

 新火種
2023-10-06
新火種
2023-10-06 

景聯文數據標注:ChatGPT成功的秘密——人類反饋強化學習(RLHF)
ChatGPT的成功很大程度上歸功于其采用的新的訓練范式——人類反饋強化學習(RLHF)。RLHF是一種強化學習方法,它將強化學習與人類反饋相結合,通過利用人類提供的反饋來指導智能系統的行為,使其能夠更加高效、快速地學習任務。
在ChatGPT的訓練中,人類反饋被納入模型的學習過程中。ChatGPT首先通過大規模的文本數據集進行預訓練,然后通過與人類的交互進行微調。在這個過程中,人類用戶的反饋被用來優化模型的輸出,使得模型能夠更好地理解人類意圖,并生成更符合人類預期的文本。
這種訓練范式的采用,使得ChatGPT在處理自然語言任務時表現得更為出色,如對話生成、文本摘要、語義理解等。同時,由于它可以學習人類的偏好和習慣,ChatGPT生成的文本也更符合人類的語言習慣和邏輯。

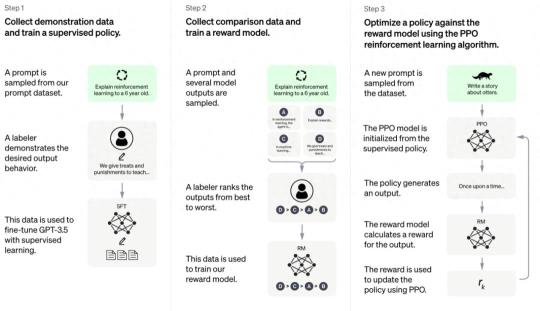
RLHF的訓練過程可以分解為以下三個核心步驟:
Step1:預訓練語言模型
此階段中,模型使用常規的監督學習方法,從大量有標簽的數據中學習。這一階段的目標是讓模型能夠盡可能準確地理解和生成文本。
Step2:收集數據并訓練獎勵模型
在這一階段,模型會生成一些文本,然后從人類那里獲得反饋。這些反饋可以是關于文本的某些特定屬性的評級,或者是對文本的修改建議。這個階段的目的是讓模型逐漸學會生成符合人類期望和要求的文本。
Step3:利用強化學習微調語言模型
模型使用強化學習算法來優化其生成文本的方式。這一階段中,模型會不斷地生成文本,并從人類提供者那里獲得反饋(這被稱為獎勵)。模型的目標是最大化從這些獎勵中獲得的總回報。這一階段的目標是讓模型能夠根據人類提供者的反饋和獎勵來調整其生成文本的方式,從而盡可能地提高其生成文本的質量。
如何優化RLHF?
RLHF主要通過以下兩種方式進行優化迭代:
迭代優化策略:RLHF采用迭代優化策略來提高大模型的性能。它首先使用預訓練模型進行初始化,然后反復迭代訓練和微調過程。在每次迭代中,它使用微調后的模型來生成新的標簽,并使用這些新的標簽來更新模型的權重。這個過程不斷重復,直到模型性能達到滿意的水平。
上下文信息:RLHF通過利用上下文信息來優化大模型的性能。它通過引入上下文信息來增強模型的表達能力和泛化能力。具體來說,它可以使用外部知識庫或上下文信息來豐富輸入數據,例如,在文本分類任務中,它可以整合文章之外的背景知識來提高模型對文本的理解能力。
數據是AI大模型的關鍵因素之一,它決定了模型的準確性、健壯性、創造性和公平性。因此,在AI領域,擁有高質量、大規模的數據集是推動AI大模型發展并取得成功的關鍵因素之一。
景聯文標注平臺支持GPT相關標注業務,具備成熟的標注、審核、質檢機制,完全能夠滿足針對大型語言模型訓練的標注需求 。
景聯文科技研究人員利用GPT模型進行半自動化的數據采集和標注,用工具進行預先標注,準確率可達97%,再由人工干預進入修改,提高標注效率,以減輕人工標注者處理復雜結構化數據所需的時間和專業知識負擔,用最快的速度交付高質量數據。
景聯文科技提供的產品為全鏈條AI數據服務,從數據采集、清洗、標注、到駐場的全流程、垂直領域數據解決方案一站式AI數據服務,滿足了不用應用場景下的各類數據采集標注業務的需要,協助人工智能企業解決整個人工智能鏈條中數據采集標注環節的相對應問題,推動人工智能在更多地場景下實現落地應用,構建完整的AI數據生態。

景聯文科技|數據采集|數據標注
助力人工智能技術,賦能傳統產業智能化轉型升級
文章圖文著作權歸景聯文科技所有,商業轉載請聯系景聯文科技獲得授權,非商業轉載請注明出處。
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
