

 新火種
2024-11-16
新火種
2024-11-16 


mini-GPT4o來了?能看、能聽、會說,還情感豐富的多模態全能助手EMOVA
本文作者來自香港科技大學、香港大學和華為諾亞方舟實驗室等機構。其中第一作者陳鎧、茍耘豪、劉智立為香港科技大學在讀博士生,黃潤輝為香港大學在讀博士生,譚達新為諾亞方舟實驗室研究員。
隨著 OpenAI GPT-4o 的發布,大語言模型已經不再局限于文本處理,而是向著全模態智能助手的方向發展。這篇論文提出了 EMOVA(EMotionally Omni-present Voice Assistant),一個能夠同時處理圖像、文本和語音模態,能看、能聽、會說的多模態全能助手,并通過情感控制,擁有更加人性化的交流能力。以下,我們將深入了解 EMOVA 的研究背景、模型架構和實驗效果。
論文題目:EMOVA: Empowering Language Models to See, Hear and Speak with Vivid Emotion
論文地址:
項目網頁:
研究背景:全模態交互的挑戰
近年來,多模態大模型得到廣泛關注,尤其是可以同時處理視覺和語言信息的模型,如 LLaVA [1] 和 Intern-VL [2],或者語音文本交互的模型,如 Mini-Omni [3]。然而,當前的研究多偏向于雙模態組合,要讓大語言模型在 “看、聽、說” 三個方面同時具備優越表現依然充滿挑戰。傳統的解決方案往往依賴外部語音生成工具,無法實現真正的端到端語音對話。而 EMOVA 的出現填補了這個空白,在保持圖文理解性能不下降的前提下,讓模型具備情感豐富的語音交流能力,實現了一個全能型、情感豐富、能看能聽會說的智能助手。
模型架構:情感對話與多模態理解的有效結合
EMOVA 的架構如圖一所示,它結合了連續的視覺編碼器和離散的語音分詞器,能夠將輸入的圖像、文本和語音信息進行高效處理,并端到端生成文本和帶情感的語音輸出。以下是其架構的幾個關鍵點:
1. 視覺編碼器:采用連續的視覺編碼器,捕捉圖像的精細視覺特征,保證領先的視覺語言理解性能;
2. 語音分詞器:采用了語義聲學分離的語音分詞器,將輸入的語音分解為語義內容(語音所表達的意思)和聲學風格(語音的情感、音調等)。這種設計將語音輸入轉化為 “新的語言”,不僅降低了語音模態的合入難度,更為后續個性化語音生成以及情感注入提供了靈活度;
3. 情感控制模塊:引入了一個輕量級的風格模塊,支持對語音情感(如開心、悲傷等)、說話人特征(如性別)、語速、音調的控制,在保持語義不變的情況下,根據對話上下文動態調節語音輸出的風格,使人機交互更加自然。
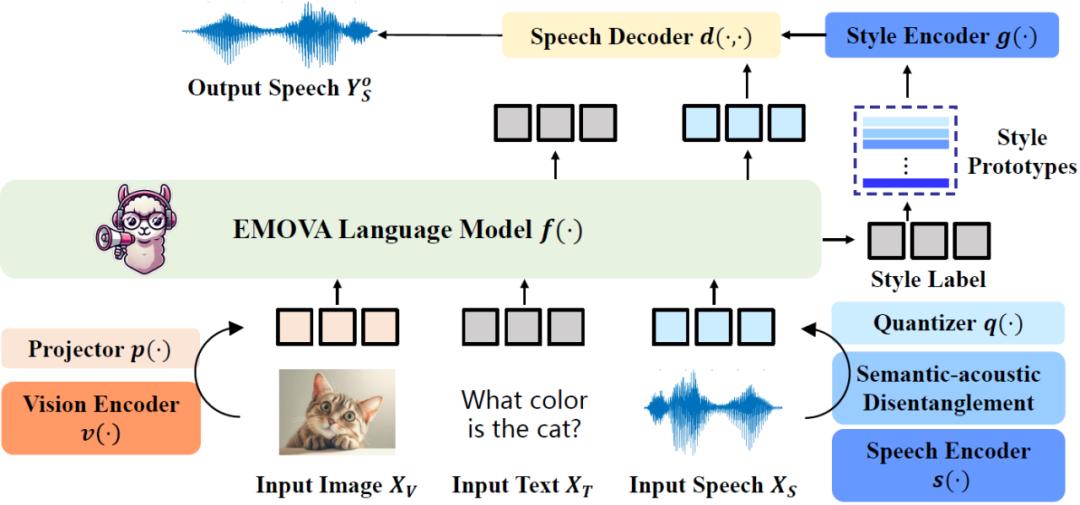
圖一:EMOVA 模型架構
對齊方法:開源雙模態數據實現全模態對齊
EMOVA 提出了數據高效的全模態對齊,以文本模態作為媒介,通過公開可用的圖像文本和語音文本數據進行全模態訓練,而不依賴稀缺的圖像 - 文本 - 語音三模態數據。實驗發現:
1. 模態間的相互促進:在解耦語義和聲學特征的基礎上,語音文本數據和圖像文本不僅不會相互沖突,反而能夠互相促進,同時提升模型在視覺語言和語音語言任務中的表現;
2. 同時對齊優于順序對齊:聯合對齊圖像文本和語音文本數據的效果明顯優于順序對齊(先圖像文本對齊,再語音文本對齊,或反之),有效避免 “災難性遺忘”;
3. 全模態能力激發:少量多樣化的全模態指令微調數據,可以有效激發模型面對圖像、文本和語音組合指令的響應能力和遵從性。
這種雙模態對齊方法利用了文本作為橋梁,避免了全模態圖文音訓練數據的匱乏問題,并通過聯合優化,進一步增強了模型的跨模態能力。
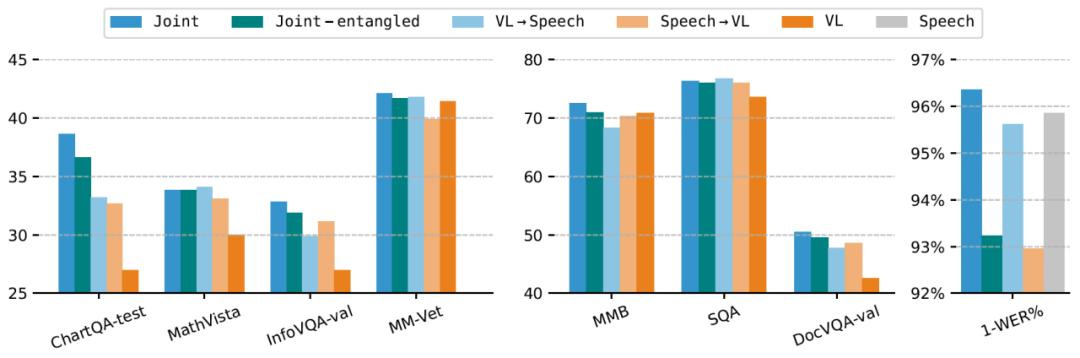
圖二:全模態同時對齊提升模型在視覺語言和語音語言任務中的表現
實驗效果:性能領先,情感豐富
在多個圖像文本、語音文本的基準測試中,EMOVA 展現了優越的性能:
1. 視覺理解任務:EMOVA 在多個數據集上達到了當前的最佳水平,特別是在復雜的圖像理解任務中表現尤為突出,如在 SEED-Image、OCR Bench 等榜單的性能甚至超過了 GPT-4o;
2. 語音任務:EMOVA 不僅在語音識別任務上取得最佳性能,還能生成情感豐富、自然流暢的語音,展示了其語義聲學分離技術和情感控制模塊的有效性;
總的來說,EMOVA 是首個能夠在保持視覺文本和語音文本性能領先的同時,支持帶有情感的語音對話的模型。這使得它不僅可以在多模態理解場景表現出色,還能夠根據用戶的需求調整情感風格,提升交互體驗。
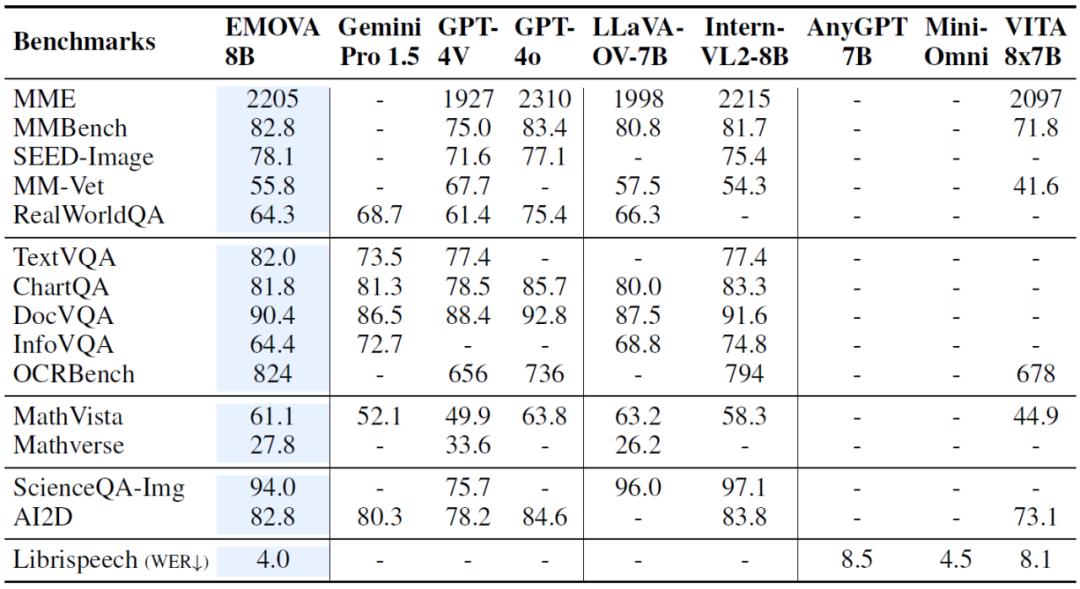
圖 3 EMOVA 在視覺文本和語音文本任務上的性能測試
總結:提供 AI 情感交互的新思路
EMOVA 作為一個全模態的情感語音助手,實現了端到端的語音、圖像、文本處理,并通過創新的語義聲學分離和輕量化的情感控制模塊,展現出優越的性能。無論是在實際應用還是研究前沿,EMOVA 都展現出了巨大的潛力,為未來 AI 具備更加人性化的情感表達提供的新的實現思路。
參考文獻:
[1] Liu, H., Li, C., Wu, Q., & Lee, Y. J. (2024). Visual instruction tuning. In NeurIPS.
[2] Chen, Z., Wu, J., et al. (2024). InternVL: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In CVPR.
[3] Xie, Z., & Wu, C. (2024). Mini-Omni: Language Models Can Hear, Talk While Thinking in Streaming. arXiv preprint arXiv:2408.16725.
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
