

 新火種
2024-06-05
新火種
2024-06-05 


重磅!斯坦福AI團隊被曝抄襲中國大模型開源成果,推特輿論開始發酵
過去一年,中國大模型一直被貼上「追趕美國」的標簽,但近日,推特上卻有人曝出:
美國斯坦福大學的一個 AI 團隊疑似抄襲、「套殼」一家中國大模型公司的開源成果,模型架構與代碼完全相同。
輿論已經開始發酵,引起了圈內人士的廣泛討論。
根據 AI 科技評論整理,事情的經過大致如下:
5 月 29 日,斯坦福大學的一個研究團隊發布了一個名為「Llama3V」的模型,號稱只要 500 美元(約等于人民幣 3650 元)就能訓練出一個 SOTA 多模態模型,且效果比肩 GPT-4V、Gemini Ultra 與 Claude Opus 。
Github開源:https://github.com/mustafaaljadery/llama3v
HuggingFace開源:https://huggingface.co/mustafaaljadery/llama3v(已刪庫)
Medium發布文章:https://aksh-garg.medium.com/llama-3v-building-an-open-source-gpt-4v-competitor-in-under-500-7dd8f1f6c9ee
Twitter官宣模型:https://twitter.com/AkshGarg03/status/1795545445516931355
由于該團隊的作者(Mustafa Aljaddery、Aksh Garg、Siddharth Sharma)來自斯坦福,又集齊了特斯拉、SpaceX、亞馬遜與牛津大學等機構的相關背景經歷,很快該模型發布的推特帖子瀏覽量就已經超過 30 萬,轉發 300+次,并迅速沖到了 Hugging Face 首頁:
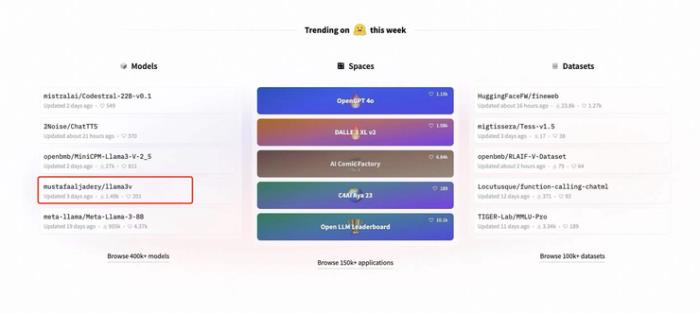
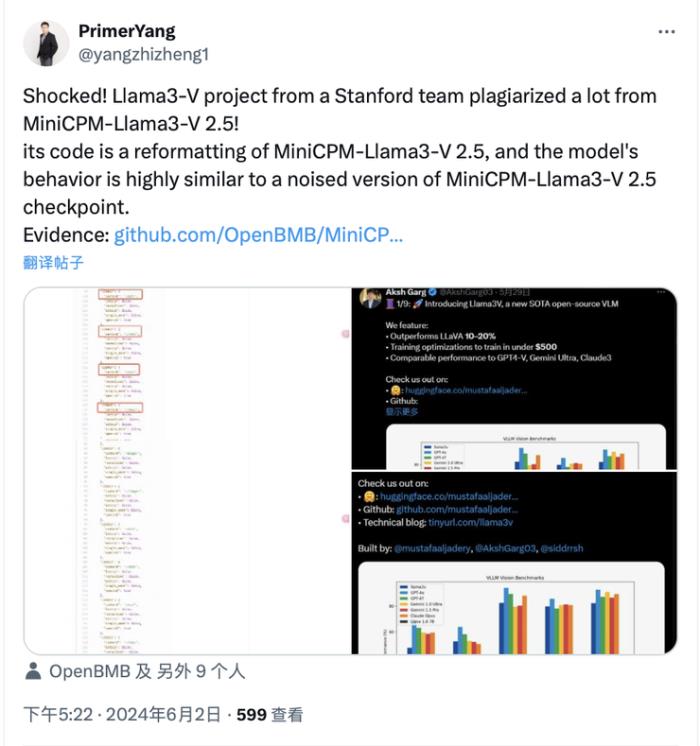
但很快,沒過幾天,推特與 Hugging Face 上就開始出現懷疑的聲音,質疑 Llama3V 套殼面壁智能在 5 月中旬發布的 8B 多模態小模型 MiniCPM-Llama3-V 2.5,且沒有在 Llama3V 的工作中表達任何「致敬」或「感謝」 MiniCPM-Llama3-V 2.5 的聲音。
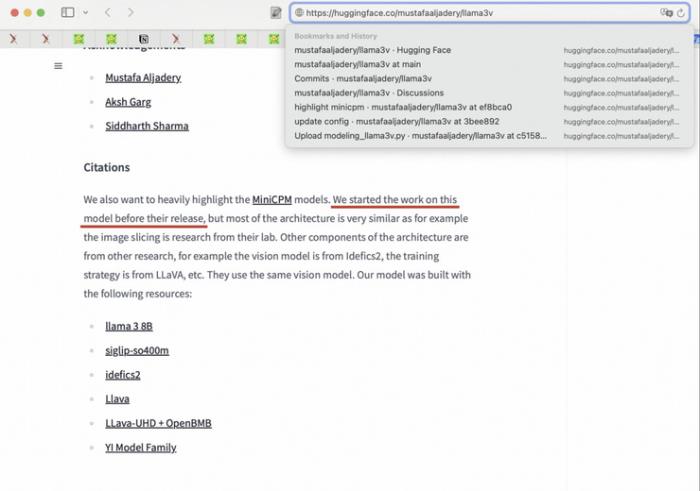
對此,Llama3V 團隊回復,他們「只是使用了 MiniCPM-Llama3-V 2.5 的 tokenizer」,并宣稱「在 MiniCPM-Llama3-V 2.5 發布前就開始了這項工作」。
緊接著,6 月 2 日,有網友在 Llama3V 的 Github 項目下拋出事實性質疑,但很快被 Llama3V 的團隊刪除。為此,提出質疑的網友被激怒暴走,跑到了 MiniCPM-V 的 Github 頁面進行事件還原,提醒面壁智能團隊關注此事。
隨后,面壁團隊通過測試 ,發現 Llama3V 與 MiniCPM-Llama3-V 2.5 在「胎記」般案例上的表現 100% 雷同,「不僅正確的地方一模一樣,連錯誤的地方也一模一樣」。
至此,推特輿論開始發酵,「斯坦福抄襲中國大模型」一事不脛而走。
1、「套殼」證據實錘,斯坦福團隊百口莫辯
最開始,用戶質疑 Llama3V 套殼 MiniCPM-Llama3-V 2.5 開源模型時,Llama3V 作者團隊并不承認,而是聲稱他們只是「使用了 MiniCPM-Llama3-V 2.5 的 tokenizer」,并宣稱他們「在 MiniCPM-Llama3-V 2.5 發布前就開始了這項工作」:
不過,好心網友對 Llama3V 作者團隊的回應并不買單,而是在 Llama3V 的 Github Issue 上發布了一系列質疑,列舉具體 4 點證據,但很快被 Llama3V 的團隊刪除。幸好作者事先截了圖保留:
面對網友的質疑,Llama3V 作者只是避重就輕地回復,稱他們只是使用了 MiniCPM 的配置來解決 Llama3V 的推理 bug,并稱「MiniCPM 的架構是來自 Idéfics,SigLIP也來自 Idéfics,他們也只是追隨 Idéfics 的工作」而非 MiniCPM 的工作,因為「MiniCPM 的視覺部分也是來自 Idéfics 的」——
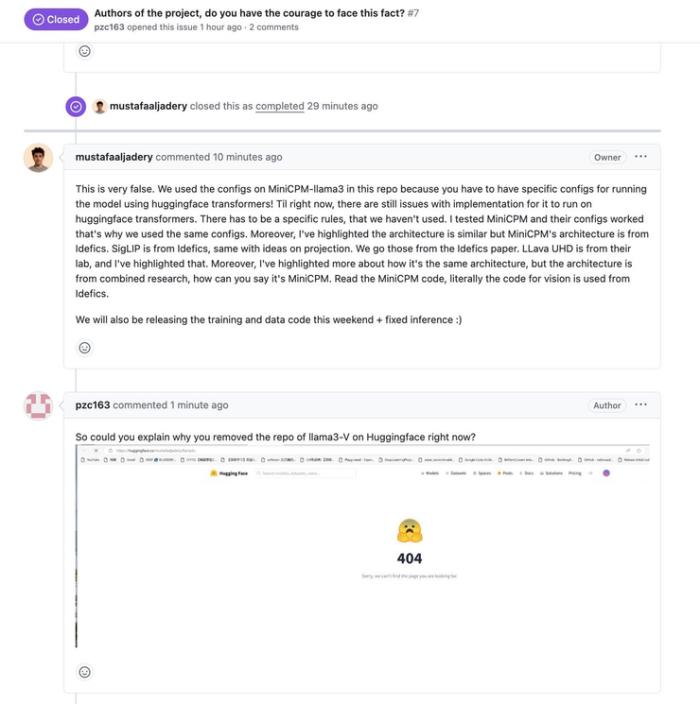
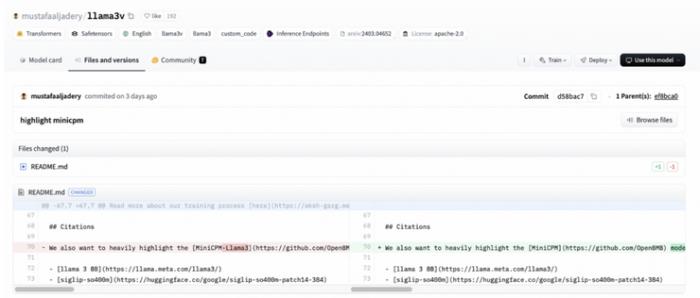
并且將原來 readme 里引用致謝 「MiniCPM-Llama3 」改為了「致謝 MiniCPM」:
但根據網友的復盤、梳理,Llama3V 并非只是簡單的借鑒,而是有 4 點證據能充分表明其「套殼」了 MiniCPM-Llama3-V 2.5。
證據 1:
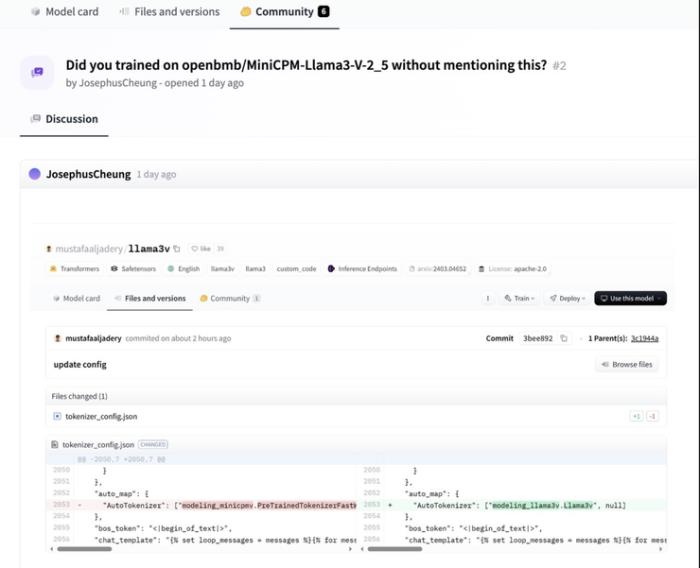
Llama3V 項目使用了與 MiniCPM-Llama3-V 2.5 項目完全相同的模型結構和代碼實現。
Llama3-V 的模型結構和配置文件與 MiniCPM-Llama3-V 2.5 完全相同,只是變量名不同。
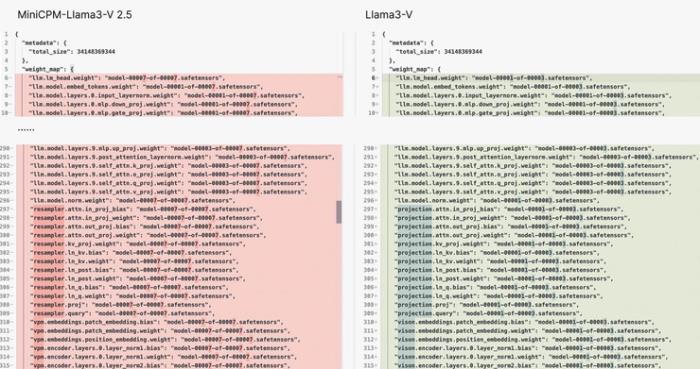
圖左為 MiniCPM-Llama3-V 2.5,圖右為 Llama3V
Llama3-V 的代碼是通過對 MiniCPM-Llama3-V 2.5 的代碼進行格式調整和變量重命名得到的,包括但不限于圖像切片方式、tokenizer、重采樣器和數據加載:

證據 2:
Llama3V 團隊稱其「引用了 LLaVA-UHD 作為架構」,但事實是 Llama3V 與 MiniCPM-Llama3-V 2.5 結構完全相同,但在空間模式等多方面卻與 LLaVA-UHD 有較大差異。
Llama3-V 具有與 MiniCPM-Llama3V 2.5 相同的標記器(tokenizer),包括 MiniCPM-Llama3-V 2.5 新定義的特殊標記:
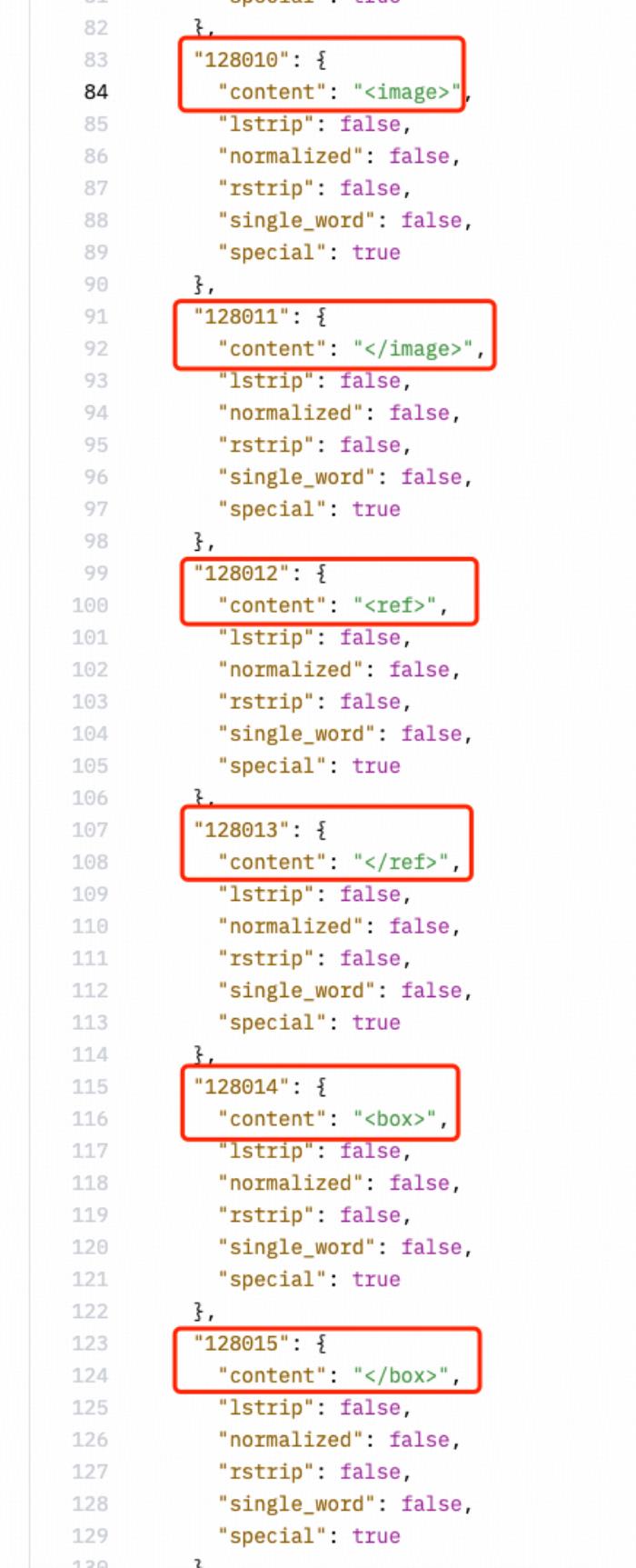
證據 3:
Llama3V 作者曾在 Hugging Face 上直接導入了 MiniCPM-V 的代碼,后改名為 Llama3V。事件發酵后,AI 科技評論打開 Hugging Face 頁面發現已經「404」:
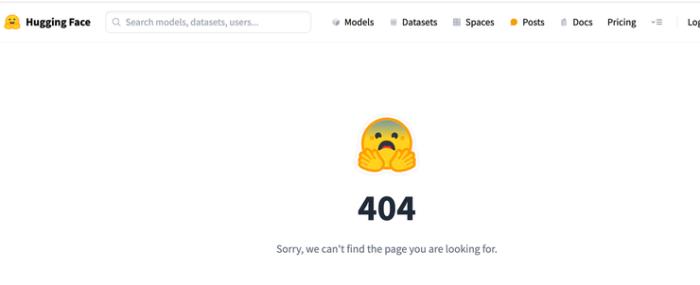
https://huggingface.co/mustafaaljadery/llama3v/commit/3bee89259ecac051d5c3e58ab619e3fafef20ea6Llama3V
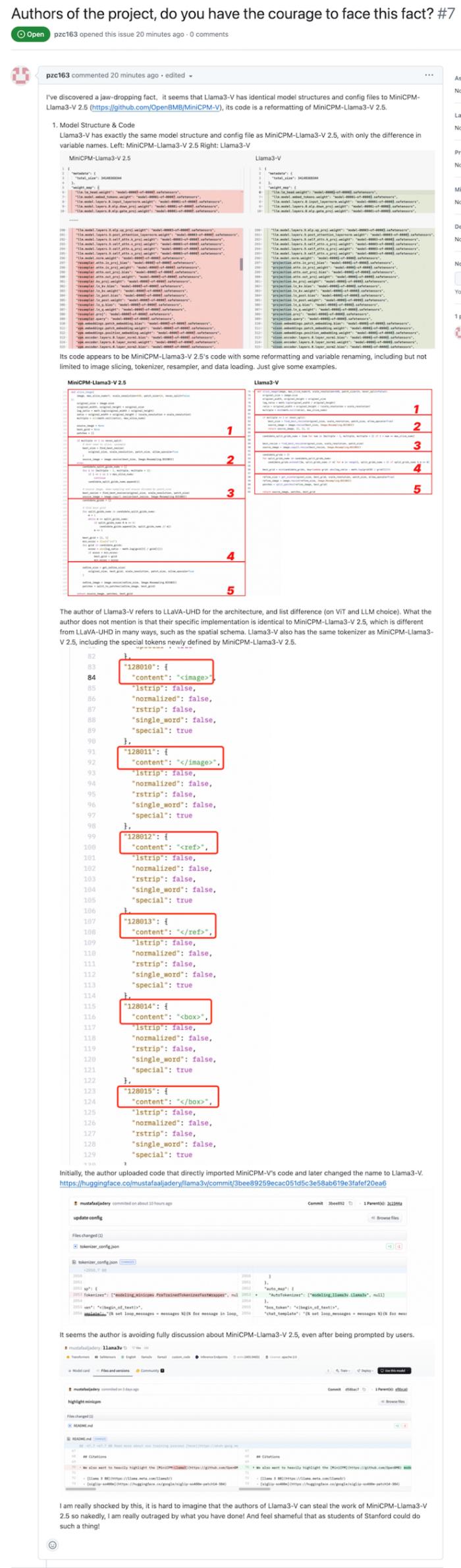
作者回應刪除 Hugging Face 倉庫的原因是「修復模型的推理問題」,并稱他們「嘗試使用 MiniCPM-Llama3 的配置,但并沒有用」:
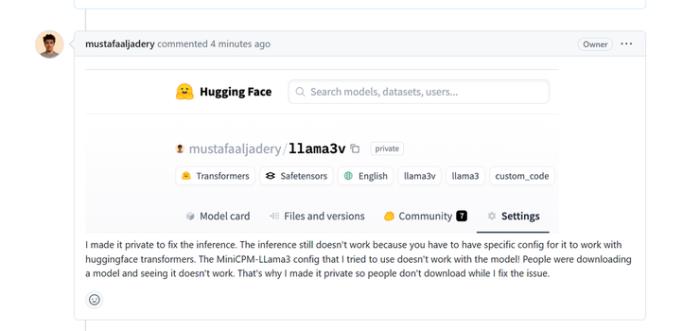
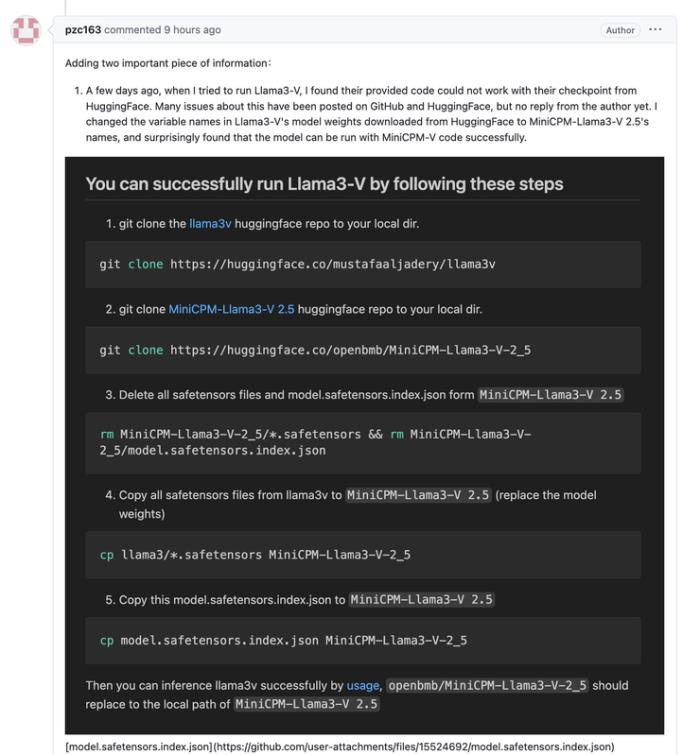
戲劇效果拉滿的是,該網友隨后貼出了如何使用 MiniCPM-Llama3-V 的代碼,跑通 Llama3V 模型推理的詳細步驟。
當 Llama3V 的作者被詢問如何能在 MinicPM-Llama3-V2.5 發布之前就使用它的 tokenizer 時(因為其一開始稱他們在 MinicPM-Llama3-V2.5 發布前就已經開始了 Llama3V 的研究),Llama3V 的作者開始撒謊,稱是從已經發布的上一代 MinicPM-V-2 項目里拿的tokenizer:
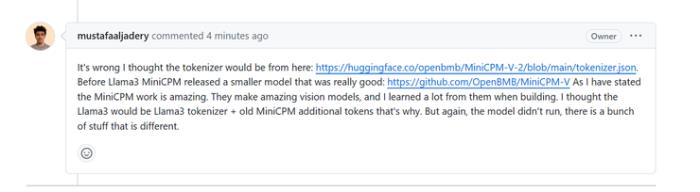
但事實是,據 AI 科技評論向面壁團隊了解,MiniCPM-V-2 的 tokenizer 與 MinicPM-Llama3-V2.5 完全不同,在Huggingface 里是兩個文件,「既不是同一個 tokenizer 件,文件大小也完全不同」。
MinicPM-Llama3-v2.5 的 tokenizer 是 Llama3 的 tokenizer 加上 MiniCPM-V 系列模型的一些特殊 token 組成,MiniCPM-v2 因為在 Llama3 開源之前就發布,所以不會有 Llama3 的 tokenizer :
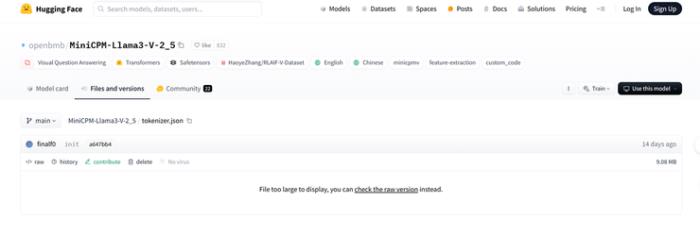
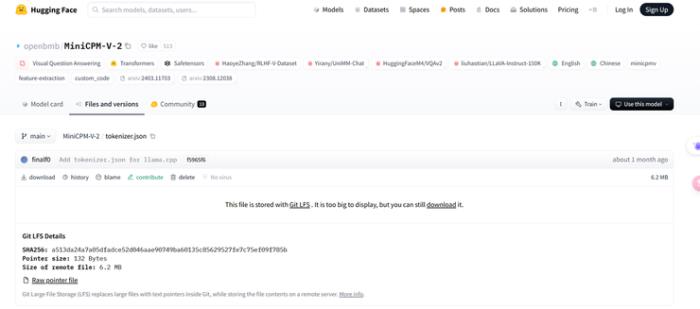
證據 4:
Llama3V 的作者刪除了 GitHub 上的相關 issue,并似乎不完全理解 MinicPM-Llama3-V2.5 的架構或 Llama3V 自己的代碼。
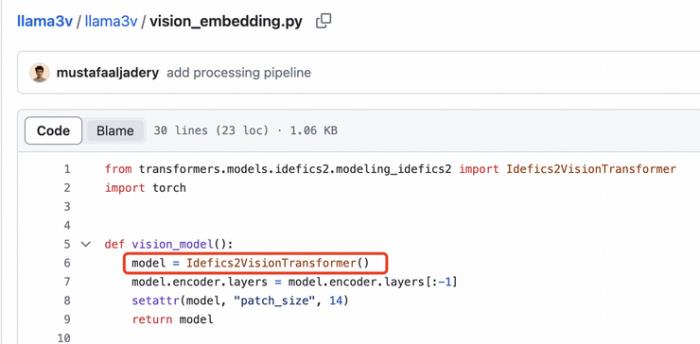
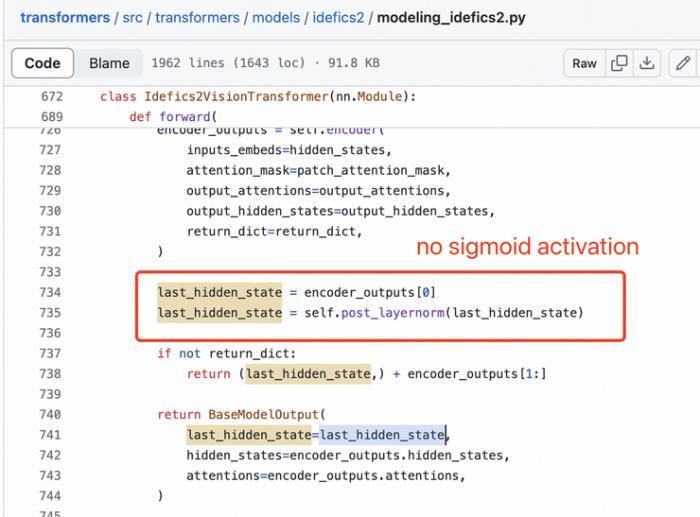
Perceiver重采樣器是一個單層的交叉注意力機制,而不是兩層自注意力機制。SigLIP 的 Sigmoid 激活函數并未用于訓練多模態大型語言模型,而僅用于 SigLIP 的預訓練。
但 Llama3V 在論文中的介紹卻說其采用了兩層自注意力機制:

而 MiniCPM-Llama3-V 2.5 和 Llama3V 代碼如下,體現的卻是單層交叉注意力機制:
Llama3-V:
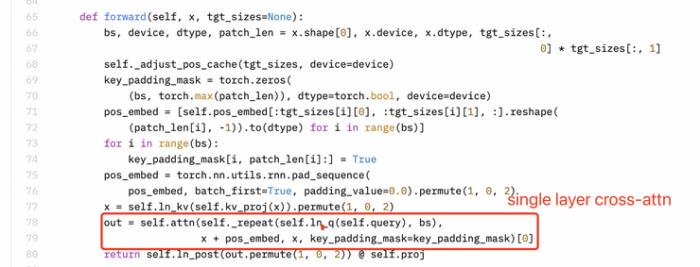
MiniCPM-Llama3-V 2.5:

且視覺特征提取不需要激活 sigmoid:

2、推特輿論發酵,面壁回應
6 月 2 日下午,該事件開始在推特上發酵,MiniCPM-V 的作者親自發帖,表示「震驚」,因為斯坦福的 Llama3V 模型居然也能識別「清華簡」。
據 AI 科技評論向面壁團隊了解,「清華簡」是清華大學于 2008 年 7 月收藏的一批戰國竹簡的簡稱;識別清華簡是 MiniCPM-V 的「胎記」特征。該訓練數據的采集和標注均由面壁智能和清華大學自然語言處理實驗室團隊內部完成,相關數據尚未對外公開。
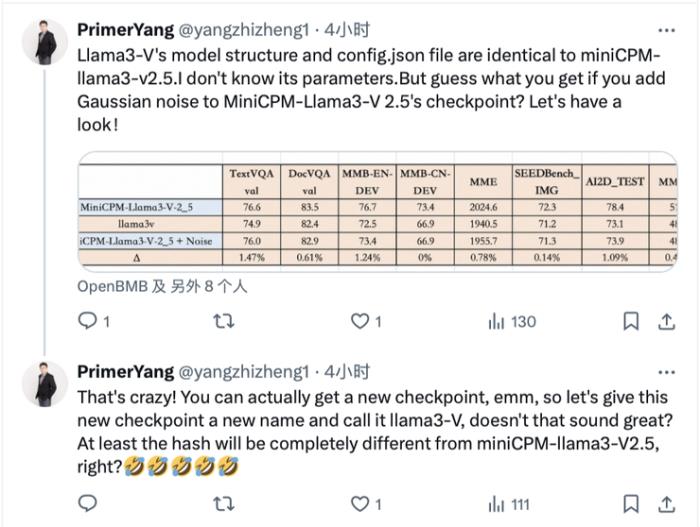
斯坦福的 Llama3V 模型表現與 MiniCPM-Llama3-V 2.5 檢查點的加噪版本高度相似:
以下是面壁團隊成果與 Llama3V 對「清華簡」的識別對比。結果顯示,兩個模型不僅正確的地方一模一樣、錯誤的地方也雷同:

Q:請識別圖像中的竹簡字?
MiniCPM-Llama3-V 2.5:民
Llama3-V:民
GT:民
錯誤識別示例:

Q:請識別圖像中的竹簡字?
MiniCPM-Llama3-V 2.5:君子
Llama3-V:君子
GT:甬
以下是在 1000 個清華簡字體上的識別效果:
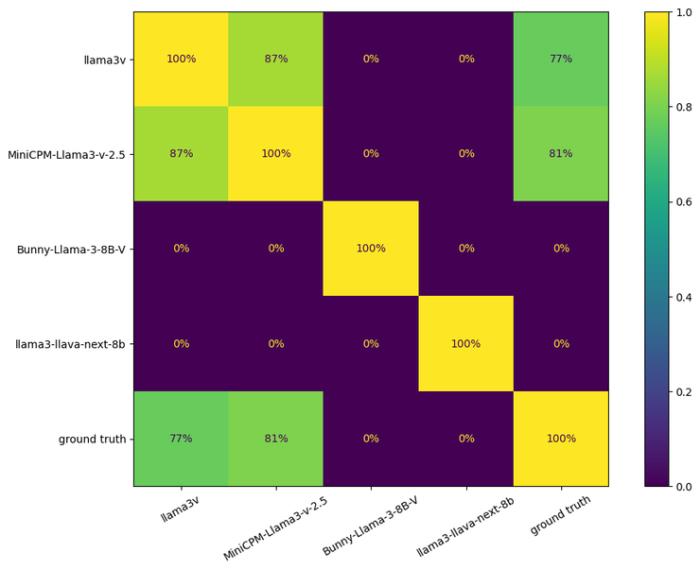
可以看到,Llama3V 與 MiniCPM-Llama3-V 2.5 的重疊高達 87%,且兩個模型的錯誤分布律高度相似:Llama3V 的錯誤率為 236,MiniCPM-Llama3-V 2.5 的錯誤率是 194,兩個模型在 182 個錯誤識別上相同。
同時,兩個模型在清華簡上的高斯噪聲也同樣高度相似:
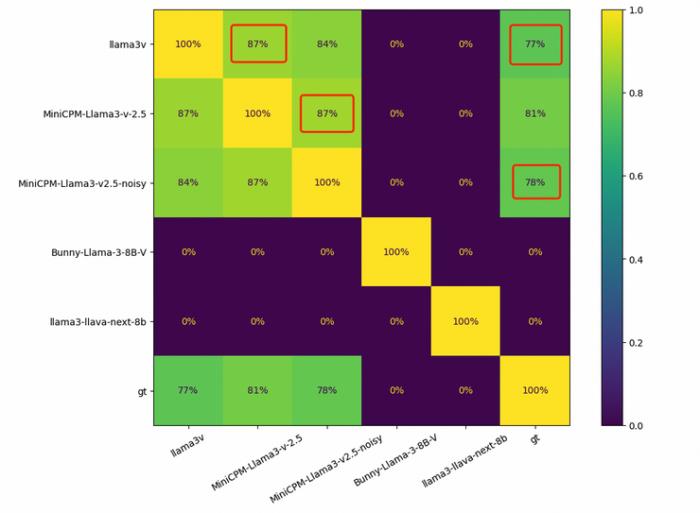
此外,Llama3V 的 OCR 識別能力在中文字上也與 MiniCPM-Llama3-V 2.5 高度相似。對此,面壁團隊表示,他們很好奇斯坦福團隊是如何只用「500 美元就能訓練出這么高深的模型性能」。
根據公開信息顯示,Llama3V 的兩位作者 Siddharth Sharma 與 Aksh Garg 是斯坦福大學計算機系的本科生,曾發表過多篇機器學習領域的論文。
其中,Siddharth Sharma 曾在牛津大學訪問、在亞馬遜實習;Aksh Garg 也曾在 SpaceX 實習。
這件事反映出,AI 研究的投機分子不分國度。
同時,也反映出,中國科研團隊的開源大模型實力已經沖出國門,逐漸被越來越多國際知名的機構與開發者所關注、學習。
中國大模型不僅在追趕世界頂尖機構,也正在成為被世界頂尖機構學習的對象。
由此可見,今后看客們審視國內外的大模型技術實力對比,應該多一份民族自信、少一點崇洋媚外,將關注度多聚焦在國內的原創技術上。
最后,一句話總結:投機不可取,永爭創新一。
相關推薦

- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
