

 新火種
2024-06-05
新火種
2024-06-05 


3B模型新SOTA!開源AI讓日常調用不同大模型更簡單
大模型,大,能力強,好用!
但單一大模型在算力、數據和能耗方面面臨巨大的限制,且消耗大量資源。
而且目前最強大的模型大多為閉源,對AI開發的速度、安全性和公平性有所限制。

AI大模型的未來發展趨勢,需要怎么在單一大模型和多個專門化小模型之間做平衡和選擇?
針對如此現狀,兩位斯坦福校友創辦的NEXA AI,提出了一種新的方法:
采用functional token整合了多個開源模型,每個模型都針對特定任務進行了優化。
他們開發了一個名叫Octopus v4的模型,利用functional token智能地將用戶查詢引導至最合適的垂直模型,并重新格式化查詢以實現最佳性能。
介紹一下,Octopus v4是前代系列模型的演化,擅長選擇和參數理解與重組。
此外,團隊還探索了使用圖作為一種多功能數據結構,有效地協調多個開源模型,利用Octopus模型和functional token的能力。
通過激活約100億參數的模型,Octopus v4在同級別模型中實現了74.8的SOTA MMLU分數。
Octopus系列模型這里要重點介紹一下Octopus-V4-3B。
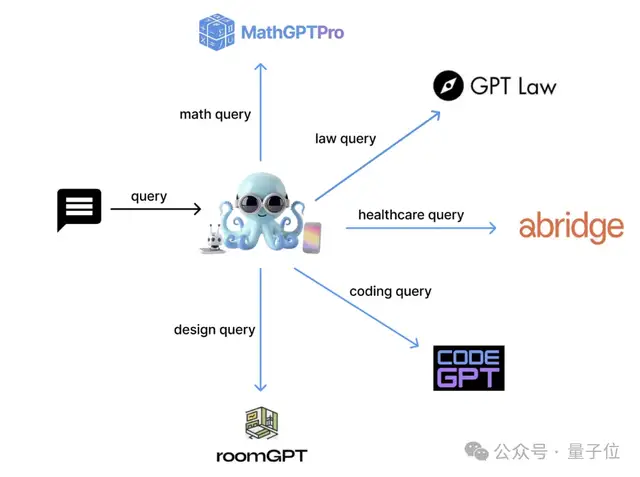
它擁有30億參數,開源,是Nexa AI設想中的語言模型圖的主節點。
該模型專為MMLU基準測試話題定制,能夠高效地將用戶查詢轉換成專業模型可以有效處理的格式。
它擅長將這些查詢正確引導至相應的專業模型,確保精確且有效的查詢處理。
Octopus-V4-3B具備以下特點:
緊湊尺寸:Octopus-V4-3B體積緊湊,使其能在智能設備上高效、迅速地運行。準確性:利用functional token設計準確地將用戶查詢映射到專業模型,提高了其精度。查詢重格式化:幫助將自然人類語言轉換為更專業的格式,改善了查詢描述,從而獲得更準確的響應。
Nexa AI把語言模型作為圖中的節點整合,并提供了針對實際應用定制的系統架構。
此外,討論了使用合成數據集對Octopus模型進行訓練的策略,強調了這種語言模型圖在生產環境中的系統設計。
從Octopus v2提取的用于分類的語言模型研究人員在Octopus v2論文中介紹了一種名為functional token的分類方法。
Octopus v2模型有效地處理了這一任務:
 圖中的語言模型作為節點
圖中的語言模型作為節點考慮一個定義為:G=(N,E)。
其中N代表圖中的各種節點,E代表連接這些節點的邊。
節點分為兩種類型:
一,主節點Nm,它們通過將查詢定向到合適的工作節點Nω并傳遞執行任務所需的信息來協調查詢。
二,工作節點,接收來自主節點的信息并執行所需的任務,使用Octopus模型來促進進一步的協調。
節點信息傳輸過程如下圖所示。
為了處理用戶查詢q并生成響應y,研究人員將概率建模為:
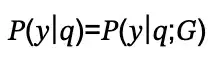
對于只涉及一個工作節點的單步任務,該過程可以定義為:
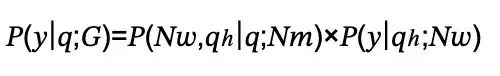
這里,P(Nω,ph|q;Nm)使用Octopus v2模型為m選擇最佳的相鄰工作節點并重新格式化查詢為?,這是重構的查詢。
概率P(y|qh;Nω)由位于工作節點的語言模型計算。
對于多步任務,通常在多代理工作流中,該過程涉及多個節點之間的幾次順序交互,如下:
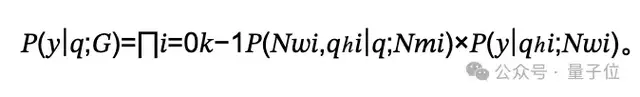 使用圖進行多步驟操作的任務規劃
使用圖進行多步驟操作的任務規劃多步驟任務規劃中,所有功能列在上下文中提交給語言模型,生成基于用戶查詢的計劃。
傳統方法在處理長功能描述時有局限性,尤其是參數少于10B的模型。
基于圖的方法確保只考慮與特定節點相關的鄰近節點,顯著減少了選擇的復雜性。
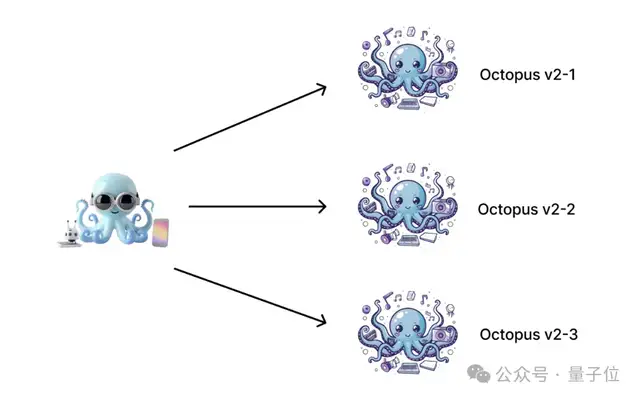 語言模型圖的系統設計
語言模型圖的系統設計以下詳細說明了復雜圖中每個節點代表一個語言模型的系統架構,利用多個Octopus模型進行協調。
在準備生產部署時,整合一個負載均衡器以有效管理系統需求至關重要。
然后,研究團隊將系統劃分為幾個可管理的組件,強調核心方法:
首先是工作節點部署。
每個工作節點Nω對應一個單獨的語言模型。
團隊建議為這些節點采用無服務器架構,特別推薦使用Kubernetes進行基于內存使用和工作負載的強大自動縮放。
其次是主節點部署。
主節點應使用不超過10B參數的基礎模型(實驗中使用3B模型),以便在邊緣設備上部署。
每個工作節點與一個Octopus模型接口,以增強協調。
如Octopus v2所示,可以集成一個緊湊的Lora模型以擴展functional token的能力。
建議使用單一基礎模型并補充多個Loras,每個工作節點一個。
推薦使用開源的LoraX庫來管理這種配置的推理操作。
再者是通訊。
工作節點和主節點分布在不同設備上,不限于單一設備。
因此,互聯網連接對于節點之間的數據傳輸至關重要。
雖然主節點可能位于智能設備上,工作節點則托管在云端或其他設備上,結果返回智能設備。
為了支持數據緩存需求,包括聊天歷史存儲,推薦使用Redis,一個高性能的內存數據庫,促進分布式緩存。
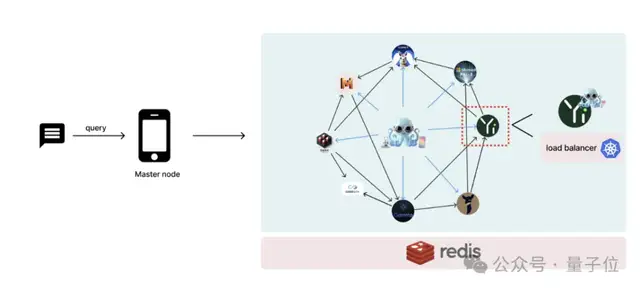 實驗
實驗研究人員詳細介紹了框架進行的實驗,通過多節點協作提高語言模型性能。
采用了17種不同的模型進行MMLU任務,Octopus v4模型將用戶查詢定向到相關的專業模型并適當重格式化。
MMLU包含57個獨特的任務,分為17個整合組。
專業模型根據基準得分、人氣和用戶推薦從Hugging Face精選。
并非所有任務都有專門模型,例如人文學科和社會科學目前無專門模型,但Llama3模型通過系統提示調整模擬專業能力。
 未來工作與討論
未來工作與討論當前,NEXA AI的GitHub 項目專注于開發語言模型的圖形框架,目前處于起始階段。
團隊計劃通過整合多種垂直特定模型并加入Octopus v4模型來增強這一框架,以多代理能力為特征。
未來版本將在此存儲庫中展示更強大的圖形表示。
GitHub Repo將由Nexa AI維護,團隊今后旨在為多種垂直領域開發緊湊、專門化的模型。
與更大模型的縮放法則、數據集相比,NEXA AI的框架無限制,并且可以創建一個大型圖。
此外,團隊正在開發多模態模型Octopus 3.5,能夠處理視覺、音頻和視頻數據;完成開發后,將被納入圖形框架。
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
