shù),這里又2種方法讓他執(zhí)行的更快,
1、loss函數(shù)封裝在torch.compile調(diào)用中,如下所示:
loss_function = ExpensiveLoss() compiled_loss = torch.compile(loss_function)這個(gè)方法的缺點(diǎn)是損失函數(shù)的編譯圖與模型的編譯圖不相交,但是它的優(yōu)點(diǎn)非常明顯,就是簡單。
2、創(chuàng)建一個(gè)包含模型和損失的包裝器模型來將模型和損失一起編譯,并將結(jié)果損失作為輸出返回。
import time, os import torch from torch.utils.data import Dataset from torch import nn from timm.models.vision_transformer import VisionTransformer # use a fake dataset (random data) class FakeDataset(Dataset): def __len__(self): return 1000000 def __getitem__(self, index): rand_image = torch.randn([3, 224, 224], dtype=torch.float32) label = torch.tensor(data=[index % 1000], dtype=torch.int64) return rand_image, label # create a wrapper model for the ViT model and loss class SuperModel(torch.nn.Module): def __init__(self): super(SuperModel, self).__init__() self.model = VisionTransformer() self.expert_model = VisionTransformer(depth=24 if torch.cuda.is_available() else 2) self.mse_loss = torch.nn.MSELoss() def forward(self, inputs): outputs = self.model(inputs) with torch.no_grad(): expert_output = self.expert_model(inputs) return self.mse_loss(outputs, expert_output) # a loss that simply passes through the model output class PassthroughLoss(nn.Module): def __call__(self, model_output): return model_output def train(): device = torch.cuda.current_device() dataset = FakeDataset() batch_size = 64 # create and compile the model model = SuperModel() model = torch.compile(model) model.to(device) optimizer = torch.optim.Adam(model.parameters()) data_loader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, num_workers=4) loss_function = PassthroughLoss() t0 = time.perf_counter() summ = 0 count = 0 for idx, (inputs, target) in enumerate(data_loader, start=1): inputs = inputs.to(device) targets = torch.squeeze(target.to(device), -1) optimizer.zero_grad() with torch.cuda.amp.autocast( enabled=True, dtype=torch.bfloat16 ): outputs = model(inputs) loss = loss_function(outputs) loss.backward() optimizer.step() batch_time = time.perf_counter() - t0 if idx > 10: # skip first few steps summ += batch_time count += 1 t0 = time.perf_counter() if idx > 500: break print(f'average step time: {summ/count}') if __name__ == '__main__': train()這種方法的缺點(diǎn)是,當(dāng)在推理模式下運(yùn)行模型時(shí),需要從包裝器模型中提取內(nèi)部的實(shí)際模型。
這兩種選項(xiàng)的性能提升幅度大致相同都是8%,也就是說,對(duì)loss進(jìn)行編譯也是優(yōu)化的一個(gè)重要部分。
動(dòng)態(tài)形狀
官方也說了torch.compile對(duì)動(dòng)態(tài)形狀的模型的編譯支持是有限的。compile API包含dynamic 參數(shù),用于向編譯器發(fā)出信號(hào),但是這種方式對(duì)于性能提升幫助的程度是值得懷疑的。如果你正在嘗試編譯和優(yōu)化動(dòng)態(tài)圖并面臨問題,那么還是不要使用torch.compile,因?yàn)樘闊┝恕?/p>
總結(jié)
PyTorch 2.0編譯模式具有顯著提高訓(xùn)練和推理速度的潛力,可以顯著節(jié)省成本,但是模型實(shí)現(xiàn)這一潛力所需的工作量可能會(huì)有很大差異。許多公共模型只需要修改一行代碼。而其他模型特別是那些包含非標(biāo)準(zhǔn)操作、動(dòng)態(tài)形狀和/或大量交錯(cuò)Python代碼的模型,可能得不償失甚至無法進(jìn)行。但是現(xiàn)在開始修改模型是一個(gè)很好的選擇,因?yàn)槟壳皝砜磘orch.compile對(duì)于PyTorch2來說是一個(gè)重要且持續(xù)的特性。
相關(guān)推薦



- 免責(zé)聲明
- 本文所包含的觀點(diǎn)僅代表作者個(gè)人看法,不代表新火種的觀點(diǎn)。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對(duì)本文可能提及或鏈接的任何項(xiàng)目不表示認(rèn)可。 交易和投資涉及高風(fēng)險(xiǎn),讀者在采取與本文內(nèi)容相關(guān)的任何行動(dòng)之前,請(qǐng)務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨(dú)立判斷。新火種不對(duì)因依賴本文觀點(diǎn)而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
