

 新火種
2024-04-02
新火種
2024-04-02 


0門檻免費商用!孟子3-13B大模型正式開源,萬億token數據訓練
瀾舟科技官宣:孟子3-13B大模型正式開源!
這一主打高性價比的輕量化大模型,面向學術研究完全開放,并支持免費商用。

在MMLU、GSM8K、HUMAN-EVAL等各項基準測評估中,孟子3-13B都表現出了不錯的性能。
尤其在參數量20B以內的輕量化大模型領域,在中英文語言能力方面尤為突出,數學和編程能力也位于前列。
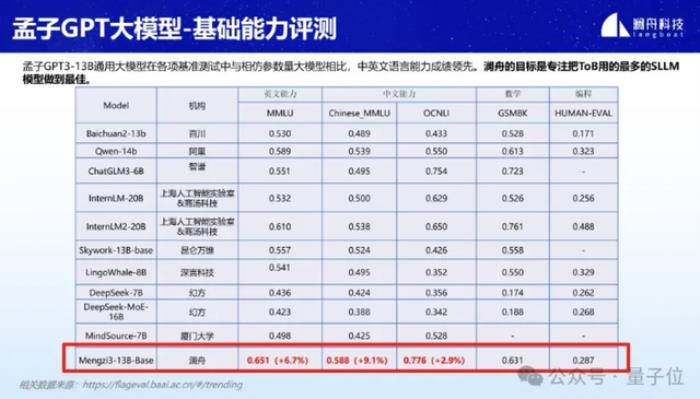
據介紹,孟子3-13B大模型是基于Llama架構,數據集規模高達3T Tokens。
語料精選自網頁、百科、社交、媒體、新聞,以及高質量的開源數據集。通過在萬億tokens上進行多語言語料的繼續訓練,模型的中文能力突出并且兼顧多語言能力。
孟子3-13B大模型開源
只需兩步,就能使用孟子3-13B大模型了。
首先進行環境配置。
pip install -r requirements.txt
然后快速開始。
import torchfrom transformers import AutoModelForCausalLM, AutoTokenizertokenizer =AutoTokenizer.from_pretrained(“Langboat/Mengzi3-13B-Base”, use_fast=False, trust_remote_code=True)model =AutoModelForCausalLM.from_pretrained(“Langboat/Mengzi3-13B-Base”, device_map=”auto”, trust_remote_code=True)inputs = tokenizer(‘指令:回答以下問題。輸入:介紹一下孟子。輸出:’, return_tensors=’pt’)if torch.cuda.is_available():inputs = inputs.to(‘cuda’)pred = model.generate(**inputs, max_new_tokens=512, repetition_penalty=1.01, eos_token_id=tokenizer.eos_token_id)print(tokenizer.decode(pred[0], skip_special_tokens=True))
此外,他們還提供了一個樣例代碼,可用于基礎模型進行單輪交互推理。
cd examplespython examples/base_streaming_gen.py –model model_path –tokenizer tokenizer_path
如果想要進行模型微調,他們也提供了相關文件和代碼。
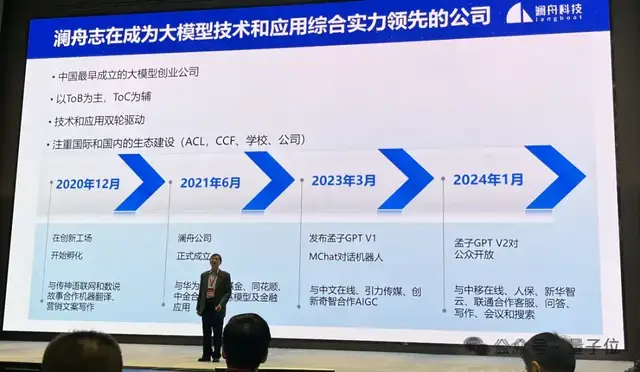
事實上,早在3月18日的瀾舟大模型技術和產品發布會現場,就透露了孟子3-13B大模型的諸多細節。
當時他們表示,孟子3-13B大模型訓練已經完成。
對于選擇13B版本的原因,周明解釋道:
首先,瀾舟明確以服務ToB場景為主,ToC為輔。
實踐發現,ToB場景使用頻率最高的大模型參數量多為7B、13B、40B、100B,整體集中在10B-100B之間。
其次,在這個區間范圍內,從ROI(投資回報率)角度來講,既滿足場景需求,又最具性價比。
因此,在很長一段時間內,瀾舟的目標都是在10B-100B參數規模范圍內,打造優質的行業大模型。
作為國內最早一批大模型創業團隊,去年3月,瀾舟就發布了孟子GPT V1(MChat)。
今年1月,孟子大模型GPT V2(含孟子大模型-標準、孟子大模型-輕量、孟子大模型-金融、孟子大模型-編碼)對公眾開放。
好了,感興趣的朋友可戳下方鏈接體驗一下。
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
