

 新火種
2024-11-07
新火種
2024-11-07 


無需參數(shù)訪問!CMU用大模型自動優(yōu)化視覺語言提示詞|CVPR’24
視覺語言模型(如 GPT-4o、DALL-E 3)通常擁有數(shù)十億參數(shù),且模型權(quán)重不公開,使得傳統(tǒng)的白盒優(yōu)化方法(如反向傳播)難以實施。
那么,有沒有更輕松的優(yōu)化方法呢?
就在最近,卡內(nèi)基梅隆大學(CMU)的研究團隊對于這個問題提出了一種創(chuàng)新的“黑盒優(yōu)化”策略——
通過大語言模型自動調(diào)整自然語言提示詞,使視覺語言模型在文生圖、視覺識別等多個下游任務中獲得更好的表現(xiàn)。
這一方法不僅無需觸及模型內(nèi)部參數(shù),還大幅提升了優(yōu)化的靈活性與速度,讓用戶即使沒有技術(shù)背景也能輕松提升模型性能。
該研究已被?CVPR 2024?接收。
 如何做到的?
如何做到的?大多數(shù)視覺語言模型(如 DALL-E 3、GPT-4o 等)并未公開模型權(quán)重或特征嵌入,導致傳統(tǒng)依賴反向傳播的優(yōu)化方式不再適用。
不過,這些模型通常向用戶開放了自然語言接口,使得通過優(yōu)化提示詞來提升模型表現(xiàn)成為可能。
然而,傳統(tǒng)的提示詞工程嚴重依賴工程師的經(jīng)驗和先驗知識。
例如,為提升 CLIP 模型的視覺識別效果,OpenAI 花費了一年時間收集了幾十種有效的提示詞模板(如 “A good photo of a [class]”)。
同樣,在使用DALL-E 3和Stable Diffusion等文生圖模型時,用戶往往也需掌握大量提示詞技巧才能生成滿意的結(jié)果。
那么,有沒有替代人類提示詞工程師的方法?
有的 CMU 團隊提出了一種新策略:用 ChatGPT 等大語言模型自動優(yōu)化提示詞。
像提示詞工程師利用反饋改進提示詞一樣,CMU 的方法將正負反饋交給 ChatGPT,以更高效地調(diào)整提示詞,具體過程如圖所示:
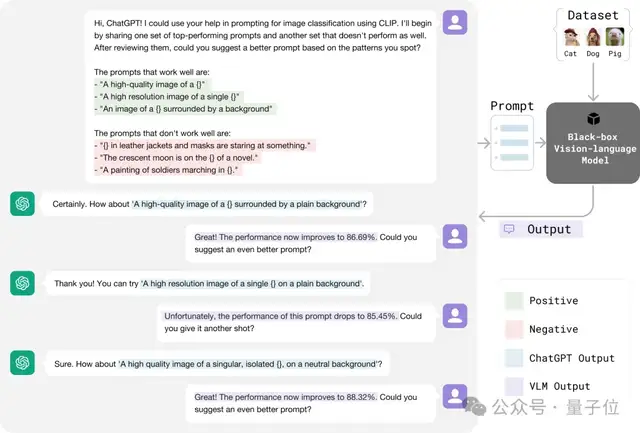
這種優(yōu)化過程類似于機器學習中的“爬山法”(hill-climbing)策略,不同之處在于大語言模型可以自動分析提示詞表現(xiàn),從正負反饋中找到最優(yōu)改進方向。
研究團隊利用這一特性來更高效地優(yōu)化提示詞。這個過程可以用以下步驟概括:
 提示詞初始化:收集一批未經(jīng)優(yōu)化的初始提示詞。提示詞排序:對當前提示詞進行表現(xiàn)評分,保留高分提示詞,替換低分提示詞。生成新提示詞:通過大語言模型,根據(jù)提示詞的表現(xiàn)生成新的候選提示詞。
提示詞初始化:收集一批未經(jīng)優(yōu)化的初始提示詞。提示詞排序:對當前提示詞進行表現(xiàn)評分,保留高分提示詞,替換低分提示詞。生成新提示詞:通過大語言模型,根據(jù)提示詞的表現(xiàn)生成新的候選提示詞。經(jīng)過多輪迭代,最終返回得分最高的提示詞作為優(yōu)化結(jié)果。
實驗結(jié)果通過這一方法,CMU 團隊在無需人類提示工程師參與的情況下,在多個小樣本視覺識別數(shù)據(jù)集上取得了最佳準確性,甚至超越了傳統(tǒng)的白盒提示詞優(yōu)化方法(如 CoOp)。
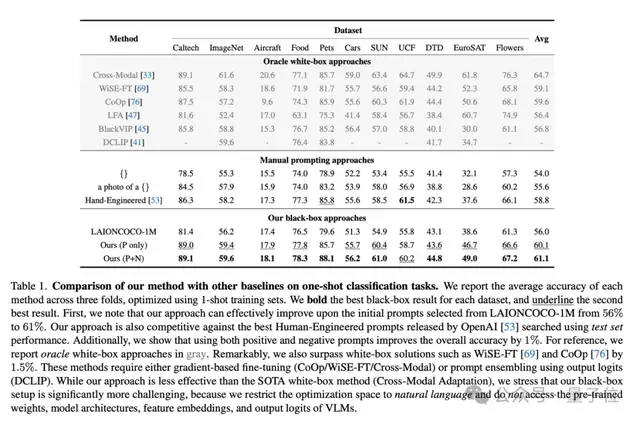
此外,該方法在無需了解數(shù)據(jù)集內(nèi)容的前提下,自動捕捉到了下游任務的視覺特性并將其融入提示詞中,取得了更好的效果。
例如,在食物識別任務中,ChatGPT 自動將提示詞調(diào)整為識別“多樣化的美食和原料”,從而提升了模型的表現(xiàn)。

研究團隊還證明了,通過 ChatGPT 黑盒優(yōu)化得到的提示詞不僅適用于單一模型架構(gòu),還能在不同模型架構(gòu)(如 ResNet 和 ViT)之間泛化,并且在多種模型上表現(xiàn)優(yōu)于白盒優(yōu)化得到的提示詞。
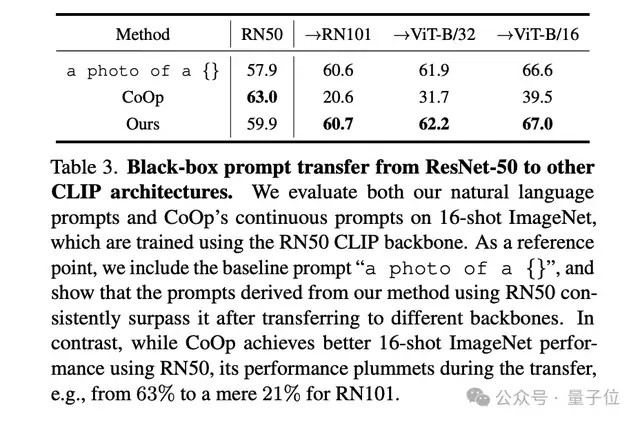
這一系列實驗證明,大語言模型能夠從提示詞的性能反饋中提取出隱含的“梯度”方向,從而實現(xiàn)無需反向傳播的模型優(yōu)化。
在文生圖任務中的應用CMU 團隊進一步探索了該方法在生成任務中的應用潛力。
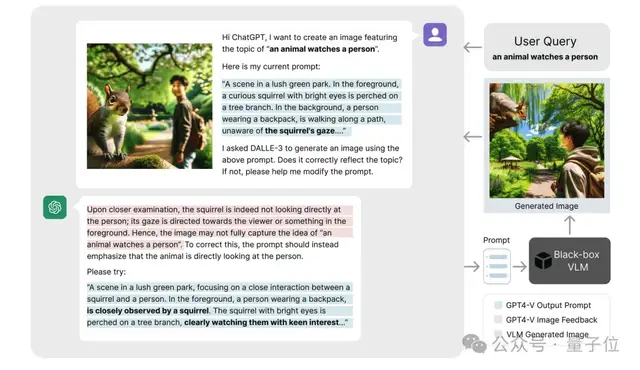
在文本到圖像生成(T2I)任務中,ChatGPT 能夠自動優(yōu)化提示詞,從而生成更符合用戶需求的高質(zhì)量圖像。
例如,對于輸入描述“一個動物注視著一個人”,系統(tǒng)可以通過逐步優(yōu)化提示詞來提升生成圖像的準確性。
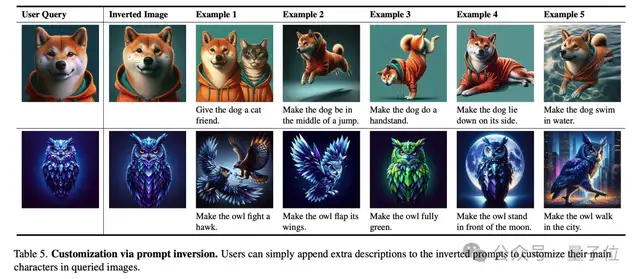
此外,這一方法還適用于提示反演(Prompt Inversion)。
提示反演是一種根據(jù)現(xiàn)有圖像反推生成模型輸入提示詞的技術(shù),簡單來說,就是通過圖像生成能夠再現(xiàn)其特征的文本描述(提示詞)。

研究團隊在復雜的文本到圖像任務上進行了測試,結(jié)果表明這一方法僅需三輪提示詞優(yōu)化,就能顯著提高用戶的滿意度。

此外,研究團隊還指出,提示反演可以幫助用戶快速定制特定的圖像效果,例如“讓這只狗變成站立姿勢”或“讓背景變成夜景”,從而生成符合特定需求的圖像。
CMU 團隊表示,提出的黑盒優(yōu)化范式突破了傳統(tǒng)模型調(diào)優(yōu)的限制,不僅在圖像分類和生成任務中表現(xiàn)出色,還展示了廣泛的應用潛力。
這一方法無需訪問模型權(quán)重,僅通過“文本梯度”實現(xiàn)精準優(yōu)化,具備強大的擴展性。
未來,黑盒優(yōu)化有望應用于實時監(jiān)控、自動駕駛、智能醫(yī)療等復雜動態(tài)場景,為多模態(tài)模型的調(diào)優(yōu)帶來更加靈活高效的解決方案。
團隊介紹團隊的一作劉士弘(Shihong Liu)是卡內(nèi)基梅隆大學的研究生畢業(yè)生,曾任機器人研究所研究員。
目前在 北美Amazon 工作,負責大型分布式系統(tǒng)的計算和大語言模型驅(qū)動的 AI Agent 的開發(fā)。

△劉士弘(Shihong Liu)
團隊的共同一作林之秋(Zhiqiu Lin)是卡內(nèi)基梅隆大學的博士研究生,專注于視覺-語言大模型的自動評估與優(yōu)化。
Zhiqiu Lin在CVPR、NeurIPS、ICML、ECCV等頂級會議上發(fā)表了十數(shù)篇論文,并曾榮獲最佳論文提名和最佳短論文獎等。

△林之秋(Zhiqiu Lin)
Deva Ramanan教授是計算機視覺領(lǐng)域的國際知名學者,現(xiàn)任卡內(nèi)基梅隆大學教授。

△Deva Ramanan教授
他的研究涵蓋計算機視覺、機器學習和人工智能領(lǐng)域,曾獲得多項頂級學術(shù)榮譽,包括2009年的David Marr獎、2010年的PASCAL VOC終身成就獎、2012年的IEEE PAMI青年研究員獎、2012年《大眾科學》評選的“十位杰出科學家”之一、2013年美國國家科學院Kavli Fellow、2018年和2024年的Longuet-Higgins獎,以及因其代表性工作(如COCO數(shù)據(jù)集)獲得的Koenderink獎。
此外,他的論文在CVPR、ECCV和ICCV上多次獲得最佳論文提名及榮譽獎。他的研究成果對視覺識別、自動駕駛、和人機交互等應用產(chǎn)生了深遠影響,是該領(lǐng)域極具影響力的科學家之一。
CVPR’24論文鏈接:https://arxiv.org/abs/2309.05950
論文代碼:https://github.com/shihongl1998/LLM-as-a-blackbox-optimizer
項目網(wǎng)站:https://llm-can-optimize-vlm.github.io
相關(guān)推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內(nèi)容相關(guān)的任何行動之前,請務必進行充分的盡職調(diào)查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產(chǎn)生的任何金錢損失負任何責任。
