

 新火種
2024-05-08
新火種
2024-05-08 



58行代碼把Llama3擴(kuò)展到100萬上下文,任何微調(diào)版都適用
堂堂開源之王Llama 3,原版上下文窗口居然只有……8k,讓到嘴邊的一句“真香”又咽回去了。
在32k起步,100k尋常的今天,這是故意要給開源社區(qū)留做貢獻(xiàn)的空間嗎?

開源社區(qū)當(dāng)然不會(huì)放過這個(gè)機(jī)會(huì):
現(xiàn)在只需58行代碼,任何Llama 3 70b的微調(diào)版本都能自動(dòng)擴(kuò)展到1048k(一百萬)上下文。
背后是一個(gè)LoRA,從擴(kuò)展好上下文的Llama 3 70B Instruct微調(diào)版本中提取出來,文件只有800mb。
接下來使用Mergekit,就可以與其他同架構(gòu)模型一起運(yùn)行或直接合并到模型中。
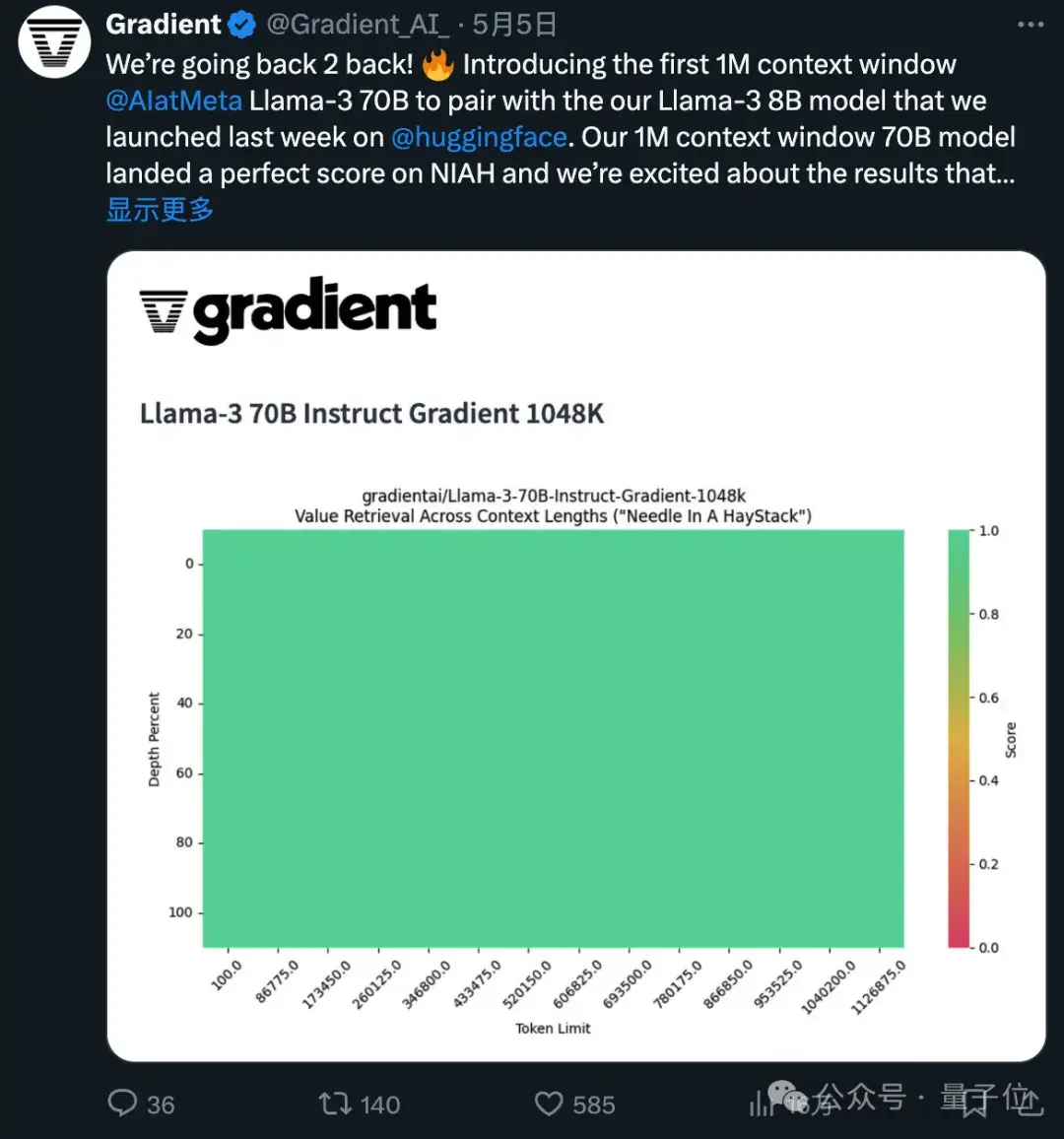
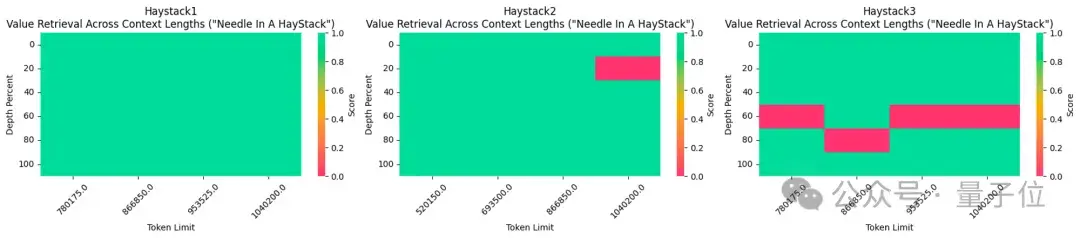
所使用的1048k上下文微調(diào)版本,剛剛在流行的大海撈針測(cè)試中達(dá)到全綠(100%準(zhǔn)確率)的成績。
不得不說,開源的進(jìn)步速度是指數(shù)級(jí)的。
 1048k上下文LoRA怎么煉成的
1048k上下文LoRA怎么煉成的
首先1048k上下文版Llama 3微調(diào)模型來自Gradient AI,一個(gè)企業(yè)AI解決方案初創(chuàng)公司。

而對(duì)應(yīng)的LoRA來自開發(fā)者Eric Hartford,通過比較微調(diào)模型與原版的差異,提取出參數(shù)的變化。
他先制作了524k上下文版,隨后又更新了1048k版本。
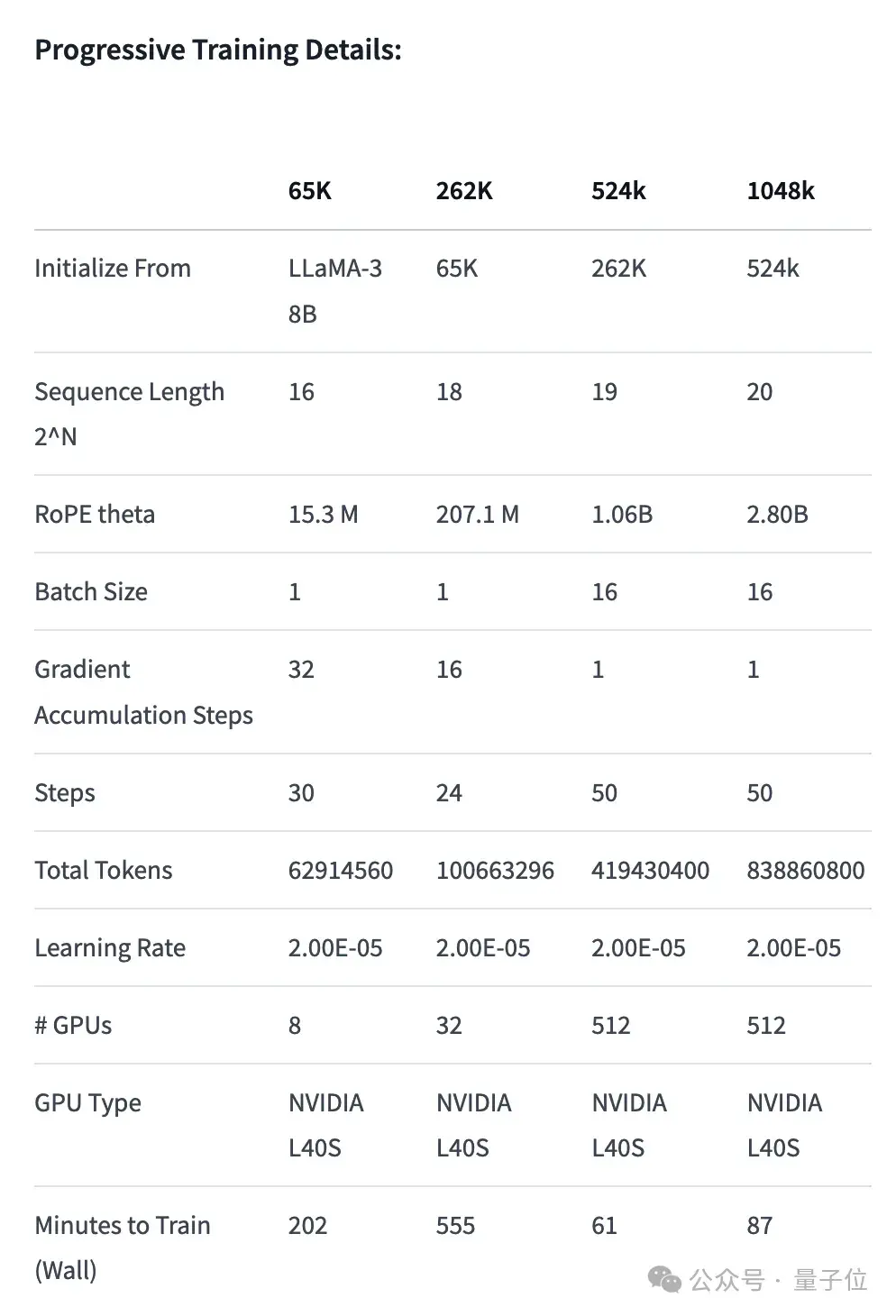
首先,Gradient團(tuán)隊(duì)先在原版Llama 3 70B Instruct的基礎(chǔ)上繼續(xù)訓(xùn)練,得到Llama-3-70B-Instruct-Gradient-1048k。
具體方法如下:
調(diào)整位置編碼:用NTK-aware插值初始化RoPE theta的最佳調(diào)度,進(jìn)行優(yōu)化,防止擴(kuò)展長度后丟失高頻信息漸進(jìn)式訓(xùn)練:使用UC伯克利Pieter Abbeel團(tuán)隊(duì)提出的Blockwise RingAttention方法擴(kuò)展模型的上下文長度
值得注意的是,團(tuán)隊(duì)通過自定義網(wǎng)絡(luò)拓?fù)湓赗ing Attention之上分層并行化,更好地利用大型GPU集群來應(yīng)對(duì)設(shè)備之間傳遞許多KV blocks帶來的網(wǎng)絡(luò)瓶頸。
最終使模型的訓(xùn)練速度提高了33倍。
長文本檢索性能評(píng)估中,只在最難的版本中,當(dāng)“針”藏在文本中間部分時(shí)容易出錯(cuò)。

有了擴(kuò)展好上下文的微調(diào)模型之后,使用開源工具M(jìn)ergekit比較微調(diào)模型和基礎(chǔ)模型,提取參數(shù)的差異成為LoRA。
同樣使用Mergekit,就可以把提取好的LoRA合并到其他同架構(gòu)模型中了。
合并代碼也由Eric Hartford開源在GitHub上,只有58行。
目前尚不清楚這種LoRA合并是否適用于在中文上微調(diào)的Llama 3。
不過可以看到,中文開發(fā)者社區(qū)已經(jīng)關(guān)注到了這一進(jìn)展。
相關(guān)推薦



- 免責(zé)聲明
- 本文所包含的觀點(diǎn)僅代表作者個(gè)人看法,不代表新火種的觀點(diǎn)。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對(duì)本文可能提及或鏈接的任何項(xiàng)目不表示認(rèn)可。 交易和投資涉及高風(fēng)險(xiǎn),讀者在采取與本文內(nèi)容相關(guān)的任何行動(dòng)之前,請(qǐng)務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨(dú)立判斷。新火種不對(duì)因依賴本文觀點(diǎn)而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
