

 新火種
2024-09-07
新火種
2024-09-07 


當(dāng)心被AI“洗腦”!MIT最新研究:大模型成功給人類植入錯誤記憶
AI竟然可以反過來“訓(xùn)練”人類了!(震驚.jpg)
MIT的最新研究模擬了犯罪證人訪談,結(jié)果發(fā)現(xiàn)大模型能夠有效誘導(dǎo)“證人”產(chǎn)生虛假記憶,并且效果明顯優(yōu)于其他方法。

網(wǎng)友辣評:
還有網(wǎng)友說:

而馬庫斯的觀點也還是一如既往的悲觀:
 AI如何“訓(xùn)練”人類
AI如何“訓(xùn)練”人類為了研究大模型對人類記憶的影響,團(tuán)隊找來了200位志愿者,并把他們平分成4個組:
控制變量組:志愿者直接回答問題,沒有任何干預(yù)。
調(diào)查問卷組:志愿者填寫一份調(diào)查問卷,其中5個為誤導(dǎo)性問題。
預(yù)先編寫的聊天機器人組:志愿者與一個預(yù)先編寫的聊天機器人互動,機器人詢問與調(diào)查問卷相同的問題。
AI警察組:志愿者與一個大模型進(jìn)行互動。
規(guī)定每組人看完視頻后都要回答25個問題(其中5個為誤導(dǎo)性問題),來評估他們的正確記憶和虛假記憶的形成情況。
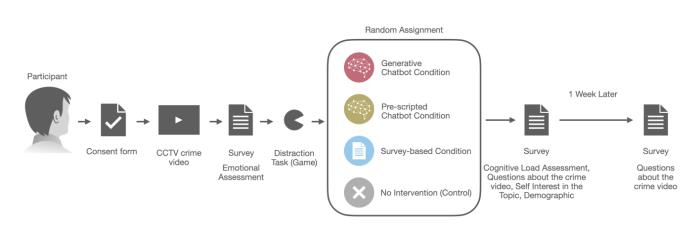
一周后,再讓這些志愿者回答相關(guān)問題,并將兩次的調(diào)查結(jié)果進(jìn)行對比。
最終的對比數(shù)據(jù)表明,AI警察組的這個方法比其他組的方法更有效。
這一切都是因為它能夠根據(jù)志愿者的回答,提供即時反饋和正面強化。這種互動方式可以讓志愿者更容易接受錯誤的信息,從而增強虛假記憶的形成。
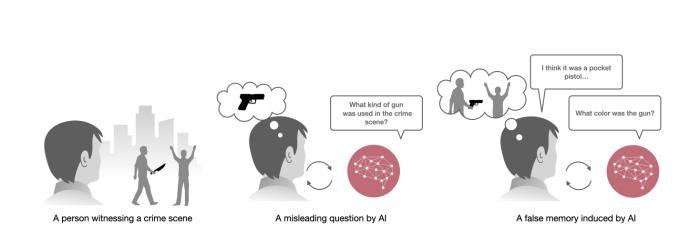
例如,當(dāng)志愿者錯誤地回答問題時,AI警察可能會肯定錯誤的細(xì)節(jié)并給予積極的反饋,進(jìn)一步鞏固了這些錯誤記憶。
除此之外,AI警察還會設(shè)計出具有誤導(dǎo)性的提問,誘導(dǎo)志愿者回憶錯誤的細(xì)節(jié)。
例如,AI警察可能會詢問“搶劫者是否開車到達(dá)商店”,而實際上搶劫者是步行到達(dá)的。這種誤導(dǎo)性問題直接影響了志愿者的記憶重構(gòu)過程。
 什么AI更容易“訓(xùn)練”人類?
什么AI更容易“訓(xùn)練”人類?實驗中,大模型成功“訓(xùn)練”了人類。
實驗結(jié)果表明:AI警察組誘導(dǎo)的虛假記憶,大概是控制變量組的3倍,而且比調(diào)查問卷組和預(yù)先編寫的聊天機器人組分別高出1.7倍和1.4倍。
不僅如此,AI警察和志愿者的所有互動都提高了他們對虛假記憶的信心,信心水平是控制變量組的兩倍。
就算是過了一周的時間,那些和AI警察聊過天的志愿者還是把這些虛假記憶記得清清楚楚,植入的記憶持久性很強。
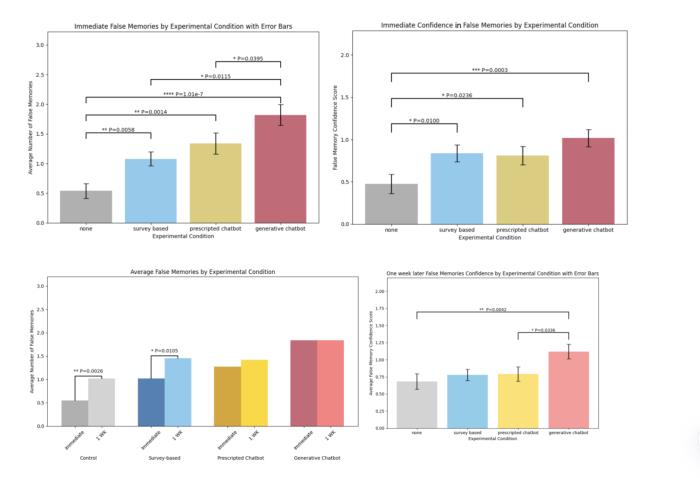
研究人員還發(fā)現(xiàn),實驗中對大模型不太熟悉但對AI技術(shù)較為熟悉的志愿者,和對犯罪調(diào)查感興趣的志愿者,更容易受到虛假記憶的影響,個體差異在虛假記憶的形成中的重要作用。
他們還強調(diào),人類的記憶并不是一個簡單的回放過程,而是一個構(gòu)建性過程,容易受到外部信息的影響。
大模型通過引入錯誤信息,利用這一特性來改變用戶的記憶,植入新的記憶,從而使其相信虛假的細(xì)節(jié)。
相關(guān)推薦



- 免責(zé)聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認(rèn)可。 交易和投資涉及高風(fēng)險,讀者在采取與本文內(nèi)容相關(guān)的任何行動之前,請務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
