

 新火種
2023-10-10
新火種
2023-10-10 


90后AI天才的大模型首戰
采訪|鄧詠儀 楊軒 陳紫冰
文|鄧詠儀
編輯|楊軒 蘇建勛
站在核爆中心圈,是一種什么樣的體驗?
在這次ChatGPT引發的AI大爆炸中,做了十年堪稱冷門的NLP(自然語言處理)的楊植麟,就處在這樣一個位置。這位保送清華、程序設計課程滿分的“少年天才”,在卡耐基梅隆大學讀博士時,就已經作為第一作者發表的關于Transformer-XL與XLNet的兩篇論文,成為本次AI大模型技術能夠突破的重要一環。
“先是非常激動,好像被蘋果砸中一樣,”楊植麟對36氪說,隨即又陷入沮喪,再想到可干的事情還很多,又“興奮起來”。

楊植麟
這也是他新創辦的第二家AI公司“月之暗面(Moonshot)”的由來。Moonshot這個名字,則來自英國著名搖滾樂隊Pink Floyd的專輯《Dark Side of the Moon》。
楊植麟認為,做大模型如同登月工程一樣,“月之暗面”意味著神秘,令人好奇和向往,同時又極具挑戰難度。
事實上,月之暗面的核心團隊曾參與到Google Gemini、Google Bard、盤古NLP、悟道等多個大模型的研發中——這是一支在“登月”道路上已探索多年的隊伍。而AI大模型,目前還在一個以技術能力定成敗的階段。
在這半年的國內大模型市場中,Moonshot顯得尤為沉默,但并不妨礙投資人的蜂擁而至。36氪最新獲得的消息是,月之暗面已經完成一輪超過2億美元的融資,目前身處中國大模型創業公司融資額第一梯隊。
成立半年多后,10月9日,Moonshot終于推出了首款大模型產品:智能助手Kimi Chat。這是Moonshot在大模型領域做To C超級應用的第一次嘗試。
來源:Moonshot
Kimi Chat支持輸入20萬漢字,是目前全球大模型產品中所能支持的最長上下文輸入長度。
這也代表著,Moonshot在長文本技術的探索突破到了一個新高度——對比當前市面上幾家主流模型,Kimi Chat的上下文長度是Claude 100k的2.5倍(實測約8萬字),GPT-4-32k的8倍(實測約2.5萬字)。
如今市面上的大模型產品繁多,拓展了上下文長度的Kimi Chat,在使用上有什么不同?
最明顯的是,你可以一次性給模型輸入大量的信息,由模型理解進行問答和信息處理,有效減少幻覺問題。
比如,公眾號的長文也可以交給Kimi Chat ,讓它幫你總結分析:

來源:Moonshot
發現了新的算法論文時,Kimi能夠直接幫你根據論文復現代碼:

來源:Moonshot
快要考試了,直接把一整本教材交給Kimi,就可以讓它陪你準備考試:
來源:Moonshot
甚至,也可以只用一個鏈接就讓它來扮演你喜愛的游戲角色,和你對話:

來源:Moonshot
目前,Moonshot AI 的智能助手產品Kimi Chat已開放了內測。訪問Moonshot.cn(或于文末掃描二維碼),即可加入內測計劃。
長文本:大模型落地的另一瓶頸值得關注的一點是,不同于其他大模型公司拼參數、展示各種各樣的行業案例,在Moonshot的發布會上,“長文本”成了絕對的主角。
“無論是文字、語音還是視頻,對海量數據的無損壓縮可以實現高程度的智能。而要有效提升大模型的性能,不僅要擴大模型參數,更要提升上下文長度,兩者同樣重要。”楊植麟表示。
大模型之所以能在智能水平有質的飛躍,是因為通過擴大參數規模,突破到了千億級別,才能夠讓智能“涌現”(Emergence,指模型自主產生出復雜行為或特性)。
但如今,大模型落地更重要的瓶頸不是模型大小,而是在于上下文不夠,文本長度不足會帶來對模型能力的嚴重束縛。
一個典型問題是,如果遇到多輪對話或者需要復雜步驟的場景,往往會出現模型記不住的情況——講了具體設定,但下一回合就忘記。比如,Character AI的用戶就經常吐槽模型記不住關鍵信息:
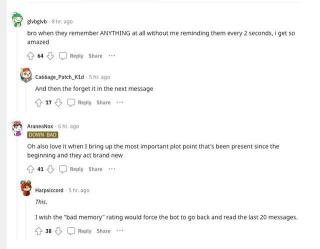
來源:公開網絡
這與計算機運行的原理類似:計算機依靠CPU進行計算;內存則存放了臨時計算的數據,決定其運行速度。“如果說參數量決定了大模型支持多復雜的‘計算’,而能夠接收多少文本輸入(即長文本技術)則決定了大模型有多大的‘內存’,兩者共同決定模型的應用效果。”他解釋道。
這也是Moonshot在保持模型擁有千億級參數的同時,首先將上下文長度先“拉滿”的原因。
要想做到拓寬上下文長度(Context),在模型訓練和推理側都存在算力+顯存的雙重挑戰。
比如,計算量會隨著上下文長度的增加呈平方級增長——比如上下文增加32倍時,計算量實際會增長1000倍;而在推理方面,即使是將單機顯存配置拉到目前的最高水平(如配備8張80GB顯存的GPU芯片),最多只能在千億級模型上處理約5萬漢字的長度。
但在Kimi Chat上,Moonshot團隊通過創新的網絡結構、改進算法策略等等,對模型訓練的各個環節進行了上百項的優化,從而在千億級參數下可以實現對超長文本的全文理解。
簡單而言,Moonshot AI并不通過當前滑動窗口、降采樣、小模型等對效果損害較大的“技術捷徑”來實現長文本,而是研發基于大模型的長程注意力,以實現真正可用的超長文本技術。
讓模型“記性”更好,會讓大模型未來的應用場景拓寬不少。比如,律師、分析師等職業,就能讓大模型分析長篇報告;像狼人殺這樣需要基于大量信息來推理的游戲,大模型也能夠勝任。
而在本次產品發布前,36氪曾與楊植麟進行過一次深談。作為站在這次技術核爆中心圈的人,楊植麟談起AI大模型,有種篤定感。他會不時用輕松的語氣,拋出一些讓人一愣的斷言。
比如,“Next token prediction(預測下一個字段)是唯一的問題。” “只要一條道走到黑,就能實現通用泛化的智能(AGI)。”
比如,“五年之內,大模型將持續保持較強的技術壁壘,不會commoditize(變成平價的、沒有壁壘的商品)。”
從LLM(大語言模型)到LLLM(長文本大語言模型),Kimi Chat只是Moonshot的第一步。不過,如今的Moonshot已經寄托著楊植麟一些很“黑鏡”的預想:在未來,如果機器能夠掌握一個人一生的信息,人們就會擁有自己的AI分身,這個AI分身共享了你的所有記憶,無異于另一個你。
以下為36氪與楊植麟的對話實錄,經36氪編輯整理:
時隔七年,兩次AI創業36氪:先來聊聊這次產品發布吧。很多大廠、創業公司都會選擇先發一個具體的大模型,開源或者閉源的都有。大模型已經火了半年后,Moonshot如今選擇先發一個To C的智能助手產品。為什么?
楊植麟:因為我始終堅信以終為始,只有當大模型被多數人使用時,才會涌現出最多的智能。Moonshot會秉承以應用為導向的模型開發,我們并不想只是發布一個模型,以迅速獲得科技圈可能的短期技術關注。比如,“長上下文”技術的價值,可能很難第一時間讓用戶感知到。但通過Kimi智能助手,就可以直接觸達用戶。我們希望讓技術成為用戶日常生活中一旦接觸就不可或缺的助手,以真實的反饋做來迭代模型,盡早地創造實際價值。
36氪:ChatGPT出來之后,這半年你的心情是怎么樣的?
楊植麟:這一年來,我是百感交集。如果是什么可控核聚變的突破,那其實跟我也沒什么關系,但這個事情(大語言模型)是我做了十年的事情,我覺得就好像是被蘋果砸中一樣。ChatGPT剛發的時候,我非常激動,我好奇這個世界到底能做什么樣的AI,我能多大程度去復制、甚至做得比人腦更好。同時,我也陷入到非常沮喪的狀態——因為這個事情也不是你做出來的對吧?我會開始想在這個浪潮里我還能貢獻什么,又開始興奮起來:現在是非常好的timing,不管發生什么,一定要做。
36氪:ChatGPT算是直接促使你創立新公司“月之暗面”?
楊植麟:對。從一開始的激動到沮喪,再決定創業之后,我逐漸恢復理性思考,思考想要什么樣的團隊來做,現在是技術演進過程里的什么階段,我們要做什么?然后再開始焦慮——鋪天蓋地地,所有人都說要做大模型,那大模型到底能不能做?是不是做不了?最后又會回到理性。我會去更長期地看這些個事情,短期內的大模型進展,東邊發一個模型,西邊發一個,其實都是噪音。
GPT-4的水平在這兒(高一截),其他模型都是在下面,其實大家現在說“我比你高”“你比我高”,沒什么意義。我這半年都在思考底層邏輯,最后發現這件事還是很適合我們來做。
36氪:適合在什么地方?
楊植麟:每一次技術突破里會有三層的機會。第一層機會,是被第一個找到第一性原則的人抓住,那就是OpenAI。這需要很強大的vision,非常高瞻遠矚,是靠經驗所支撐的。第二層機會就是在技術創新期,能解決一些技術方向性的問題——比如long context(長上下文)怎么做?能把技術做好的團隊可以抓住。第三層是純應用的機會,就是技術已經全部清楚了,不再需要考慮技術層面的事情,只做應用。
我們可以抓住的是第二層機會,在這個層面我們擁有很好的積累和優勢。
36氪:月之暗面想做的大模型,是怎么樣的?
楊植麟:我們希望先把模型能力做到世界領先水平,同時也會聚焦C端的超級應用,通過產品連接技術與用戶,從而共同創造通用智能,Kimi Chat只是我們的第一個產品嘗試。我們現在做的模型已經到千億級,未來會是一個多模態大模型,當前會先把語言模型做好。
36氪:在做應用上,你們大概思考的方向是怎么樣的?
楊植麟:我們還處在技術創新的階段,所以我們會先持續追求世界級的技術突破,比如長上下文、多模態等。而在產品層面,我們肯定是堅定在To C這一側,希望能做頭部的Super App。以ChatGPT和Character.ai為例,這兩個產品已經積累了大量的數據和用戶反饋,有大量的跡象證明已經通過這種的產品產生了新的入口,新一代AI在“有用“和”有趣“兩個方向上,都會有巨大潛力。我相信,無論是智能助手還是情感陪伴,我們都能通過技術為更多人解決工作和生活中的實際問題。
36氪:什么樣的是真需求?
楊植麟:比如Character.AI的情感更多元化,他其實底層滿足的是人的征服欲,我覺得征服是一個真正的剛需。AI最后不會是一個完全同質化的東西。它不像電,在新加坡充電和中國充電是一樣的。所以像Character.AI最后所實現智能可能比其他公司會更強,因為他們有數據能一直積累,后面可以做一些專業化,這也導致以后AI的毛利率會比以前的云計算要高。
36氪:好多大模型公司忙著在硅谷挖人,比如從OpenAI、Google、微軟。你是怎么組建起月之暗面的團隊的?
楊植麟:我們很多人還是重新招的。我們更多是找這種30歲左右,有很多一手實踐經驗的人。從去年12月開始,我就去了一趟海外,開始為招人做儲備了。
36氪:海外的AI人才愿意回來嗎?
楊植麟:我們在海外有office,其實兩邊還是可以相結合的。
36氪:現在月之暗面團隊有多少人?你預想中的團隊,會是什么樣子?
楊植麟:我們的團隊約60人,有很多技術專家,每個月都有在全球某個領域有顯著影響力的人加入,我們在努力打造大模型公司里產品人才密度最高的團隊。互聯網時代的技術和產品已經成熟分工,但我們希望產品團隊能更直接地參與模型優化,大幅縮短創新周期。智能時代無論技術、產品、增長還是商業化,都存在創新的機會。我們的愿景是建立一個全新的組織,能與用戶共情,也能用客觀數據來定義美和智能標準,將科技與人文融為一體。
36氪:OpenAI會是這種組織的理想狀態嗎?
楊植麟:我覺得他們提供了很多很好的實踐。比如他們就不搞賽馬,這是非常重要的例子。這并不是因為他們資源或者人不夠。他們資源挺多,但是會把資源放到一個統一的scope下面。比如,他們希望花10%的精力去探索一些新的東西,那會有一個團隊在做這個事情,主線永遠就只有這一個——這是非常重要的。并且,他們鼓勵底層創新,每個人貢獻想法。
36氪:現在不少人關注成本問題,這直接關系到工程化的成本,還有后續的商業化進展。現階段,你最關注的是什么因素?
楊植麟:就是能不能盡快找到PMF,這是第一優先級。
36氪:現在不少大廠、創業公司都在發開源模型,Moonshot有開源計劃嗎?你怎么思考這個問題?
楊植麟:我們目前沒有開源計劃。我認為,開源和閉源在整個生態里面會扮演不同的角色,開源很大一個作用是在To B端的獲客,如果想做頭部的Super App,大家肯定都是用閉源模型去做的,在開源模型上做C端應用很難做出差異化。
36氪:你從博士階段就已經開始創業,之前創立第一家AI公司“循環智能”的經驗,會給你什么啟發?
楊植麟:現在月之暗面還是處在第一階段,更重要的任務是降低不可預測性等偏技術上的工作,其實不會太受到外部因素的影響。但從大環境上來說,不可預測性肯定是要比之前更多了。幾年前的年景更好,可以順著市場做擴張,做營收;但市場不好時,反而是需要做成本控制、降低燒錢速度。這也是我從上一段創業經驗學到最多的。大模型很燒錢,把握好投入的速度,同時還要保證自己還是要拿出東西,有產品數據,是非常關鍵的問題。
預測下一個token是唯一問題36氪:AI領域有幾大方向:圖像識別(CV)、自然語言處理(NLP)、機器學習(ML)。前幾年CV更熱鬧,上一波AI四小龍(商湯、曠視、云從、依圖)都是這個方向。你一直在做NLP,為什么?
楊植麟:拋開偶然因素,還是有一些必然的原因。我覺得,Vision(視覺)方向其實更早地看到一些產業成果,但NLP可以去解決更多認知類的問題,讓AI真正實現價值。
36氪:NLP怎么讓AI真正發揮價值?
楊植麟:NLP相當于是從視覺的感知層面,進化到更有認知的層面。像Midjourney這種AI繪畫產品,它可能生成的圖片特別好看,但它本質是一個沒有大腦的畫家——你不知道中美關系怎么樣,不知道印第安人以前是怎么被奴役的。你需要知道這些歷史,才有可能成為一個頂級畫家。甚至最后不光只是畫畫,你還要做很多畫畫之外的事情。從這個點來說,NLP會解決更難的、更有挑戰性的問題,比如推理,它的存在會讓AI的版圖更加完整。
36氪:Transformer是你主攻的研究方向,它也是ChatGPT誕生的基礎。Transformer的革命性意義在什么地方?
楊植麟:我比較幸運的地方在于,我博士有一半時間是在2017年之后。因為2017年Transformer出來了,這是一個超級巨大的分水嶺。Transformer架構的出現讓整個NLP領域都發生了巨大的認知變化。有了這個東西之后,你就發現這里面可以做的東西實在太多了,突然一下子就給大家指明了方向。有很多之前完全無法實現的東西,它現在變得有可能了。
36氪:怎么理解這個“認知層面的變化”?
楊植麟:AI領域對語言模型的認知,存在三個階段的變化:
2017年前,大家覺得語言模型有一些有限的作用,比如在這些語音識別、排序、語法、拼寫等等小的場景里面可以做輔助,但用例(Use Case)都很小;第二個階段:Transformer、Bard出現后,語言模型可以做絕大部分的任務,但它還是一個輔助的角色——我有一個語言模型,AI工程師微調一下任務就好了;到第三階段,整個AI領域發展到最后,大家的認知會變成:所有東西其實都是語言模型,語言模型是唯一的問題,或者說是next token prediction(預測下一個字段)是唯一的問題。這個世界其實就是一個硬盤模型,當人類文明數字化之后,所有人類文明之和就是硬盤的總和。輸入的Token是語言,或者也可以是別的東西——只要能預測下一個Token是什么,那我就能實現了智能。從思想到系統的層面,其實技術發生了非常大的變化,這里面有很多變量。然后你就可以在這個空間里面去看,怎么把這些技術做的更好。
36氪:從2017年Transformer出現到今年ChatGPT爆火,中間還有五年的時間。這五年里,你的重要工作——有關Transformer-XLNet的論文,其實也有被拒稿過。中間有過對自己研究路線的懷疑嗎?
楊植麟:這個很有意思。當因為行業發生認知變化,而變化還沒有調整過來的時候,會存在非共識。部分人覺得非共識是錯的,但其實他實際上是對的。OpenAI在這里面絕對是一個先驅,因為他們最早有這種正確的非共識,最早看到“語言模型是唯一的問題”這一點。我們當時的研究效果非常好,能實現當時全世界最好的效果。但評審就問我們一個問題:就是說語言模型有什么用?你們好像沒有證明他有用。但是這個時候其實你要做的事情并不是說去尋求認同,而是說你要把真把那個事兒給做出來。
36氪:你說“唯一重要的問題就是預測下一個字段。”這個事兒在當時如果是非共識的話,你是怎么意識到這一點,并且堅信的?
楊植麟:坦白說,我在那個時候還沒有完全堅信這個事情,直到現在我覺得它也不一定是個共識,而是在逐漸變成共識的過程中。
36氪:什么叫“預測下一個字段”,應該要怎么理解?
楊植麟:本質上,做下一個token的預測,其實等價于“對整個世界的這個概率去進行建模”,就是現在給你任何一個東西,你都能給他估算一個概率。這個世界本來就是一個巨大的概率分布,里面有一些是不可建模的不確定性,你不知道下面會發生什么。但有一些是你能確定的,能排除掉一些東西的,這是一個通用的、對世界去進行建模的模型。有很多歷史學家來對這個事情做過研究,比如Density Estimation(密度統計),大模型本質是在做這樣一個事情。但當時我只意識到這是個重要的問題,而沒有意識到是唯一要解決的問題。
36氪:那是什么時候讓你改變主意了?
楊植麟:2020年GPT-3出來的時候,那個時候有了更明確的證據。OpenAI的人最厲害的點是,他們觀察到了更多的數據,再更早的時候真正去把模型參數、訓練規模擴大,所以他們更早地知道只要一直scale(擴大規模),就可能解決所有的問題。
36氪:知道它是如此重要之后,這會怎么影響你的技術路線?
楊植麟:回到剛剛那一點,如果這個世界只有一個問題:要預測下一個字段,那么輸入和輸出其實是一樣的——也就是“理解”和“生成”其實也是同一個問題。幾年前,我們自己也會區分,到底是要做理解模型還是生成模型,但現在不需要了。
36氪:不過,現在有很多團隊的技術路線,可能會先做文字理解,在理解這一端做得更多些,生成可能會靠后一點。
楊植麟:這些思考方向不夠本質。現在任何說“只能做理解而非生成”都是錯誤的方向。正確的方向應該是:理解和生成就是一個問題。如果能做很好的理解,那能做很好的生成,這兩個應該是完全等價的。
36氪:相當于這兩者無法分開來。
楊植麟:對的。現在就只有一個問題。比如說我能夠去生成接下來10秒鐘的視頻,我那我必須對之前的這個視頻有很好的理解,你得知道他發生了什么,這是一個什么樣的story,接下來很有可能是什么樣的演進,它是分不開的。
36氪:你對實現AGI(通用泛化的智能)有信心嗎?
楊植麟:有沒有信心取決于它的第一性原理,我覺得大家現在已經明白原理了,只有一個問題:就是預測下一個字段。一條道走到黑的話,我覺得就能實現。但確實還存在一些“第二層面”問題,也就是具體的技術方向難題。但是這些都是小問題,并非原則性的,第二個層面就是我們要去攻克的。
人的一生不過是大量的信息36氪:用一句簡短的話來描述月之暗面的目標跟遠景,你會怎么說?
楊植麟:長期的幾個目標是:探索智能的極限、讓AI有用,以及讓每個人都能擁有真正普惠的AI。
36氪:“普惠的AI”怎么理解?
楊植麟:現在的一個問題是,很多時候AI的價值觀是被一個處于中心的機構控制。一個模型表現成什么樣子,完全是由平臺來決定——TA覺得什么是“好的”,什么是價值觀正確的答案。但每個人會有自己的價值觀。價值觀是更底層的東西,它其實還包含很多可能——你的偏好,也就是你認為什么是對的,什么是錯的。每個人都應該要有這種個性化定制的機會,所以以后的AI也應該要擁有“對齊”的機會。(Alignment,指確保AI系統的行為匹配預期的人類價值觀和目標的過程)。
當然,我們肯定要去設置安全底線,以及監管層面的東西。在這個基礎上,可以有很多個性化AI的機會。
36氪:個性化的AI,它的實現路徑是什么?每個人都能訓練一個代表自己的AI模型嗎?
楊植麟:你剛說的訓練是一種方式,但我認為可能后面也許不需要去訓練,也許直接設置就可以了。最終的一個可能形態是,AI會數字化的所有東西全部記錄下來,你的手機、電腦上會有一個和你共生的AI Agent(AI代理、AI分身),它會知道所有一切你能知道的東西。
36氪:你在你的個人主頁上寫,你的所有的工作目標都是“讓AI價值最大化”。這指的是什么?
楊植麟:最大的價值就是,最終每個人不用做自己不想做的事情,保留人性里面最精華的部分。比如,我們這次談話也可以不用面對面,而是有更高效的方式——比如由我們的AI Agent直接對話。在公司也是一樣,現在的組織要花時間去定績效、考核。其實這都會非常花時間。以后我們也許就不需要公司了,一個人的效率會高很多,也不用為了賺一點錢就非得要去上班,可以用AI來做很多工作。要達到這樣的效果肯定很難,但最終人類有可能實現生產最大化。最后,也許真正的共產主義會出現。
36氪:如果讓你現在對未來做一個預測的話,你覺得十年之后我們這個社會會有什么樣的變化?或者說AI對這個社會最大的變革,你覺得會來自什么方面?
楊植麟:十年有點難,五年可以說一說。我覺得至少五年內大模型技術不會commoditize(指技術還會有壁壘,不會變成廉價的商品)。因為至少還有一大批模型沒有出來,我們還沒有真正看到視頻大模型。我覺得這兩年可能是文本模型持續迭代的窗口。后再過三年,是視頻模型持續迭代的窗口,這里始終是有技術壁壘的。
36氪:所以,視頻大模型會是關鍵性的節點?
楊植麟:對的,這些節點都邁過后,會出現一個巨大的變革。美國有一個公司叫Rewind(主打“記錄一切”,讓人類搜索一切在上看見過的所有內容),現在的產品能實現的效果,可能只是能問它:我上個月做了什么?它會記錄下來,現在的效果還是比較淺層的。以后的AI Agent會更加深度地實現個性化。比如,大模型會和你有共享的記憶,知道你所有的價值偏好,所有的價值取向。如果你讓他寫一個Q3的規劃,他會基于已知的這些東西直接去寫規劃,而不需要知道Q2做了什么東西。
36氪:從文字到圖片,再到視頻大模型、Agent,要實現的關鍵是什么?
楊植麟:是context(上下文長度,也可以理解為模型單次能處理的信息量),這基本決定了AI能產生價值的上限。如果大模型的context就是你的全部記憶,理論上,那它就可以做你現在做的全部事情。對于大模型來說,最關鍵的一點就是,你到底能有多少context被捕捉到。這取決于視頻模型的能力,如果模型能力很強,理論上你的手機和電腦加起來就差不多是你完整的context。人的一生也不過是如此,我們每天就活在數字世界里面。可能除了我們現在這種線下對話,他可能捕捉不到,其他大部分都是都ok的。
36氪:如果真的達到這種狀態,人類應該要怎么和機器共存?
楊植麟:我自己是比較樂觀,就是說他在提供更多生產力的同時,他應該會創造很多新的崗位。視頻現在是大家花時間最多的地方,所以他肯定會對生產關系產生很大的影響。所以每個人可能都可以生產(視頻),很多價值會被重新分配。但這是一個反饋閉環時間比較長的事情。挑戰在于,當前替代現有崗位的速度比創造新崗位的速度更快。核心問題在于,在理想的崗位沒有被創造出來之前,我們如何解決一些社會問題。
36氪:普通人怎么去面對這次技術變革?這種變化繼續下去,普通人應該做點什么?
楊植麟:我覺得最重要還是學習。不光是普通人,我覺得所有人,擁有最強終身學習的能力的人,以后才能夠實現自己真正的價值。另外一點是要open minded。我四五年就找過很多人說,要不要來一起做大模型,當時他們說我現在要做數字人,你不要跟我講這些東西(笑)。所以人確實有時候還是會被自己認知所局限。無論我們對技術的態度如何,歷史的發展都是超出個人意志的。因此,我們要不斷的自我迭代,適應這個世界唯一不變的,就是變化本身。
掃碼加入Kimi Chat內測:

或直接訪問moonshot.cn

歡迎交流

歡迎關注
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
