

 新火種
2024-08-30
新火種
2024-08-30 


專訪Motiff妙多國內首個UI大模型:UI領域,未來通用大模型很難趕超領域模型
「」去年年初ChatGPT引爆全球,大模型一路狂飆,迄今,行業的熱潮從通用大模型早已轉移到領域模型、應用、多模態以及當下最火的機器人。
整個行業在尋求應用落地的過程中,領域模型應運而生,有關于通用大模型跟領域模型誰更有價值的討論仍未停止。有人認為通用大模型只是提供一個底座,具備大學生的智商,而要想成為一個專業領域的研究生,則需要給它投喂更多領域知識,專門訓練一個領域模型;但也有人斷言隨著模型不斷迭代,一個通用模型也能表現出很強的專業能力,這在代碼生成領域已成事實,例如Claude 3.5 Sonnet 在代碼能力上可媲美一些垂直代碼模型。
而對自研國內首個UI多模態大模型的AI設計工具Motiff妙多(下簡稱“Motiff”)來說,其副總裁張昊然告訴AI科技評論,在尋找商業化落地的過程中,大模型廠商會選擇更大業態、更多領域數據的商業場景去做刻意訓練,但UI不在這個領域范疇。
同時在他看來,Scaling Law對絕大多數專業領域是失效的,因為專業領域沒有那么大量級數據,自然不能用Scaling Law去評估,他認為如UI這樣的領域模型應該存在長期價值,通用大模型很難在一個時間周期內去趕超領域模型。
不久前,在IXDC2024國際體驗設計大會上,AI設計工具Motiff推出了自主研發的UI多模態大模型Motiff妙多大模型,這是國內首個UI大模型。
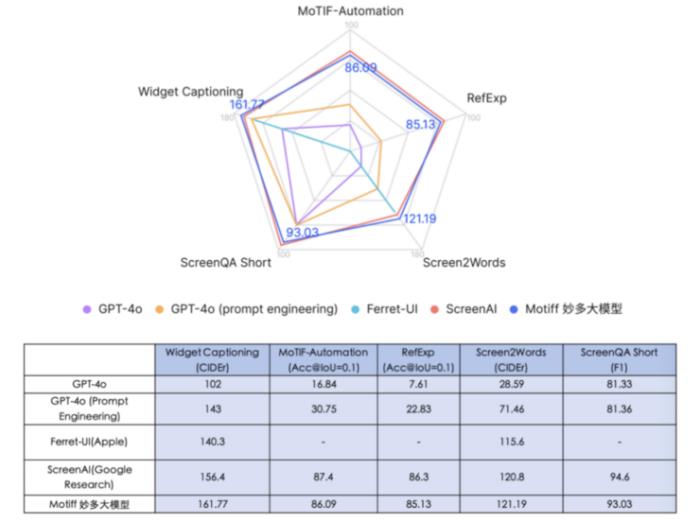
Motiff妙多大模型具備較強的UI理解能力和執行開放式指令的能力。在五個行業公認的UI能力基準測試集中,Motiff妙多大模型的各項指標均超過了GPT-4o和蘋果的Ferret UI,同時在Screen2Words(界面描述與推斷)和Widget Captioning(部件描述)兩大指標上也超越了谷歌的ScreenAI,其中Widget Captioning指標高達161.77,刷新SoTA。與Ferret UI、ScreenAI等現有解決方案相比,Motiff妙多大模型能靈活地根據上下文理解界面元素,達到“設計專家”水平,最接近人類對UI界面的理解和表述結果。
Motiff孵化自猿輔導,這家教育界的獨角獸,在 2021年又開始開拓了一些新的商業方向,猿輔導內部嘗試了羽絨服、月子中心、咖啡等多項業務,這款產品便是其中之一。張昊然便是從那時開始負責Motiff。
近日,Motiff副總裁張昊然在IXDC2024國際體驗設計大會上接受了AI科技評論的訪談,跟我們分享了Motiff多模態大模型背后的訓練故事、商業模式的選擇、對出海的認知等等思考。
以下是為對話實錄,稍經整理:
1 Motiff多模態大模型的訓練過程AI科技評論:一家主營業務是教育培訓的公司,為什么會來做UI多模態大模型?
張昊然:在21年10月,我們寫下了Motiff的第一行代碼,結合團隊的能力、擅長的事情,最終定位到AI結合專業工具可能會是一個新機會,往下細拆選擇了UI設計領域。
整個決策過程經歷了宏觀到微觀,選擇SaaS,選擇專業工具,選擇產研領域的專業工具,選擇UI設計。
AI科技評論:當時看到的整個UI設計的市場規模是多大?
張昊然:當時的預測和今天看到Figma 的結果可能差不多,但今天對總規模更樂觀了。
Figma是領域頭部產品,前年的營收是4億美金,去年是6-7億美金,今年預測大概能到10億。最大的巨頭即將獲得了10億美金的ARR,隨著AI技術的發展,我認為總體市場規模會更大。
AI科技評論:什么時候開始做Motiff妙多大模型?
張昊然:我們其實不是ChatGPT出來后才開始做妙多這個產品,21年 GPT-3 還沒有出現,當時用了很多AI1.0時代的技術,例如深度學習,已經產生了很高的效率。當時驗證了這個方向是可行的,我們認為AI是這個工具到下一個代際的重要變量,大模型只是產品迭代過程中一項新技術出現。所以大模型對我們來說并不是所謂的新創業機會,而是考慮新技術的出現如何增強當下的產品。
AI科技評論:為什么不選用通用大模型來進行微調的方式,而是要選擇自研?
張昊然:通用大模型在處理UI相關任務時,表現是弱的,這是事實。比如說讓它去認知一個UI界面,通常只能到比較表層的認知,很難從UI專業角度去理解,通用模型沒有太多專業領域的知識輸入跟訓練,所以我們需要去訓一個專業模型來處理UI設計任務。
AI科技評論:哪些UI場景已經可以用AI來實現?
張昊然:我們把整個UI的場景分為三個部分,第一個部分是設計師日常的工作,也是一個可抽象、可量化的操作,比如說要完成一個設計稿,需要多少步驟,這些步驟中可以找到一些規律,這里面有非常多是可用AI解決的,原因是這些操作有特別大的共性跟重復性;
第二部分是團隊協作,設計團隊之間的協作,設計團隊跟研發團隊的協作,大家在協作中需要共同面對的問題是保證設計的一致性。一致性怎么理解?例如今天我們看到的微信界面,背后可能有超過100個設計師在做同一款產品的不同模塊,那怎么保證整個團隊不同的人做出的東西是風格統一?這很關鍵。一致性需要一套實踐去約束,目前最廣泛的實踐是通過設計系統的方式,而這里面有大量低效的工作,Motiff的一個方向就是對設計系統的工作流提效。
第三部分是針對大模型出現后對整個UI領域生產力的改變,即生成UI的能力。這是大模型出現后才帶來的改變,以前的AI技術并不能實現生成功能,大模型對自然語義、對圖片的理解能力比原來更強,輸出也更有結構性,這使得AI在生成UI的領域有了更多新的可能。這是我們研究的一個方向。
AI科技評論:這對應了Motiff的三個模塊,AI工具箱,AI設計系統,AI生成UI。
張昊然:是的。AI生成UI一直是我們研究的一個大命題。
AI科技評論:Motiff的訓練選擇的是最經典的整合專家模型,是參照了別的多模態模型的訓練過程嗎?
張昊然:當然有大量的學習跟參照。這源于開源技術的迅速發展,開源才使得更專注領域的團隊去訓練領域模型變得更可能;市面上也有非常多成功的領域模型給了我們很大的信心,像醫療、法律領域的。大家的邏輯都一樣,用更多的領域知識和數據再訓練,讓領域模型更好為行業服務。
AI科技評論:您是產品背景,您是從什么時候開始關注大模型的?
張昊然:從GPT-3進入公眾視野的時候。看到非常驚艷,雖然我沒辦法去訓練實操,但是有更多的精力去嘗試應用。
AI科技評論:您看論文嗎?
張昊然:去年可能是我有生之年看過最多的一年。創業者要有意愿去follow前沿,因為這是一個非常大的技術革命。
AI科技評論:在整個Motiff妙多大模型訓練過程中遇到的最大困難是什么?
張昊然:最大的困難是數據的有效性驗證。我們從非常多的來源收集了近千萬的數據,判斷哪些數據有用,哪些數據有害,是比較困難的。一般來說驗證數據有效性的方法是消融實驗,但是大模型的訓練成本太高,所以沒辦法每個數據消融。
AI科技評論:Motiff是一個自研模型,但是底層的視覺模型和語言模型都是拿的開源或者別家的,自研的部分在哪里?
張昊然:關鍵問題是我們如何定義“自研”。在我的定義里,如果我們自己研究出一個新的東西,跟別人不一樣,能帶來價值,這個自己研究的過程可叫“自研”。
從這個角度,Motiff 妙多大模型雖然借鑒了很多行業通用的訓練方法,但要解決問題的過程是我們自己研究的,最終也產出了不錯的交付成果,我認為這就是自研。
某種程度上,一輛暢銷的電動車的發動機不是自己的,電池也不是自己的,很多東西都是組裝的,這輛車叫自研嗎?我認為當然也是。
AI科技評論:領域數據是UI多模態大模型表現優劣的關鍵因素嗎?
張昊然:是,我們擁有高質量的數據,這是一種長時間的積累,對于所有的AI工程,數據其實是一個非常強的累積工作,得靠很多方式去收集、標注,如何組織一個規模化的團隊、如何提高標注的生成質量,這些都是AI領域的核心壁壘。
AI科技評論:數據的處理依然是難點?
張昊然:標注的方法中標注的維度是不斷變化的,以及對數據質量好壞的評估,這兩件事是難點。因為標注維度會隨著應用場景的變化去變化,可能第一次想到的標注維度已經夠詳細了,但面向一個新的產品設計問題時,又發現原來的標注維度是不夠的。
這是一個值得大家去反復思考、完善的事情,目前看來第二點才是更難的點,因為模型訓練中數據好的好壞、大家各自評價標準不同,模型的效果就不同,這個過程非常主觀,我們也找到了一些方法反復去評估、提升。
AI科技評論:獲取千萬量級的預訓練數據花了多長時間,遇到哪些困難?
張昊然:因為 Motiff 在 AI 工作上有持續的積累,所以從幾年前我們就開始收集 UI 界面相關的數據了。此外,Motiff 也積累了很多的 UI 專家模型,這又進一步節約了數據收集的時間。
一個困難是高質量的手機界面量級極小,想獲得訓一個大模型級別的手機界面數據是困難的。
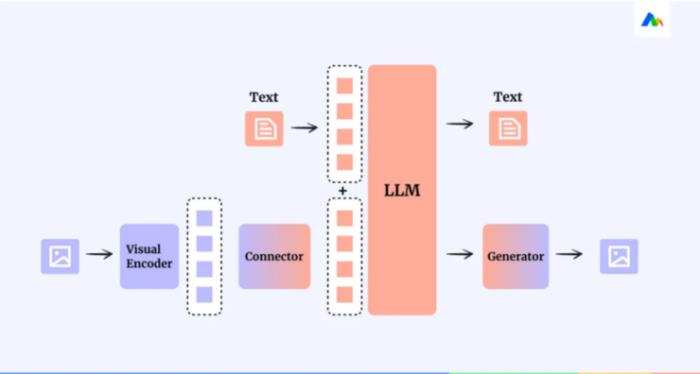
AI科技評論:在多模態大模型訓練中,要將不同模態之間的數據有效地融合非常困難,妙多如何克服這個難題?視覺語言如何轉換成自然語言?
張昊然:從模型角度來說,需要添加模態之間的轉換器(Connector)。從數據角度。需準備模態對齊數據。從訓練角度,則是固定專家模型參數,訓練模態轉換器(Connector)。
AI科技評論:在我們的模型訓練過程中,為什么選擇從第二階段(對齊訓練)開始領域遷移,而不是從第一階段(獨立預訓練)就引入領域知識?
張昊然:在第一階段就去做領域數據的訓練是可行的,我們其實也在探索會不會更好,但它面臨兩個現實的問題,第一階段去做成本巨高,因為訓練量很大,不確定性也會很多;第二點是訓練越接近最后一步,可控性越強,所以在對齊之后做領域的遷移訓練,對模型的規訓能力越強。
AI科技評論:打榜跟在實際生產環境中的表現相差多大?有投資人說現在如果有創業者說他的產品打榜排名多少,他們看都不會看。
張昊然:打榜跟實際生產環境中的表現有相關關系,但不是因果關系。我們的產品更在意的是在專業領域的任務實現是不是夠好,而且打榜用的是公用的評測集,放到行業中會有一定的滯后性。
AI科技評論:UI這塊的評測集的滯后性很大嗎?
張昊然:至少我們現在關注的一些能力從專業角度來說非常重要,但其實都還沒有被納入公開的評測集中。
例如,一些公開的評測集中,有對某個組件到底是什么、怎么使用的理解,但卻沒有對組件的分類、分類是否準確的評測,這是非常務實的一個需求,因為設計師在應用場景中會有組件歸類的訴求,所以這是評測集跟實際需求的gap。
AI科技評論:為什么不在開源的UI MLLMs上直接微調一個領域模型?
張昊然:據我所知目前還沒有開源的UI MLLMs。但如果有,我們選不選開源標準是看如何能讓產品 效果更好,一個開源模型的封裝往往更后置,我們對它的控制力會更弱,優化空間也更小,所以我們權衡后選擇了最經典的整合專家模型這個方案。
AI科技評論:聽您講Motiff要對標Figma,但是Figma并沒有加入太多大模型的能力,Motiff要從哪幾個維度對標?
張昊然:其實不是對標,是革新,用AI能力去革新現有的設計工具,我們要做一個AI時代的設計工具,就要去看Figma定義了哪些,我們要看這些能不能重新定義,我們專注這件事。
AI科技評論:如何解決大模型帶來的超高推理成本這一行業痛點?
張昊然:越大的模型推理成本越高,但并不是所有任務都需要超大的模型。構建不同尺寸的多模態模型,可以緩解這個問題。此外,在功能設計上也有一些巧妙規避推理的方法。推理成本高應該是每個大模型應用的痛點,但是結合 Motiff 更靈活的 AI 產品形態,Motiff妙多大模型有更多更靈活的選擇。
AI科技評論:您覺得大模型時代的產品跟上一個時代的產品有什么不一樣嗎?
張昊然:挺多不同的,尤其是產品力完全不同,過去的AI產品往往解決的是一個領域非常小的場景問題,是用大數據、海量的數據去解決小問題,例如深度學習里最典型的例子就是人臉識別。
產品思維也在發生改變。現在整個行業處于先訓一個模型,再找應用場景的狀態,有時候可能發現問題后再去匹配模型的狀態。做AI產品的成本也大幅下降。以前得確定技術能商業化、評估有多大收益,才能下定決心去做那么大規模的訓練。但是現在大模型訓練出來后被調用的成本是低的,這給了行業很多新機會。人們能夠更低門檻、更大限度、更高頻次地去調用AI能力,從而去產生更多產品創新。這是大模型時代帶來的本質的不同。
2 國內TOB、海外TOCAI科技評論:在商業模式選擇上一開始就說要TOB?
張昊然:其實沒有。對于這類協同SaaS的用戶拓展來說,總結下來有兩套路徑,一個是PLG(Product Led Growth,產品驅動增長)一個是SLG(Sales Led Growth,銷售驅動增長 ),這倆其實不矛盾,可能是一體兩面或者相輔相成去看待。
目前專業工具的付費群體分為C和B,B就是企業付費給員工使用,C的主要市場來源是個體設計師或者小型團隊,例如Freelancer,這部分在國際化市場中的體量非常大。
國內的Freelancer在UI領域偏少,更多還是在企業工作,所以我們目前的階段性做法是海外主要TOC,國內TOB會重一點。這是階段性的選擇,不是一成不變的,原因是,第一點我們覺得Motiff在國內的產品力競爭優勢非常明顯,第二點是國內沒有C,那么國內只能TOB。
AI科技評論:海外TOC的增長策略是什么?
張昊然:海外TOC更符合我們團隊現在的能力,因為一個中國公司出海要靠銷售去打,大部分公司其實不具備這個能力,或者說過往的經歷證明了這樣的團隊是極少的。
AI科技評論:大多數技術方向都是這種狀況嗎?
張昊然:當然也有例外,WPS近些年在某些國家的出海TOB據說做得不錯。但也有一些其它國產的協同辦公產品,有錢有組織力,卻鎩羽而歸。關鍵還是能否找到匹配的區域性市場,以及在區域性市場里還具備較強的企業連接能力。
AI科技評論:Motiff最初就決定要出海嗎?
張昊然:是的,首先出海意味著你的市場天花板可能會高幾十倍,從一片湖到真正的一片海。其次,越工具化的東西越適合全球化,內容或業務屬性越強的越難,這是個共識。Motiff是個工具性很強的產品,所以它天然適合國際化。
AI科技評論:Motiff國內外版本有什么不同?
張昊然:功能層面沒什么不同,同時海外和中國在支付、服務、安全性上也有一些差異化訴求,我們會針對化滿足。
AI科技評論:就像飛書一樣,國內的版本很多都是按照國外的用戶使用習慣來設計的,Motiff沒有這樣的設計差異嗎?
張昊然:就像剛才說的,UI并不是一個強內容或業務屬性的行業,相反,它的工具屬性極強,就像“全世界的扳手都長得差不多”。
AI科技評論:隨著這一波生成式AI爆發,中國AI企業出海面臨的共同問題有哪些?
張昊然:我可能不具備能力來總結共同問題,我覺得企業各有各的問題。挑戰往往是針對領域、用戶場景而不同,如果一定要說共性問題,海外直接建立銷售的能力對大多數企業來講是很難的,在這種情況下就要考慮TOC。
AI科技評論:Motiff海外的團隊建設是怎樣的?
張昊然:我們在新加坡、北美有分公司,但更多還是從運營的角度去考慮,而不是銷售角度。
AI科技評論:出海戰場主要是新加坡?
張昊然:我們并不限制國家,Motiff從發布到現在兩個月,在十多個國家已經積累了不錯的用戶量,在不同國家表現也有差異。還是回到工具屬性的問題,大家的gap是小的,其實更多是看有沒有更高效或者ROI(投資回報率)好的渠道,能獲得更多曝光。
AI科技評論:外界一直流傳著一種預判是隨著通用大模型的不斷發展,垂直模型和領域模型未來不需要了,是一種偽命題,您怎么看?
張昊然:這有可能會發生,各種論斷各不相同,我當下的認知是有部分的模型應該存在長期價值,通用大模型很難在一個時間周期內去趕超領域模型。
這背后的原因非常樸實,對于通用模型來說,很難拿到高質量的專業領域數據,一個模型訓練的壁壘還是訓練數據。通用大模型的好處是數量多,大力出奇跡,但是Scaling Law對絕大多數專業領域的效果都是失效的。原因是專業領域沒有那么多數據,不符合大力出奇跡。所以沒有那么大量級的數據時,就談不上一個所謂的Scaling Law。
現實世界中的數據分布往往越不專業的越容易獲得、數量越多,越專業的數據越稀疏。有沒有一些領域會被大模型卷到呢?我覺得會,現在行業面臨最大的挑戰是找不到商業化應用的場景,大模型廠商首先會選擇有更大商業業態、更多領域數據的場景,但目前UI不在這個領域范疇。
AI科技評論:在您看來,大模型帶給UI領域怎樣的影響?
張昊然:我們剛開始做Motiff這個項目時,還沒有大模型技術,當時用的是深度學習等方式去解決任務式的問題,我們都覺得它在效率上已經足夠好了。大模型出現后,它是技術層面的大變革,使得原來很多不可想象的事情變為可能,現在的界面生產工作流是產品經理、UI設計師、研發的整個流程,大模型能有效縮短現有的工作流。
人很多時候受限于效率跟時間,當技術無限壓縮生產流程,使得意圖到實現的路徑變短,最終生產力、生產關系也都會發生改變。「」

相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
