

 新火種
2024-11-16
新火種
2024-11-16 

比A100性價比更高!FlightLLM讓大模型推理不再為性能和成本同時發愁
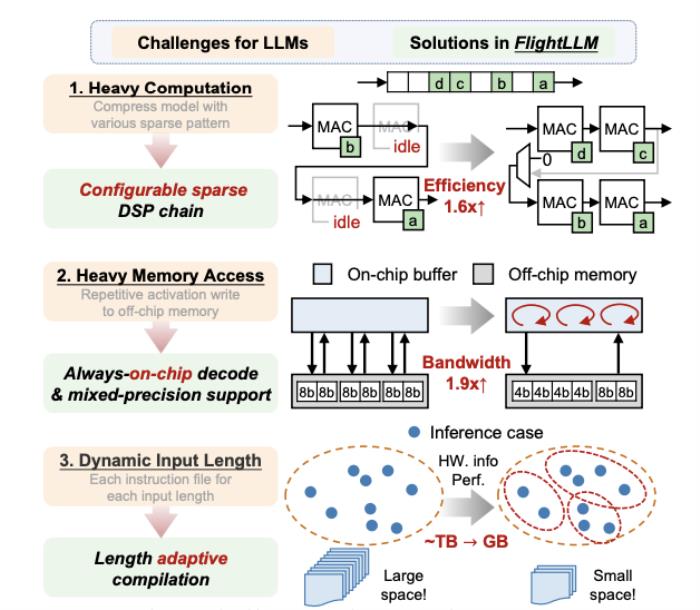
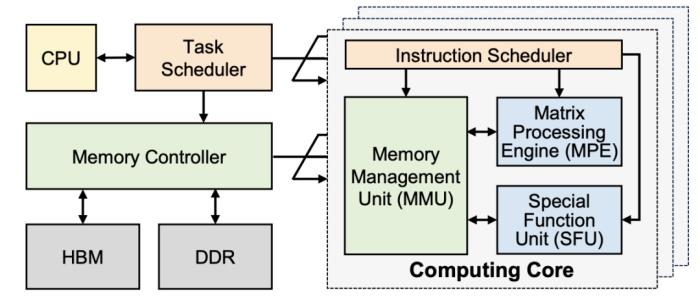
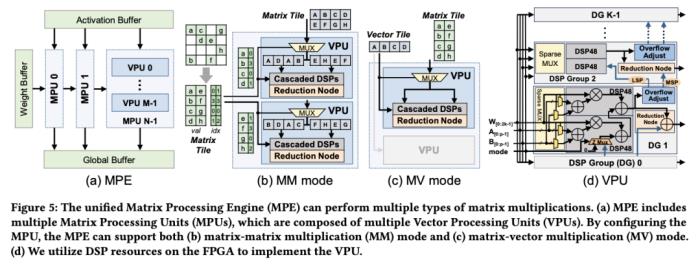
大語言模型在端側的規模化應用對計算性能、能效比需求的“提拽式”牽引,在算法與芯片之間,撕開了一道充分的推理競爭場。面對想象中的終端場景,基于 GPU 和 FPGA 的推理方案的應用潛力需要被重新審視。近日,無問芯穹、清華大學和上海交通大學聯合提出了一種面向 FPGA 的大模型輕量化部署流程,首次在單塊 Xilinx U280 FPGA 上實現了 LLaMA2-7B 的高效推理。第一作者為清華大學電子系博士及無問芯穹硬件負責人曾書霖,通訊作者為上海交通大學副教授、無問芯穹聯合創始人兼首席科學家戴國浩,清華大學電子工程系教授、系主任及無問芯穹發起人汪玉。相關工作現已被可重構計算領域頂級會議 FPGA’24 接收。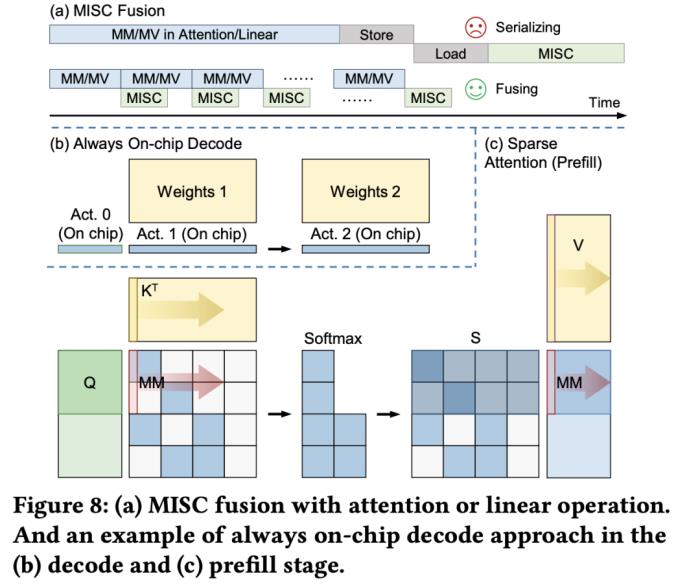 (a)大模型推理階段的注意力層/線性層與非線性激活操作(MISC)的算子融合實現;全片上解碼在(b)預取(Prefill)階段和(c)解碼(Decode)階段的示意圖:利用算子融合和FPGA的高片上存儲,使得大模型推理解碼階段的激活值無須寫到片外。為了減少激活向量的片外存儲器訪問,解決訪存帶寬利用率低的挑戰,FlightLLM 使用了算子融合技術,將解碼階段每次推斷中的計算進行融合,提出了 always-on-chip decode 的數據流。通過混合精度量化和算子融合的設計,將 decode 階段的激活值最大程度在片上緩存中復用。最后,由于大模型每次推理過程 token 長度都會增加,因此需要不同的指令。而大模型有大量計算和存儲需求,即使使用粗粒度指令,指令數量仍然非常龐大。
(a)大模型推理階段的注意力層/線性層與非線性激活操作(MISC)的算子融合實現;全片上解碼在(b)預取(Prefill)階段和(c)解碼(Decode)階段的示意圖:利用算子融合和FPGA的高片上存儲,使得大模型推理解碼階段的激活值無須寫到片外。為了減少激活向量的片外存儲器訪問,解決訪存帶寬利用率低的挑戰,FlightLLM 使用了算子融合技術,將解碼階段每次推斷中的計算進行融合,提出了 always-on-chip decode 的數據流。通過混合精度量化和算子融合的設計,將 decode 階段的激活值最大程度在片上緩存中復用。最后,由于大模型每次推理過程 token 長度都會增加,因此需要不同的指令。而大模型有大量計算和存儲需求,即使使用粗粒度指令,指令數量仍然非常龐大。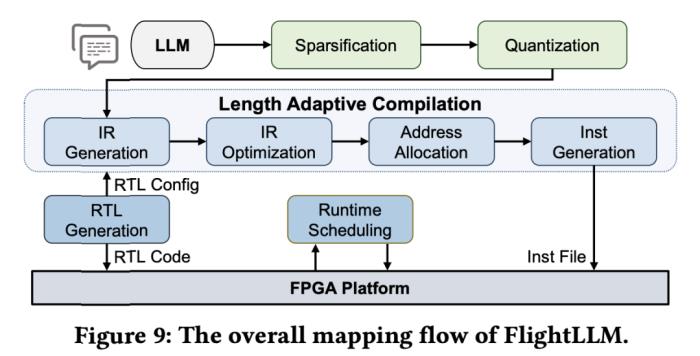 通過在不同輸入 token 長度下推理性能的測量,作者觀察到 prefill 和 decode 的延時和輸入 token 長度之間的關系存在著 「階梯」增長的特征,并且 prefill 階段延時隨輸入 token 長度增加得更快。這是因為 prefill 階段是計算瓶頸,計算量隨 token 長度顯著增加;而 decode 階段是訪存瓶頸,因此延時增加不明顯。階梯狀增長的原因則主要是粗粒度指令集。由于矩陣 - 矩陣乘指令的輸出并行度是 128,矩陣 - 向量乘的輸出并行度是 16,因此 prefill 和 decode 的 「階梯」的寬度分別為 128 和 16。基于這些發現,FlightLLM 提出了一種 token 長度自適應的編譯方法,通過復用 prefill 階段和 decode 階段的指令來減少編譯指令的存儲開銷,進而對每個 「階梯」輸入 token 長度的指令分組,以 「階梯」 寬度復用指令序列。這種設計顯著減少了指令的總存儲開銷。目前,作者已在 Xilinx Alveo U280 FPGA(16nm)上實現了 FlightLLM。在 OPT-6.7B 和 LLaMA2-7B 上的實驗結果表明,FlightLLM 的端到端延遲優于 NVIDIA V100S GPU。
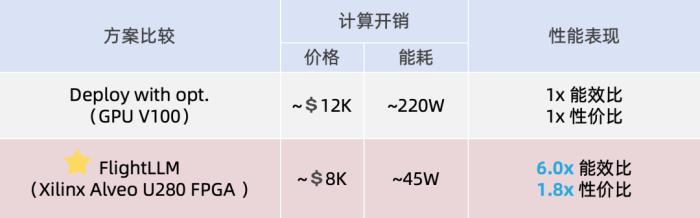
通過在不同輸入 token 長度下推理性能的測量,作者觀察到 prefill 和 decode 的延時和輸入 token 長度之間的關系存在著 「階梯」增長的特征,并且 prefill 階段延時隨輸入 token 長度增加得更快。這是因為 prefill 階段是計算瓶頸,計算量隨 token 長度顯著增加;而 decode 階段是訪存瓶頸,因此延時增加不明顯。階梯狀增長的原因則主要是粗粒度指令集。由于矩陣 - 矩陣乘指令的輸出并行度是 128,矩陣 - 向量乘的輸出并行度是 16,因此 prefill 和 decode 的 「階梯」的寬度分別為 128 和 16。基于這些發現,FlightLLM 提出了一種 token 長度自適應的編譯方法,通過復用 prefill 階段和 decode 階段的指令來減少編譯指令的存儲開銷,進而對每個 「階梯」輸入 token 長度的指令分組,以 「階梯」 寬度復用指令序列。這種設計顯著減少了指令的總存儲開銷。目前,作者已在 Xilinx Alveo U280 FPGA(16nm)上實現了 FlightLLM。在 OPT-6.7B 和 LLaMA2-7B 上的實驗結果表明,FlightLLM 的端到端延遲優于 NVIDIA V100S GPU。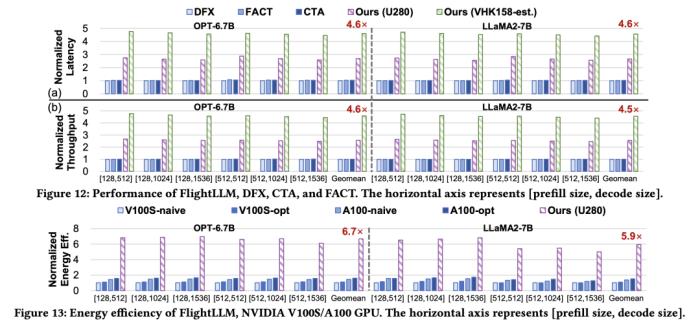 此外,FlightLLM(基于 U280 FPGA 和 VHK158 FPGA)在能效上超過了 NVIDIA V100S 和 A100 GPU,分別提高了 6.0× 和 4.2×,在性價比上提高了 1.8× 和 1.5×。更多詳細細節,請參閱論文原文。
此外,FlightLLM(基于 U280 FPGA 和 VHK158 FPGA)在能效上超過了 NVIDIA V100S 和 A100 GPU,分別提高了 6.0× 和 4.2×,在性價比上提高了 1.8× 和 1.5×。更多詳細細節,請參閱論文原文。

(a)大模型推理階段的注意力層/線性層與非線性激活操作(MISC)的算子融合實現;全片上解碼在(b)預取(Prefill)階段和(c)解碼(Decode)階段的示意圖:利用算子融合和FPGA的高片上存儲,使得大模型推理解碼階段的激活值無須寫到片外。為了減少激活向量的片外存儲器訪問,解決訪存帶寬利用率低的挑戰,FlightLLM 使用了算子融合技術,將解碼階段每次推斷中的計算進行融合,提出了 always-on-chip decode 的數據流。通過混合精度量化和算子融合的設計,將 decode 階段的激活值最大程度在片上緩存中復用。最后,由于大模型每次推理過程 token 長度都會增加,因此需要不同的指令。而大模型有大量計算和存儲需求,即使使用粗粒度指令,指令數量仍然非常龐大。通過在不同輸入 token 長度下推理性能的測量,作者觀察到 prefill 和 decode 的延時和輸入 token 長度之間的關系存在著 「階梯」增長的特征,并且 prefill 階段延時隨輸入 token 長度增加得更快。這是因為 prefill 階段是計算瓶頸,計算量隨 token 長度顯著增加;而 decode 階段是訪存瓶頸,因此延時增加不明顯。階梯狀增長的原因則主要是粗粒度指令集。由于矩陣 - 矩陣乘指令的輸出并行度是 128,矩陣 - 向量乘的輸出并行度是 16,因此 prefill 和 decode 的 「階梯」的寬度分別為 128 和 16。基于這些發現,FlightLLM 提出了一種 token 長度自適應的編譯方法,通過復用 prefill 階段和 decode 階段的指令來減少編譯指令的存儲開銷,進而對每個 「階梯」輸入 token 長度的指令分組,以 「階梯」 寬度復用指令序列。這種設計顯著減少了指令的總存儲開銷。目前,作者已在 Xilinx Alveo U280 FPGA(16nm)上實現了 FlightLLM。在 OPT-6.7B 和 LLaMA2-7B 上的實驗結果表明,FlightLLM 的端到端延遲優于 NVIDIA V100S GPU。此外,FlightLLM(基于 U280 FPGA 和 VHK158 FPGA)在能效上超過了 NVIDIA V100S 和 A100 GPU,分別提高了 6.0× 和 4.2×,在性價比上提高了 1.8× 和 1.5×。更多詳細細節,請參閱論文原文。 相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
