

 新火種
2023-09-26
新火種
2023-09-26 


使用TensorFlow進行語音識別.js – 語音命令

當我還是個孩子的時候,幾乎每個超級英雄都有一臺語音控制的計算機。所以你可以想象我第一次遇到Alexa對我來說是一次深刻的經歷。我心里的孩子非常高興和興奮。當然,然后我的工程直覺開始發揮作用,我分析了這些設備是如何工作的。
事實證明,他們有神經網絡來處理這個復雜的問題。事實上,神經網絡大大簡化了這個問題,以至于今天使用Python在計算機上制作這些應用程序之一非常容易。但情況并非總是如此。第一次嘗試是在 1952 年進行的。由三位貝爾實驗室研究人員撰寫。
他們建立了一個具有10個單詞詞匯的單揚聲器數字識別系統。然而,到1980年代,這一數字急劇增長。詞匯量增長到20,000個單詞,第一批商業產品開始出現。Dragon Dictate是首批此類產品之一,最初售價為9,000美元。Alexa今天更實惠,對吧?
但是,今天我們可以在瀏覽器中使用Tensorflo.js執行語音識別。在本文中,我們將介紹:
遷移學習語音識別如何工作?演示使用Tensorflow實現.js1. 遷移學習
從歷史上看,圖像分類是普及深度神經網絡的問題,尤其是視覺類型的神經網絡——卷積神經網絡(CNN)。今天,遷移學習用于其他類型的機器學習任務,如NLP和語音識別。我們不會詳細介紹什么是 CNN 以及它們是如何工作的。然而,我們可以說CNN在2012年打破了ImageNet大規模視覺識別挑戰賽(ILSVRC)的記錄后得到了普及。
該競賽評估大規模對象檢測和圖像分類的算法。他們提供的數據集包含 1000 個圖像類別和超過 1 萬張圖像。圖像分類算法的目標是正確預測對象屬于哪個類。自2年以來。本次比賽的每位獲勝者都使用了CNN。
訓練深度神經網絡可能具有計算性和耗時性。要獲得真正好的結果,您需要大量的計算能力,這意味著大量的GPU,這意味著......嗯,很多錢。當然,您可以訓練這些大型架構并在云環境中獲得SOTA結果,但這也非常昂貴。
有一段時間,這些架構對普通開發人員不可用。然而,遷移學習的概念改變了這種情況。特別是,對于這個問題,我們今天正在解決 - 圖像分類。今天,我們可以使用最先進的架構,這些架構在 ImageNet 競賽中獲勝,這要歸功于遷移學習和預訓練模型。
1.1 預訓練模型
此時,人們可能會想知道“什么是預訓練模型?從本質上講,預訓練模型是以前在大型數據集(例如 ImageNet 數據集)上訓練的保存網絡 。 有兩種方法可以使用它們。您可以將其用作開箱即用的解決方案,也可以將其與遷移學習一起使用。 由于大型數據集通常用于某些全局解決方案,因此您可以自定義預先訓練的模型并將其專門用于某些問題。
通過這種方式,您可以利用一些最著名的神經網絡,而不會在訓練上浪費太多時間和資源。此外,您還可以 通過修改所選圖層的行為來微調這些模型。整個想法圍繞著使用較低層的預訓練CNN模型,并添加額外的層,這些層將為特定問題定制架構。
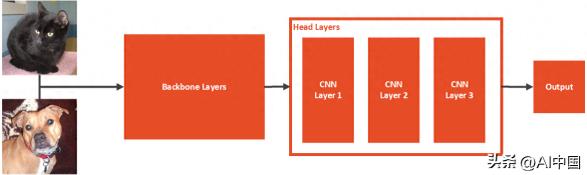
從本質上講,嚴肅的遷移學習模型通常由兩部分組成。我們稱它們為骨干和頭腦。 主干通常是在 ImageNet 數據集上預先訓練的深度架構,沒有頂層。Head 是圖像分類模型的一部分,用于預測自定義類。
這些層將添加到預訓練模型的頂部。有了這些系統,我們有兩個階段:瓶頸和培訓階段。在瓶頸階段,特定數據集的圖像通過主干架構運行,并存儲結果。在訓練階段,來自主干的存儲輸出用于訓練自定義層。

有幾個領域適合使用預先訓練的模型,語音識別就是其中之一。此模型稱為語音命令識別器。從本質上講,它是一個JavaScript模塊,可以識別由簡單英語單詞組成的口語命令。
默認詞匯“18w”包括以下單詞:從“零”到“九”、“向上”、“向下”、“向左”、“向右”、“開始”、“停止”、“是”、“否”的數字。還提供其他類別的“未知單詞”和“背景噪音”。除了已經提到的“18w”字典之外,還有更小的字典“directional4w”可用。它只包含四個方向詞(“上”、“下”、“左”、“右”)。
2. 語音識別如何工作?
當涉及到神經網絡和音頻的組合時,有很多方法。語音通常使用某種遞歸神經網絡或LSTM來處理。但是,語音命令識別器使用稱為卷積神經網絡的簡單體系結構,用于小占用量關鍵字發現。
這種方法基于我們在上一篇文章中研究的圖像識別和卷積神經網絡。乍一看,這可能會令人困惑,因為音頻是一個跨時間的一維連續信號,而不是 2D 空間問題。
2.1 譜圖
此體系結構使用頻譜圖。這是信號頻率頻譜隨時間變化的視覺表示。從本質上講,定義了單詞應該適合的時間窗口。
這是通過將音頻信號樣本分組到段來完成的。完成此操作后,將分析頻率的強度,并定義具有可能單詞的段。然后將這些片段轉換為頻譜圖,例如用于單詞識別的單通道圖像:

然后,使用這種預處理制作的圖像被饋送到多層卷積神經網絡中。
3. 演示
您可能已經注意到,此頁面要求您允許使用麥克風。這是因為我們在此頁面中嵌入了實現演示。為了使此演示正常工作,您必須允許它使用麥克風。
現在,您可以使用命令“向上”,“向下”,“向左”和“右”在下面的畫布上繪制。繼續嘗試一下:
4. 使用TensorFlow實現.js
4.1 網頁文件
首先,讓我們看一下我們實現的 index.html 文件。在上一篇文章中,我們介紹了幾種安裝TensorFlow.js的方法。其中之一是將其集成到HTML文件的腳本標記中。這也是我們在這里的做法。除此之外,我們需要為預訓練的模型添加一個額外的腳本標記。以下是索引.html的外觀:
TensorFlow.js Speech Recognition
Using pretrained models for speech recognition
包含此實現的 JavaScript 代碼位于 script.js 中。此文件應與 index.html 文件位于同一文件夾中。為了運行整個過程,您所要做的就是在瀏覽器中打開索引.html并允許它使用您的麥克風。
4.2 腳本文件
現在,讓我們檢查整個實現所在的 script.js 文件。以下是主運行函數的外觀:
async function run() { recognizer = speechCommands.create('BROWSER_FFT', 'directional4w'); await recognizer.ensureModelLoaded(); var canvas = document.getElementById("canvas"); var contex = canvas.getContext("2d"); contex.lineWidth = 10; contex.lineJoin = 'round'; var positionx = 400; var positiony = 500; predict(contex, positionx, positiony);}在這里我們可以看到應用程序的工作流程。首先,我們創建模型的實例并將其分配給全局變量識別器。我們使用“directional4w”字典,因為我們只需要“up”,“down”,“left”和“right”命令。
然后我們等待模型加載完成。如果您的互聯網連接速度較慢,這可能需要一些時間。完成后,我們初始化執行繪圖的畫布。最后,調用預測方法。以下是該函數內部發生的情況:
function calculateNewPosition(positionx, positiony, direction){ return { 'up' : [positionx, positiony - 10], 'down': [positionx, positiony + 10], 'left' : [positionx - 10, positiony], 'right' : [positionx + 10, positiony], 'default': [positionx, positiony] }[direction];}function predict(contex, positionx, positiony) { const words = recognizer.wordLabels(); recognizer.listen(({scores}) => { scores = Array.from(scores).map((s, i) => ({score: s, word: words[i]})); scores.sort((s1, s2) => s2.score - s1.score); var direction = scores[0].word; var [x1, y1] = calculateNewPosition(positionx, positiony, direction); contex.moveTo(positionx,positiony); contex.lineTo(x1, y1); contex.closePath(); contex.stroke(); positionx = x1; positiony = y1; }, {probabilityThreshold: 0.75});}這種方法正在做繁重的工作。從本質上講,它運行一個無限循環,其中識別器正在傾聽您正在說的話。請注意,我們正在使用參數 probabilityThreshold。
此參數定義是否應調用回調函數。實質上,僅當最大概率分數大于此閾值時,才會調用回調函數。當我們得到這個詞時,我們就得到了我們應該畫的方向。
然后我們使用函數 calculateNewPosition 計算線尾的坐標。該步長為 10 像素,這意味著行的長度將為 10 像素。您可以同時使用概率閾值和此長度值。獲得新坐標后,我們使用畫布繪制線條。就是這樣。很簡單,對吧?
結論
在本文中,我們看到了如何輕松使用預先訓練的 TensorFlow.js 模型。它們是一些簡單應用程序的良好起點。我們甚至構建了一個此類應用程序的示例,您可以使用它使用語音命令進行繪制。這很酷,可能性是無窮無盡的。當然,您可以進一步訓練這些模型,獲得更好的結果,并將它們用于更復雜的解決方案。這意味著,您可以真正利用遷移學習。然而,這是另一個時代的故事。
原文標題:Speech Recognition with TensorFlow.js – Voice Commands
原文鏈接:https://rubikscode.net/2022/05/11/drawing-with-voice-speech-recognition-with-tensorflow-js/
編譯:LCR
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
