

 新火種
2024-05-15
新火種
2024-05-15 


大神Karpathy強推,分詞領域必讀:自動釣魚讓大模型“發瘋”的token,來自Transformer作者創業公司
關于大模型分詞(tokenization),大神Karpathy剛剛推薦了一篇必讀新論文。
主題是:自動檢測大模型中那些會導致“故障”的token。

簡單來說,由于大模型tokenizer的創建和模型訓練是分開的,可能導致某些token在訓練中很少、甚至完全沒出現過。這些“訓練不足”(under-trained)的token會導致模型產生異常輸出。
最經典的例子,就是SolidGoldMagikarp——
這個單詞一度讓ChatGPT“胡言亂語”。只要prompt里包含這個詞,ChatGPT就開始文不對題,生成一些混亂的輸出:
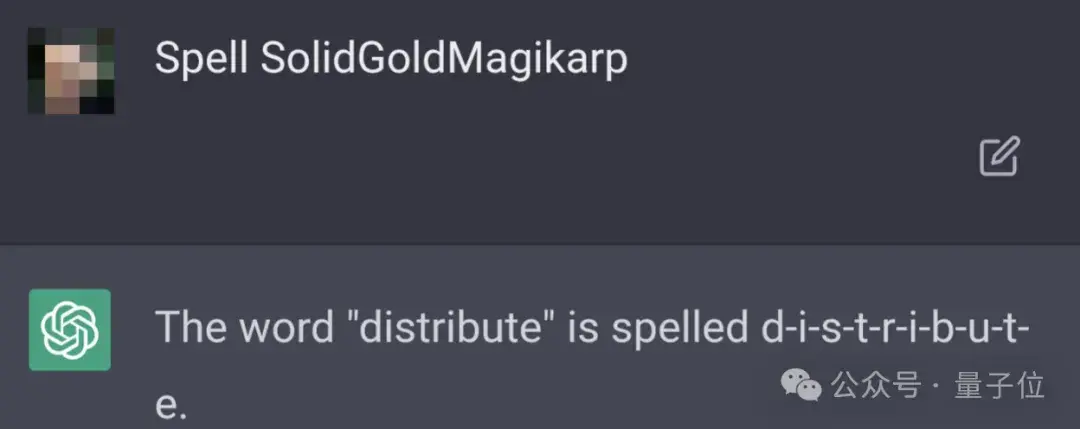
現在,來自Cohere的研究人員針對這個問題,提出檢測“故障”token的有效方法,他們還發現:在多個主流開源大語言模型上,包括Llama系列、Mistral系列在內,訓練不足的token都在不同程度上普遍存在。
p.s. Cohere是Transformer最年輕作者Aidan Gomez創辦的公司,此前推出了Command R系列開源大模型。去年6月,該公司估值達到了22億美元。
自動檢測LLM中訓練不足的token
研究人員提出的方法主要包括三個步驟。
首先,通過檢查tokenizer詞匯表并觀察其編碼/解碼行為,來分析tokenizer,找出其中特殊類別的token,比如不完整的UTF-8序列等。
然后,根據模型架構計算識別指標,找出嵌入向量異常的token,列入“訓練不足”候選名單。
舉個例子,對于tied embedding模型,利用一組已知的未使用的embedding,通過主成分分析去除unembedding矩陣中的常數成分。
接著計算其余token和這些未使用embedding的余弦距離,作為“訓練不足”指標。
而對于non-tied embedding的模型,可以直接采用embedding向量的L2范數來檢測。

最后,通過特定prompt來進行驗證,看看候選token們是否確實超出了訓練數據的分布,會引發異常輸出。

將該方法應用于多個主流的開源大語言模型后,研究人員發現,訓練不足能讓大模型“發瘋”的token在這些大模型上普遍存在,他們一口氣就挖出了數千個。

常見類型包括:
單字節token,尤其是UTF-8標準中未使用的字節,如0xF5-0xFF;字節對編碼(Byte-Pair Encoding,BPE)過程中,出現的一些未充分訓練的中間token。一些特殊字符,如
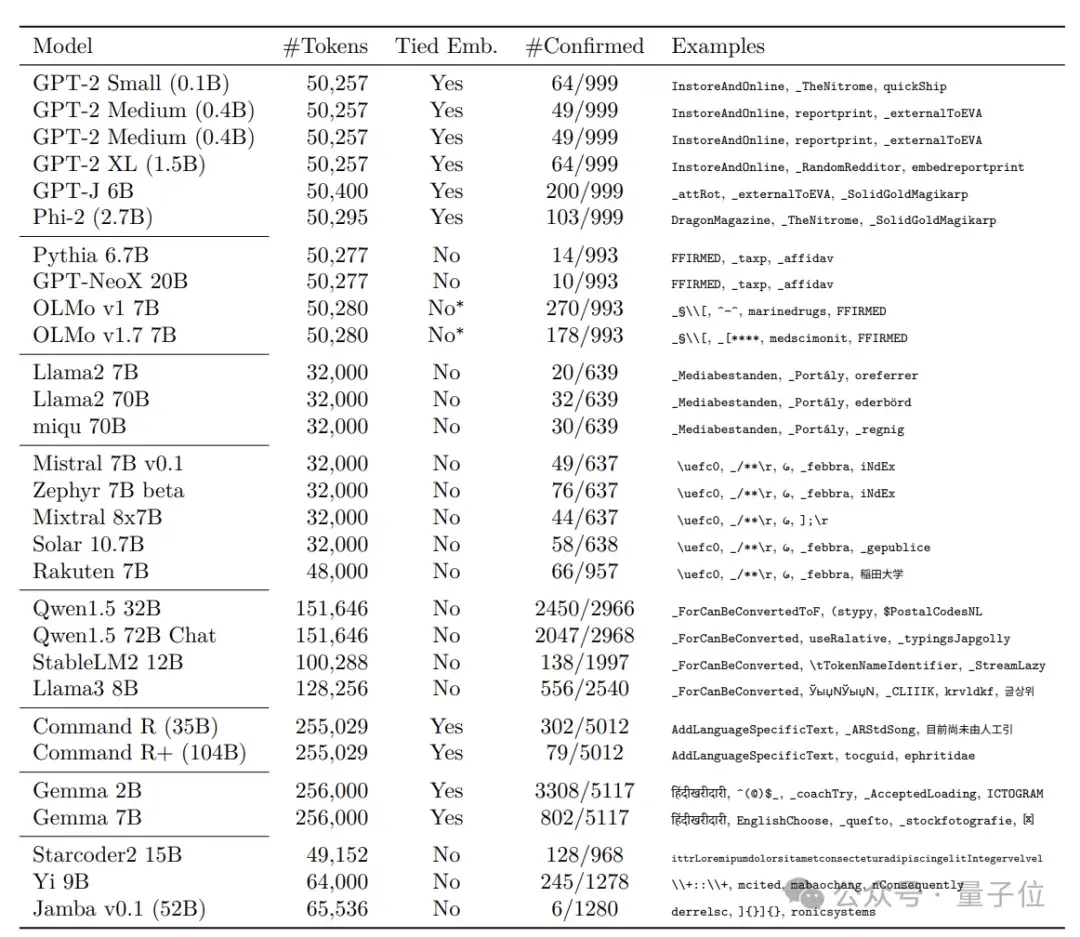
研究人員還發現,詞匯表較大的模型,“訓練不足”token的數量也會明顯增多。
因為大詞匯表意味著更稀疏的token分布和更細粒度的token切分,這必然會導致更多低頻token和無意義的token殘片,增加“訓練不足”token的比例。同時,大詞匯表也給模型訓練帶來了更大的優化難度。
值得注意的是,論文提到,基于相同tokenizer的模型表現相似,而不同的tokenizer實現、配置、訓練數據,會導致不同模型間“訓練不足”token的明顯差異。
論文認為,優化詞匯表結構和tokenizer算法,是解決token訓練不足問題的關鍵。
他們也提出了一些建議:
確保tokenizer訓練數據、模型訓練數據和模型推理中輸入數據的預處理完全相同。確保模型訓練數據和tokenizer對齊,尤其是在從頭訓練新的基礎模型時。對于單字節token,要么詞匯表包含所有256個字符且不允許重復,要么排除13個UTF-8中不出現的字符(0xC0/0xC1,0xF5-0xFF)。訓練tokenizer后,通過對詞匯表進行編碼和解碼來檢查無法訪問的token,以確保正確處理手動添加的token。在Hugging Face上發表tokenizer的“快速”和“慢速”版本時,確保它們輸出相同。訓練基礎模型時,在小型測試中檢查訓練不足的token,重新考慮分詞方法和數據。在不同語料庫上運行測試,也可以發現導致主訓練數據中“故障”輸入的預處理錯誤。
— 完 —
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
