

 新火種
2024-12-30
新火種
2024-12-30 

奔騰2CPU+128MB內存成功運行Llama大模型:速度還挺快
12月30日消息,據媒體報道,EXO Labs最近發布了一段視頻,展示了在一臺26年歷史的Windows 98奔騰2 PC上運行大模型(LLM)。
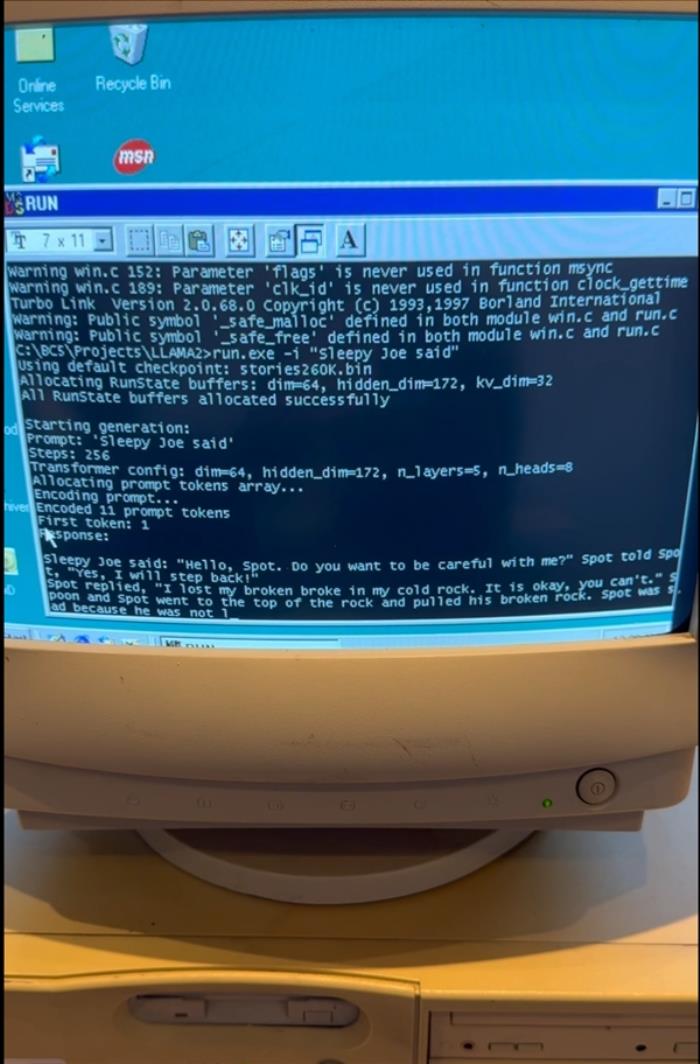
這臺主頻350MHz電腦成功啟動進入Windows 98系統,隨后EXO啟動了基于Andrej Karpathy的Llama2.c定制的純C推理引擎,并要求LLM生成關于“Sleepy Joe”的故事,令人驚訝的是生成速度相當可觀。

EXO Labs的這一壯舉并非偶然,該組織自稱為“民主化AI”而生,由牛津大學的研究人員和工程師組成,他們認為,少數大型企業控制AI對文化、真理和社會的其他基本方面是不利的。
因此,EXO希望建立開放的基礎設施,訓練前沿模型,并使任何人在任何地方都能運行它們,這項在Windows 98上的AI演示,展示了即使在資源極其有限的情況下也能完成的事情。
EXO Labs在文章中詳細描述了在Windows 98上運行Llama的過程,他們購買一臺舊的Windows 98 PC作為項目基礎,但面臨了許多挑戰。
將數據傳輸到老設備上就是一個不小的挑戰,他們不得不使用“老式的FTP”通過古老機器的以太網端口進行文件傳輸。
編譯現代代碼以適應Windows 98可能是一個更大的挑戰,EXO找到了Andrej Karpathy的llama2.c,可以總結為“700行純C代碼,可以運行Llama 2架構模型的推理”,Karpathy曾是特斯拉的AI主管,也是OpenAI的創始團隊成員。
利用這個資源和舊的Borland C++ 5.02 IDE和編譯器(以及一些輕微的調整),代碼可以被制作成Windows 98兼容的可執行文件并運行,GitHub上有完成代碼的鏈接。
使用260K LLM和Llama架構在Windows 98上實現了“35.9 tok/s”的速度,根據EXO的博客,升級到15M LLM后,生成速度略高于1 tok/s,Llama 3.2 1B的速度則慢得多,為0.0093 tok/s。
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
