

 新火種
2024-05-28
新火種
2024-05-28 


摩爾線程攜手無問芯穹:0到1端到端大模型實訓在國產GPU首次突破
摩爾線程聯合無問芯穹宣布,雙方在近日正式完成基于國產全功能GPU千卡集群的3B規模大模型實訓。該模型名為“MT-infini-3B”,在摩爾線程夸娥(KUAE)千卡智算集群與無問芯穹AIStudio PaaS平臺(https://cloud.infini-ai.com/aistudio)上完成了高效穩定的訓練。本次實訓充分驗證了夸娥千卡智算集群在大模型訓練場景下的可靠性,同時也在行業內率先開啟了國產大語言模型與國產GPU千卡智算集群深度合作的新范式。
MT-infini-3B模型訓練總用時13.2天,經過精度調試,實現全程穩定訓練不中斷,集群訓練穩定性達到100%,千卡訓練和單機相比擴展效率超過90%。目前,實訓出來的MT-infini-3B性能在同規模模型中躋身前列,相比在國際主流硬件上訓練而成的其他模型,在C-Eval,MMLU,CMMLU等3個測試集上均實現性能領先。
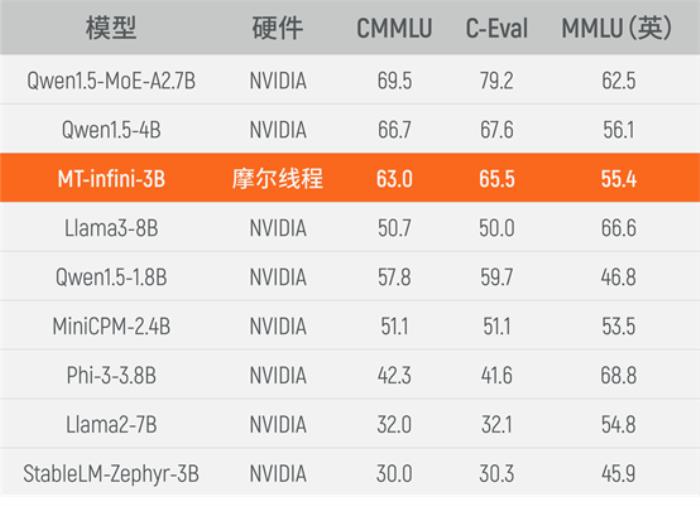
MT-infini-3B性能表現
無問芯穹聯合創始人兼CEO夏立雪表示:“國內大模型與國產芯片的軟硬件協同發展,最終目標是構建一個成熟的生態系統。無問芯穹正在打造‘M種模型’和‘N種芯片’間的‘M×N’中間層產品,實現多種大模型算法在多元芯片上的高效、統一部署。摩爾線程是第一家接入無問芯穹并進行千卡級別大模型訓練的國產GPU公司,而‘MT-infini-3B’的訓練是行業內首次實現基于國產GPU芯片從0到1的端到端大模型實訓案例。”
摩爾線程創始人兼CEO張建中表示:“無問芯穹在夸娥千卡智算集群上實現的從零開始的大模型訓練,不僅是對摩爾線程技術實力的有力認證,更是實現了國內大模型訓練的國產化閉環。摩爾線程夸娥千卡智算集群以全功能GPU為底座,提供軟硬一體化的全棧解決方案,具備高兼容性、高穩定性、高擴展性等綜合優勢,我們致力于成為AGI時代大模型訓練堅實可靠的先進基礎設施。”
此前,摩爾線程與無問芯穹已達成深度戰略合作。無問芯穹大模型開發與服務平臺“無穹Infini-AI”和摩爾線程大模型智算千卡集群夸娥已完成系統級融合適配,該平臺可以靈活調用夸娥的集群能力以完成大模型的訓練、微調與推理任務。未來,雙方還將開展更多適配與測試,推動國產大模型技術的快速發展與應用普及,為中國人工智能產業的蓬勃發展貢獻力量。
關于無問芯穹
無問芯穹(Infinigence AI)依托行業領先且經過驗證的AI計算優化能力與算力解決方案,追求大模型落地的極致能效。打造“M種模型”和“N種芯片”間的“M×N”中間層產品,實現多種大模型算法在多元芯片上的高效、統一部署。鏈接上下游,共建AGI時代大模型基礎設施,加速AGI落地千行百業。
關于摩爾線程
摩爾線程是一家以全功能GPU芯片設計為主的集成電路高科技公司,能夠為廣泛的科技生態合作伙伴提供強大的計算加速能力,致力于打造為下一代互聯網提供多元算力的元計算平臺。
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
