

 新火種
2023-09-28
新火種
2023-09-28 

自然語言處理(NLP)中的深度學習發展史和待解難題
王小新 編譯自 sigmoidal量子位 出品 | 公眾號 QbitAI自然語言處理(NLP)是指機器理解并解釋人類寫作與說話方式的能力。近年來,深度學習技術在自然語言處理方面的研究和應用也取得了顯著的成果。技術博客Sigmoidal最近發布了一篇文章,作者是機器學習工程師Rafal。這篇文章討論了自然語言處理方法的發展史,以及深度學習帶來的影響。量子位編譯如下:在深度學習時代來臨前在2006年Hinton提出深度信念網絡(DBN)之前,神經網絡是一種極其復雜且難以訓練的功能網絡,所以只能作為一種數學理論來進行研究。在神經網絡成為一種強大的機器學習工具之前,經典的數據挖掘算法在自然語言處理方面有著許多相當成功的應用。我們可以使用一些很簡單且容易理解的模型來解決常見問題,比如垃圾郵件過濾、詞性標注等。但并不是所有問題都能用這些經典模型來解決。簡單的模型不能準確地捕捉到語言中的細微之處,比如諷刺、成語或語境。基于總體摘要的算法(如詞袋模型)在提取文本數據的序列性質時效果不佳,而N元模型(n-grams)在模擬廣義情境時嚴重受到了“維度災難(curse of dimensionality)”問題的影響,隱馬爾可夫(HMM)模型受馬爾可夫性質所限,也難以克服上述問題。這些方法在更復雜的NLP問題中也有應用,但是并沒有取得很好的效果。第一個技術突破:Word2Vec神經網絡能提供語義豐富的單詞表征,給NLP領域帶來了根本性突破。在此之前,最常用的表征方法為one-hot編碼,即每個單詞會被轉換成一個獨特的二元向量,且只有一個非零項。這種方法嚴重地受到了稀疏性的影響,不能用來表示任何帶有特定含義的詞語。 △ Word2Vec方法中被投射到二維空間中的單詞表征然而,我們可以嘗試關注幾個周圍單詞,移除中間單詞,并通過在神經網絡輸入一個中間單詞后,預測周圍單詞,這就是skip-gram模型;或是基于周圍單詞,進行預測中間單詞,即連續詞袋模型(CBOW)。當然,這種模型沒什么用處,但是事實證明,它可在保留了單詞語義結構的前提下,用來生成一個強大且有效的向量表示。進一步改進盡管Word2Vec模型的效果超過了許多經典算法,但是仍需要一種能捕獲文本長短期順序依賴關系的解決方法。對于這個問題,第一種解決方法為經典的循環神經網絡(Recurrent Neural Networks),它利用數據的時間性質,使用存儲在隱含狀態中的先前單詞信息,有序地將每個單詞傳輸到訓練網絡中。
△ Word2Vec方法中被投射到二維空間中的單詞表征然而,我們可以嘗試關注幾個周圍單詞,移除中間單詞,并通過在神經網絡輸入一個中間單詞后,預測周圍單詞,這就是skip-gram模型;或是基于周圍單詞,進行預測中間單詞,即連續詞袋模型(CBOW)。當然,這種模型沒什么用處,但是事實證明,它可在保留了單詞語義結構的前提下,用來生成一個強大且有效的向量表示。進一步改進盡管Word2Vec模型的效果超過了許多經典算法,但是仍需要一種能捕獲文本長短期順序依賴關系的解決方法。對于這個問題,第一種解決方法為經典的循環神經網絡(Recurrent Neural Networks),它利用數據的時間性質,使用存儲在隱含狀態中的先前單詞信息,有序地將每個單詞傳輸到訓練網絡中。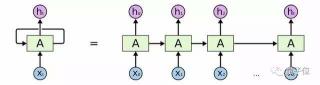 △ 循環神經網絡示意圖事實證明,這種網絡能很好地處理局部依賴關系,但是由于“梯度消失”問題,很難訓練出理想效果。為了解決這個問題,Schmidhuber等人提出了一種新型網絡拓撲結構,即長短期記憶模型(Long Short Term Memory)。它通過在網絡中引入一種叫做記憶單元的特殊結構來解決該問題。這種復雜機制能有效獲取單元間更長期的依賴關系,且不會顯著增加參數量。現有的很多常用結構也是LSTM模型的變體,例如mLSTM模型或GRU模型。這得益于提出了基于自適應簡化的記憶單元更新機制,顯著減少了所需的參數量。在計算機視覺領域中,卷積神經網絡已經取得了很好的應用,遲早會延伸到自然語言處理研究中。目前,作為一種常用的網絡單元,一維卷積已成功應用到多種序列模型問題的處理中,包括語義分割、快速機器翻譯和某些序列轉換網絡中。由于更容易進行并行計算,與循環神經網絡相比,一維卷積在訓練速度上已提高了一個數量級。了解常見的NLP問題有許多任務,涉及到計算機與人類語言之間的交互,這可能對人類來說是一件簡單的小事,但是給計算機帶來了很大的麻煩。這主要是由語言中細微差異引起的,如諷刺、成語等。按照復雜程度,下面列出了當前還處于探索階段的多個NLP領域:最常見的領域是情緒分析(Sentiment Analysis),這方面也許最為簡單。它通常可歸結為確定說話者/作者對某個特定主題的態度或情感反應。這種情緒可能是積極的、中性的和消極的。文末的鏈接1給出了一篇關于使用深度卷積神經網絡學習Twitter情緒的經典文章。鏈接2的一個有趣實驗偶然發現,深度循環網絡也可用來辨識情緒。
△ 循環神經網絡示意圖事實證明,這種網絡能很好地處理局部依賴關系,但是由于“梯度消失”問題,很難訓練出理想效果。為了解決這個問題,Schmidhuber等人提出了一種新型網絡拓撲結構,即長短期記憶模型(Long Short Term Memory)。它通過在網絡中引入一種叫做記憶單元的特殊結構來解決該問題。這種復雜機制能有效獲取單元間更長期的依賴關系,且不會顯著增加參數量。現有的很多常用結構也是LSTM模型的變體,例如mLSTM模型或GRU模型。這得益于提出了基于自適應簡化的記憶單元更新機制,顯著減少了所需的參數量。在計算機視覺領域中,卷積神經網絡已經取得了很好的應用,遲早會延伸到自然語言處理研究中。目前,作為一種常用的網絡單元,一維卷積已成功應用到多種序列模型問題的處理中,包括語義分割、快速機器翻譯和某些序列轉換網絡中。由于更容易進行并行計算,與循環神經網絡相比,一維卷積在訓練速度上已提高了一個數量級。了解常見的NLP問題有許多任務,涉及到計算機與人類語言之間的交互,這可能對人類來說是一件簡單的小事,但是給計算機帶來了很大的麻煩。這主要是由語言中細微差異引起的,如諷刺、成語等。按照復雜程度,下面列出了當前還處于探索階段的多個NLP領域:最常見的領域是情緒分析(Sentiment Analysis),這方面也許最為簡單。它通常可歸結為確定說話者/作者對某個特定主題的態度或情感反應。這種情緒可能是積極的、中性的和消極的。文末的鏈接1給出了一篇關于使用深度卷積神經網絡學習Twitter情緒的經典文章。鏈接2的一個有趣實驗偶然發現,深度循環網絡也可用來辨識情緒。 △ 生成對話網絡中的多個激活神經元。明顯看出,即使進行無監督訓練,網絡也能分辨出不同情緒類別。我們可以將這種方法應用到文件分類(Document Classification)中,這是一個普通的分類問題,而不是為每篇文章打幾個標簽。鏈接3的論文通過仔細比較算法間差異,得出深度學習也可作為一種文本分類方法的結論。接下來將要介紹一個真正有挑戰的領域——機器翻譯(Machine Translation)。這是一個與先前兩個任務完全不同的研究領域。我們需要一個預測模型,來輸出一個單詞序列,而不是一個標簽。在序列數據研究中,深度學習理論的加入給這個領域帶來了巨大的突破。通過鏈接4的博文中,你可以了解更多關于循環神經網絡在機器翻譯中的應用。我們可能還想要構建一個自動文本摘要(Text Summarization)模型,它需要在保留所有含義的前提下,提取出文本中最重要的部分。這需要一種算法來了解全文,同時能夠鎖定文章中能代表大部分含義的特定內容。在端到端方法中,可以引入注意力機制(Attention Mechanisms)模塊來很好地解決這個問題。關于注意力機制的詳細內容可參考量子位先前編譯過的文章《自然語言處理中的注意力機制是干什么的?》最后一個領域為自動問答(Question Answering),這是一個與人工智能極其相關的研究方向。相關模型不僅需要了解所提出的問題,而且需充分了解文本中的關注點,并準確地知道在何處尋找答案。關于深度學習在自動問答中的詳細說明,請查看鏈接5的相關博文。
△ 生成對話網絡中的多個激活神經元。明顯看出,即使進行無監督訓練,網絡也能分辨出不同情緒類別。我們可以將這種方法應用到文件分類(Document Classification)中,這是一個普通的分類問題,而不是為每篇文章打幾個標簽。鏈接3的論文通過仔細比較算法間差異,得出深度學習也可作為一種文本分類方法的結論。接下來將要介紹一個真正有挑戰的領域——機器翻譯(Machine Translation)。這是一個與先前兩個任務完全不同的研究領域。我們需要一個預測模型,來輸出一個單詞序列,而不是一個標簽。在序列數據研究中,深度學習理論的加入給這個領域帶來了巨大的突破。通過鏈接4的博文中,你可以了解更多關于循環神經網絡在機器翻譯中的應用。我們可能還想要構建一個自動文本摘要(Text Summarization)模型,它需要在保留所有含義的前提下,提取出文本中最重要的部分。這需要一種算法來了解全文,同時能夠鎖定文章中能代表大部分含義的特定內容。在端到端方法中,可以引入注意力機制(Attention Mechanisms)模塊來很好地解決這個問題。關于注意力機制的詳細內容可參考量子位先前編譯過的文章《自然語言處理中的注意力機制是干什么的?》最后一個領域為自動問答(Question Answering),這是一個與人工智能極其相關的研究方向。相關模型不僅需要了解所提出的問題,而且需充分了解文本中的關注點,并準確地知道在何處尋找答案。關于深度學習在自動問答中的詳細說明,請查看鏈接5的相關博文。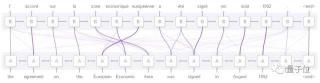 △ GNMT英譯法的注意力機制示意圖。由于深度學習為各種數據(如文本和圖像)提供相應的向量表征,你可以利用不同的數據特性構建出不同模型。于是,就有了圖片問答(Visual Question Answering)研究。這種方式比較簡單,你只需要根據給出圖像,回答相應問題。這項工作簡單到聽起來好像一個七歲小孩就能完成,但是深層模型在無監督情況下不能輸出任何合理的結果。鏈接6的文章給出了相關模型的結果和說明。總結我們可以發現,深度學習在自然語言處理中也取得了很好的效果。但是由于計算和應用等問題,我們仍需要進一步了解深度神經網絡,一旦可以掌控深度學習,這將永遠改變游戲規則。相關鏈接1.Twitter情緒分類:/uploads/pic/20230928/
△ GNMT英譯法的注意力機制示意圖。由于深度學習為各種數據(如文本和圖像)提供相應的向量表征,你可以利用不同的數據特性構建出不同模型。于是,就有了圖片問答(Visual Question Answering)研究。這種方式比較簡單,你只需要根據給出圖像,回答相應問題。這項工作簡單到聽起來好像一個七歲小孩就能完成,但是深層模型在無監督情況下不能輸出任何合理的結果。鏈接6的文章給出了相關模型的結果和說明。總結我們可以發現,深度學習在自然語言處理中也取得了很好的效果。但是由于計算和應用等問題,我們仍需要進一步了解深度神經網絡,一旦可以掌控深度學習,這將永遠改變游戲規則。相關鏈接1.Twitter情緒分類:/uploads/pic/20230928/
△ Word2Vec方法中被投射到二維空間中的單詞表征然而,我們可以嘗試關注幾個周圍單詞,移除中間單詞,并通過在神經網絡輸入一個中間單詞后,預測周圍單詞,這就是skip-gram模型;或是基于周圍單詞,進行預測中間單詞,即連續詞袋模型(CBOW)。當然,這種模型沒什么用處,但是事實證明,它可在保留了單詞語義結構的前提下,用來生成一個強大且有效的向量表示。進一步改進盡管Word2Vec模型的效果超過了許多經典算法,但是仍需要一種能捕獲文本長短期順序依賴關系的解決方法。對于這個問題,第一種解決方法為經典的循環神經網絡(Recurrent Neural Networks),它利用數據的時間性質,使用存儲在隱含狀態中的先前單詞信息,有序地將每個單詞傳輸到訓練網絡中。△ 循環神經網絡示意圖事實證明,這種網絡能很好地處理局部依賴關系,但是由于“梯度消失”問題,很難訓練出理想效果。為了解決這個問題,Schmidhuber等人提出了一種新型網絡拓撲結構,即長短期記憶模型(Long Short Term Memory)。它通過在網絡中引入一種叫做記憶單元的特殊結構來解決該問題。這種復雜機制能有效獲取單元間更長期的依賴關系,且不會顯著增加參數量。現有的很多常用結構也是LSTM模型的變體,例如mLSTM模型或GRU模型。這得益于提出了基于自適應簡化的記憶單元更新機制,顯著減少了所需的參數量。在計算機視覺領域中,卷積神經網絡已經取得了很好的應用,遲早會延伸到自然語言處理研究中。目前,作為一種常用的網絡單元,一維卷積已成功應用到多種序列模型問題的處理中,包括語義分割、快速機器翻譯和某些序列轉換網絡中。由于更容易進行并行計算,與循環神經網絡相比,一維卷積在訓練速度上已提高了一個數量級。了解常見的NLP問題有許多任務,涉及到計算機與人類語言之間的交互,這可能對人類來說是一件簡單的小事,但是給計算機帶來了很大的麻煩。這主要是由語言中細微差異引起的,如諷刺、成語等。按照復雜程度,下面列出了當前還處于探索階段的多個NLP領域:最常見的領域是情緒分析(Sentiment Analysis),這方面也許最為簡單。它通常可歸結為確定說話者/作者對某個特定主題的態度或情感反應。這種情緒可能是積極的、中性的和消極的。文末的鏈接1給出了一篇關于使用深度卷積神經網絡學習Twitter情緒的經典文章。鏈接2的一個有趣實驗偶然發現,深度循環網絡也可用來辨識情緒。△ 生成對話網絡中的多個激活神經元。明顯看出,即使進行無監督訓練,網絡也能分辨出不同情緒類別。我們可以將這種方法應用到文件分類(Document Classification)中,這是一個普通的分類問題,而不是為每篇文章打幾個標簽。鏈接3的論文通過仔細比較算法間差異,得出深度學習也可作為一種文本分類方法的結論。接下來將要介紹一個真正有挑戰的領域——機器翻譯(Machine Translation)。這是一個與先前兩個任務完全不同的研究領域。我們需要一個預測模型,來輸出一個單詞序列,而不是一個標簽。在序列數據研究中,深度學習理論的加入給這個領域帶來了巨大的突破。通過鏈接4的博文中,你可以了解更多關于循環神經網絡在機器翻譯中的應用。我們可能還想要構建一個自動文本摘要(Text Summarization)模型,它需要在保留所有含義的前提下,提取出文本中最重要的部分。這需要一種算法來了解全文,同時能夠鎖定文章中能代表大部分含義的特定內容。在端到端方法中,可以引入注意力機制(Attention Mechanisms)模塊來很好地解決這個問題。關于注意力機制的詳細內容可參考量子位先前編譯過的文章《自然語言處理中的注意力機制是干什么的?》最后一個領域為自動問答(Question Answering),這是一個與人工智能極其相關的研究方向。相關模型不僅需要了解所提出的問題,而且需充分了解文本中的關注點,并準確地知道在何處尋找答案。關于深度學習在自動問答中的詳細說明,請查看鏈接5的相關博文。△ GNMT英譯法的注意力機制示意圖。由于深度學習為各種數據(如文本和圖像)提供相應的向量表征,你可以利用不同的數據特性構建出不同模型。于是,就有了圖片問答(Visual Question Answering)研究。這種方式比較簡單,你只需要根據給出圖像,回答相應問題。這項工作簡單到聽起來好像一個七歲小孩就能完成,但是深層模型在無監督情況下不能輸出任何合理的結果。鏈接6的文章給出了相關模型的結果和說明。總結我們可以發現,深度學習在自然語言處理中也取得了很好的效果。但是由于計算和應用等問題,我們仍需要進一步了解深度神經網絡,一旦可以掌控深度學習,這將永遠改變游戲規則。相關鏈接1.Twitter情緒分類:/uploads/pic/20230928/ 相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
