

 新火種
2024-03-01
新火種
2024-03-01 


Mamba正式被ICLR拒收!“年度最佳技術原理解讀”卻火了
量子位 | 公眾號 QbitAI
懸著的心終于死了:
被尊為Transformer挑戰者的Mamba,已正式被ICLR拒絕。
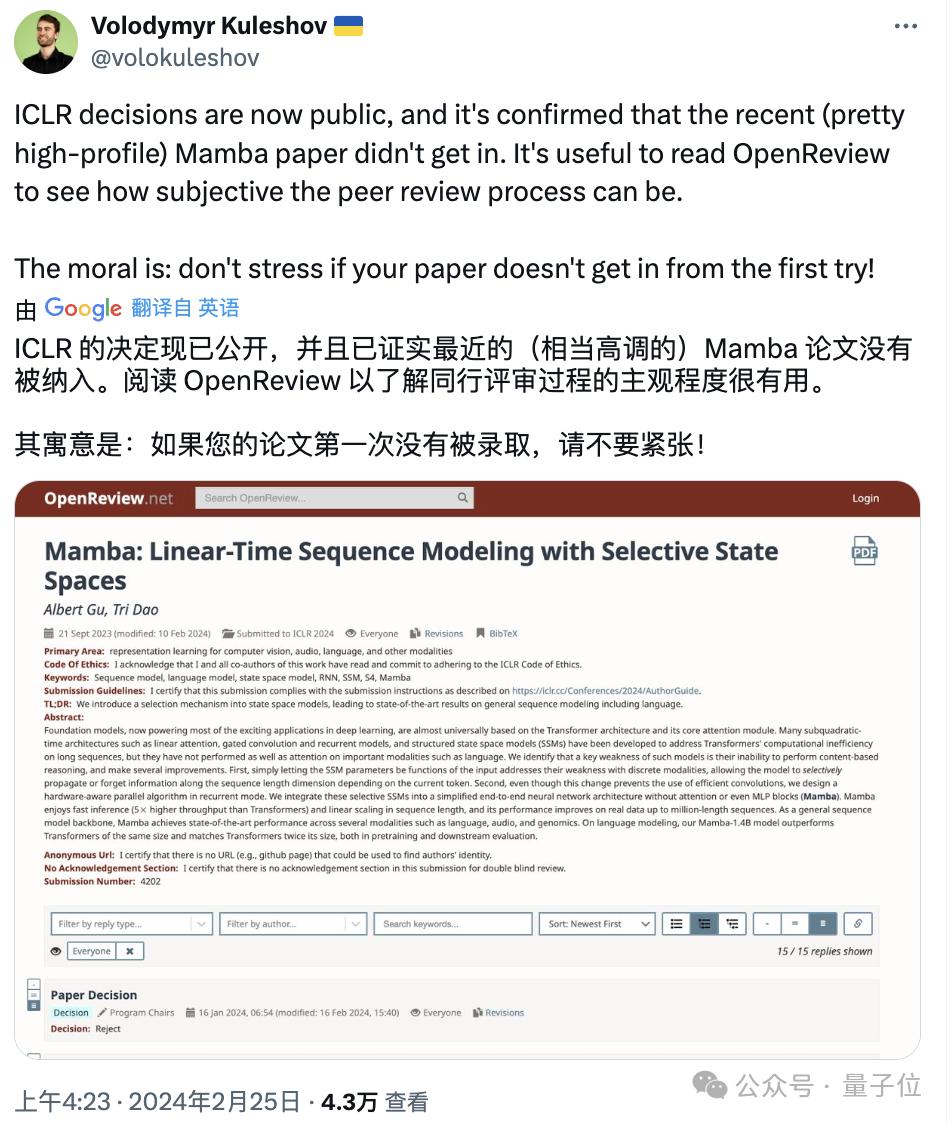
(之前被“初拒”后在學術圈引起軒然大波,轉為“待定(Decision Pending)”狀態)
但這位“頂流”的熱度豈受影響?
這不,一篇關于它的最新通俗解讀 (作者:Jack Cook,牛津互聯網研究院研究員,曾在MIT、英偉達、微軟工作),剛剛誕生,還在被網友們瘋狂點贊收藏。
有人甚至稱它為:
到目前為止的年度最佳(解讀)。

咱也不能錯過。
以下為原文精華傳送:
背景:S4架構
Mamba的架構主要基于S4,一種最新的狀態空間模型(SSM,state space model)架構。

其主要思想如下:
在較高層次上,S4學習如何通過中間狀態 h(t) 將輸入x(t) 映射到輸出 y(t) 上。
在此,由于SSM被設計于很好地處理連續數據,例如音頻、傳感器數據和圖像,因此x、y、t 是x的函數。
S4通過三個連續參數矩陣A、B和C將它們互聯,具體形式表現為以下兩個方程(Mamba論文中的1a和1b):
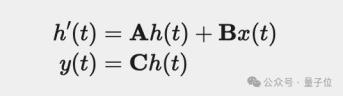
由于在實踐中,我們一般都是處理離散數據比如文本,這就需要我們對SSM進行離散化,通過使用特殊的第四個參數Δ,將連續參數A、B和C轉換為離散參數
、
和C 。
離散化后,我們可以通過這兩個方程(Mamba論文中的2a和2b)來表示SSM:

這些方程形成一個遞歸,情況類似于咱在RNN網絡中看到的一樣。在每個步驟t中,我們將前一個時間步ht?1的隱藏狀態與當前輸入xt相結合,以創建新的隱藏狀態ht。
下圖展示了它在預測句子中的下一個單詞時是如何工作的(我們預測“and”跟在“My name is Jack”之后)。

依據以此,我們本質上就可以使用S4作為遞歸神經網RNN來一次生成一個 token。
然而,S4真正酷的地方在于,你也可以將它用作卷積神經網絡CNN。
在上面的示例中,當我們擴展之前的離散方程來嘗試計算h3時,會發生什么?
為了簡單起見,我們假設x?1=0。
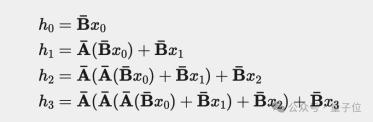
計算出h3后,我們可以將其代入y3的等式中來預測下一個單詞:
現在,請注意y3實際上可以計算為點積,其中右側向量是我們的輸入x:

由于參數
、
和C都是常數,因此我們可以預先計算左側向量并將其保存為卷積核
。這為我們提供了一種使用卷積計算y的簡單方法,如以下兩個方程所示(Mamba論文中的3a和3b):
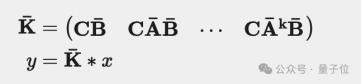
劃重點:這些循環和卷積形式(作者稱之為“RNN模式”和“CNN模式”)在數學上是等效的。
因此S4可以根據你需要它執行的操作進行變形,同時輸出沒有任何差異。
當然,CNN模式更適合訓練,RNN模式更適合推理。
第一個主要思想:可選性
這部分我們討論Mamba引入的第一個主要思想:可選性。讓我們回想一下定義S4離散形式的兩個方程:

注意,在S4中,我們的離散參數
、
和C是恒定的。然而,Mamba使這些參數根據輸入而變化。因此我們最終會得到這樣的結果:
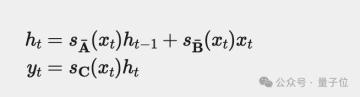
Mamba作者(Gu和Dao)認為,選擇性或輸入依賴性對于許多任務都很重要。
而本文的科普作者則認為:因為S4沒有選擇性,所以它被迫以完全相同的方式處理輸入的所有部分。
然而,當我們面對一句話時,其中有些單詞不可避免地比其他單詞更重要。
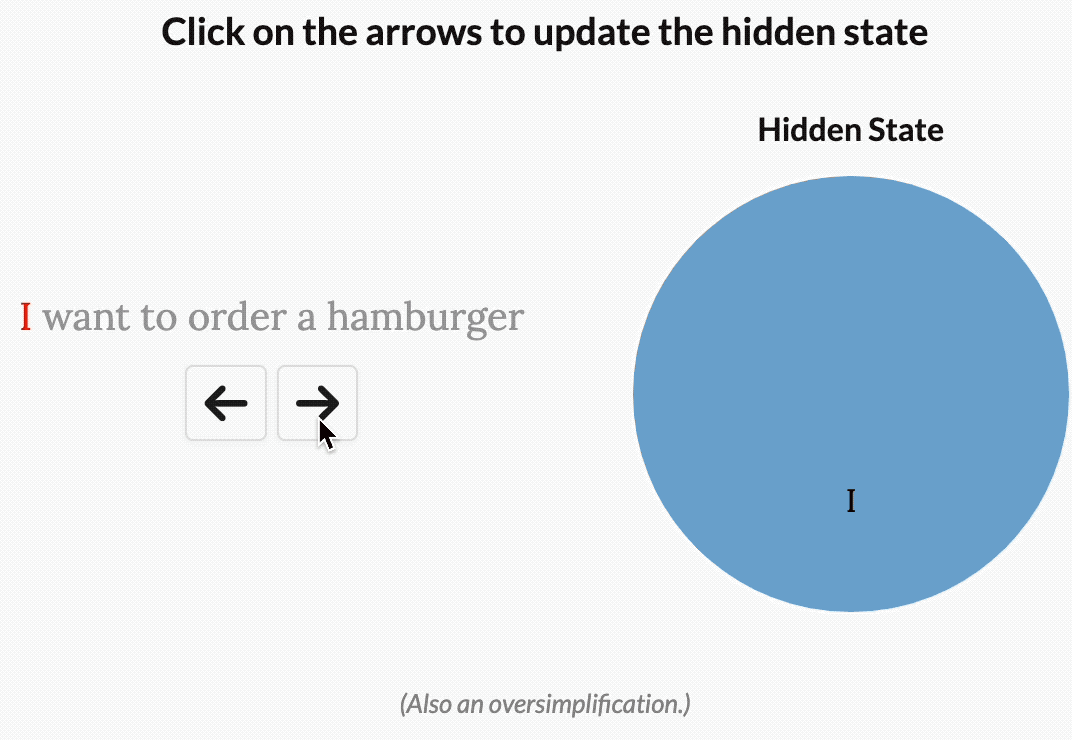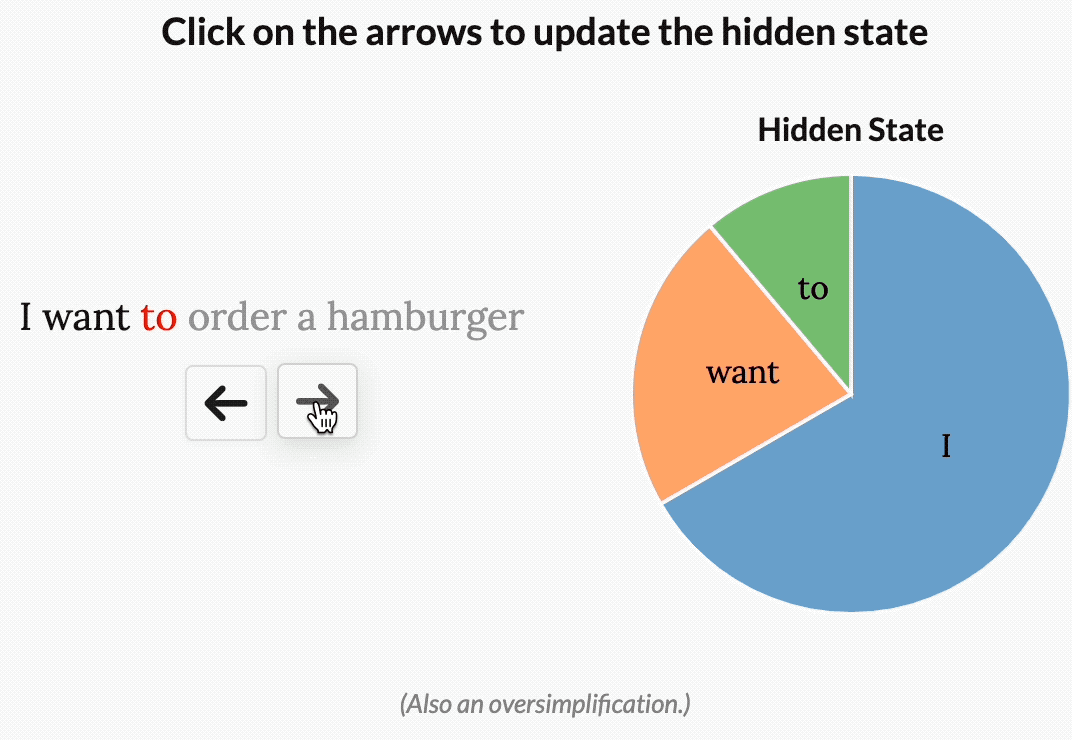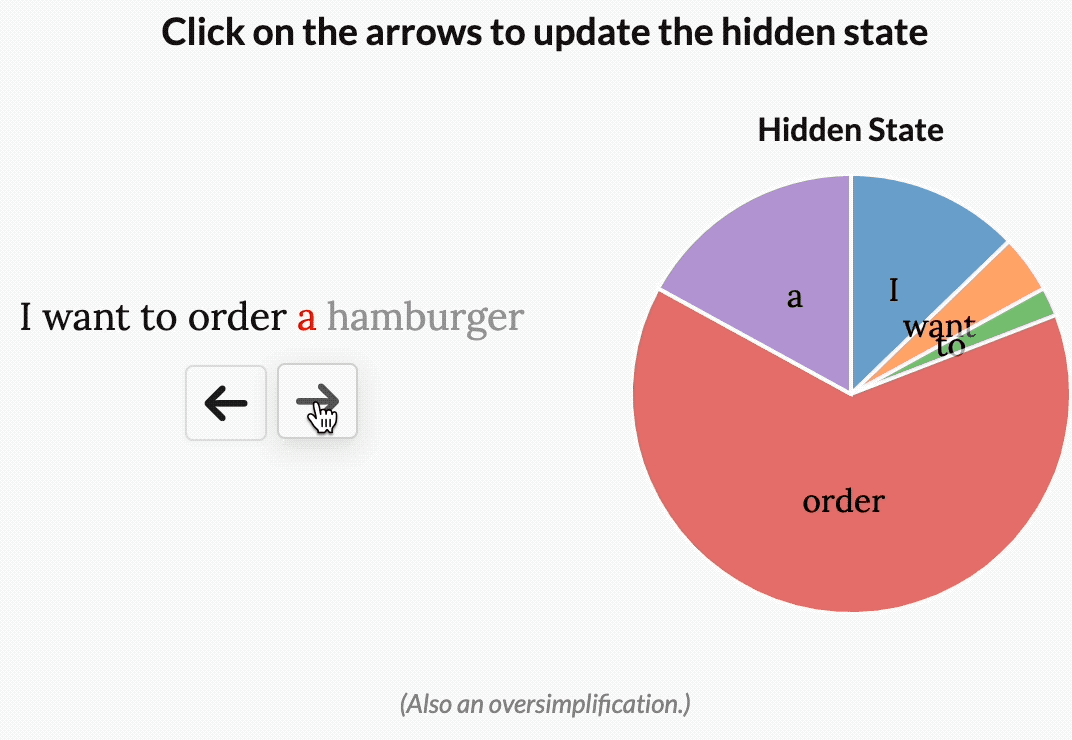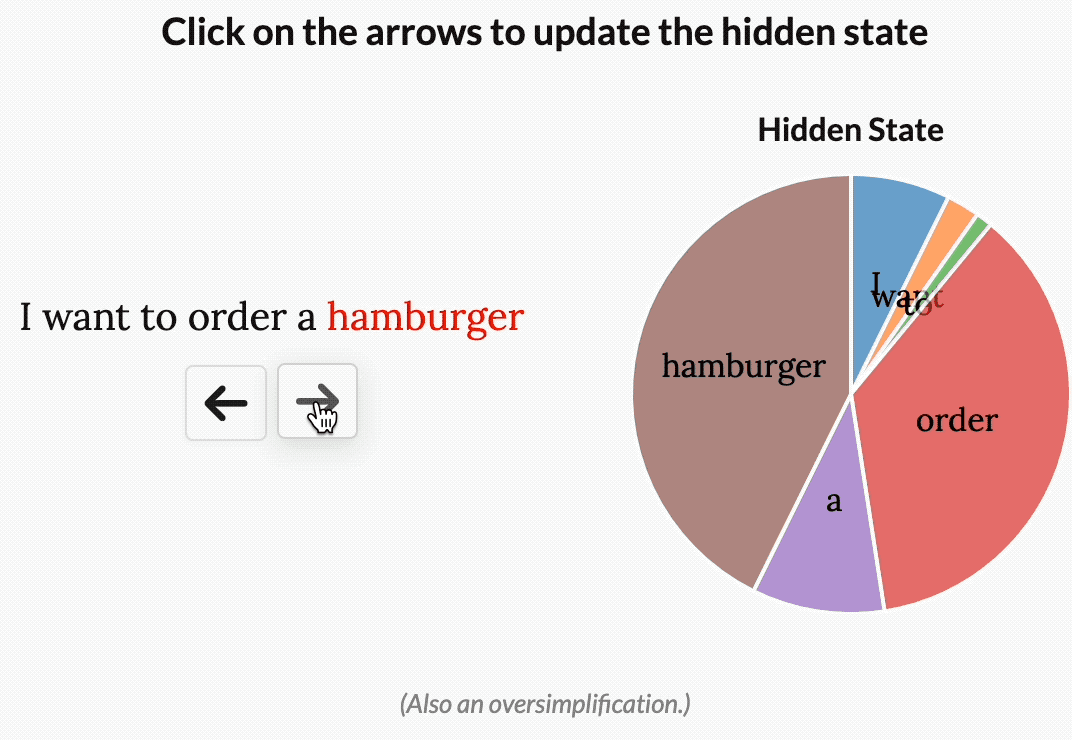
就比如 “I want to order a hamburger.”這句。
如果沒有選擇性,S4會花費相同的“精力”來處理每個單詞:

但如果是一個試圖對這句話的意圖進行分類的模型,它可能會想更多地“關注”order、hamburger,而不是want、to。
如下圖所示,而通過使模型參數成為輸入的函數,Mamba就可以做到“專注于”輸入中對于當前任務更重要的部分。
然而,選擇性給我們帶來了一個問題。讓我們回想一下之前計算的卷積核。
在S4中,我們可以預先計算該內核、保存,并將其與輸入x相乘。
這很好,因為離散參數
、
和C是恒定的。但同樣,在Mamba中,這些矩陣會根據輸入而變化!因此,我們無法預計算
,也無法使用CNN模式來訓練我們的模型。如果我們想要選擇性,我們得用RNN模式進行訓練。方法是刪除方程3b以獲得“戲劇性的效果”。

但這給Mamba的作者帶來了一個問題:RNN模式的訓練速度非常慢。
假如我們正在使用1000個token的序列訓練我們的模型:
CNN本質上會計算其內核和輸入向量之間的點積,并且可以并行執行這些計算。相比之下,RNN需要按順序更新其隱藏狀態1000次。
這便導致Mamba的作者提出了他們的第二個偉大思想。
第二個主要思想:無需卷積的快速訓練
Mamba可以在RNN模式下進行非常非常快速的訓練。
在某個時刻,它們的遞歸與掃描算法(也稱為前綴和,prefix sum)非常相似。
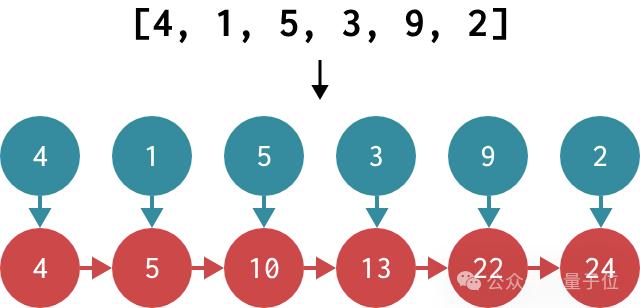
要計算前綴和,我們需要獲取一個輸入數組 [x1,x2,… ,xn] ,并返回一個輸出數組,其中每個元素都是該項目及其之前項目的總和。
換句話說,輸出的第一個元素將為x1 ,第二個元素將為[x1+[x2 ,依此類推。一個例子:
現在我們畫出RNN模式下更新Mamba隱藏狀態的流程。
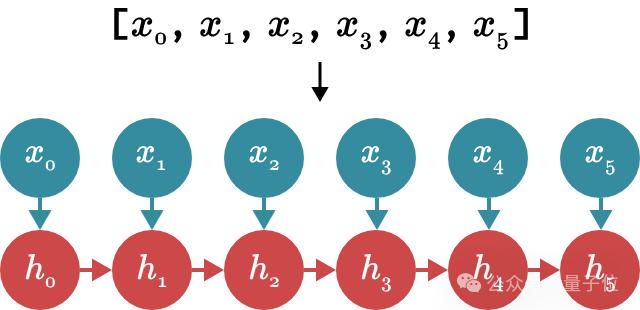
等等……,如果我們必須形式化前綴和,我們可以將其寫成以下等式:

該方程形成一個遞歸:在每一步,我們通過將先前存儲的值添加到當前輸入來計算新值。現在,讓我們再次看看更新之后Mamba隱藏狀態的循環。
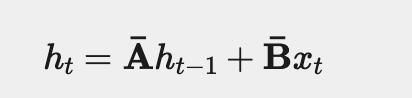
這兩個等式真的非常非常相似有么有!
而最酷的地方又來了:雖然計算前綴和本質上看起來似乎是順序的,但我們實際上擁有用于此任務的高效并行算法!
在下圖中,我們可以看到正在運行的并行前綴和算法,其中每條垂直線代表數組中的一項。

花一點時間捋一下這個算法:
選擇任何垂直線,從頂部開始,然后向下移動,將每個加法追溯到數組的前幾個項目。當你到達底部時,應該在行的左側看到所有項目的總和。
例如,在第一個元素添加到開頭的第二個元素之后,數組的第三個元素在末尾接收了第二個元素的添加值。結果,當并行掃描完成時,第三個元素包含第一、第二和第三元素的總和。
如果我們在沒有并行性的單線程中運行該算法,則比僅按順序將值相加所需的時間要長。但GPU擁有大量處理器,可以進行高度并行計算。因此,我們可以在大約O(logn) 時間內計算此前綴和(或掃描)操作!
因此,Mamba的作者意識到,如果他們想在RNN模式下高效訓練,他們可能可以用并行掃描。
但由于PyTorch目前沒有掃描實現,Mamba的作者自己編寫了一個——但,結果并不好。
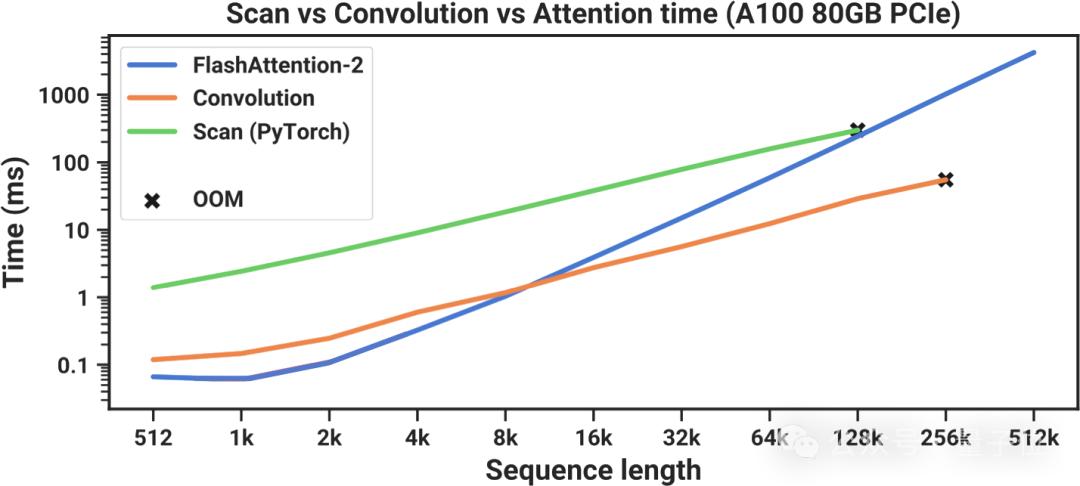
在上圖中,大家可以看到他們基于PyTorch的掃描實現(綠色)總是慢于FlashAttention-2(藍色),FlashAttention-2是可用“精確注意力”的最快實現。
盡管當序列長度為128000個token時,掃描似乎在運行時趕上,但還是耗盡了內存。
為了讓Mamba變得實用,它需要更快。這讓Mamba的作者看到了Dao之前關于FlashAttention的工作,從而解決了問題。
由于篇幅所限,在此我們省略了原文中FlashAttention的原理介紹部分(Review: FlashAttention),感興趣的朋友可以查看原博/FlashAttention原論文,或者我們。
Back to Mamba
還是基于上一張對比圖。
事實證明,如果在計算掃描時采用相同的內存感知平鋪方法,則可以大大加快速度。
通過這種優化,Mamba(紅色)現在在所有序列長度上都比 FlashAttention-2(藍色)更快。

這些結果表明,就速度而言,Mamba是實用的,其運行速度比最快的Transformer還要快。但它在語言建模方面有什么擅長的地方嗎?
Mamba作者在涉及語言、基因組學和音頻的許多序列建模任務上對Mamba進行了評估。
結果看起來很酷:Mamba在對人類基因組項目的DNA和鋼琴音樂數據集的音頻進行建模時建立了最先進的性能。
然而,讓很多人興奮的是語言任務上的結果。許多關于Mamba的在線討論都集中在下圖中:
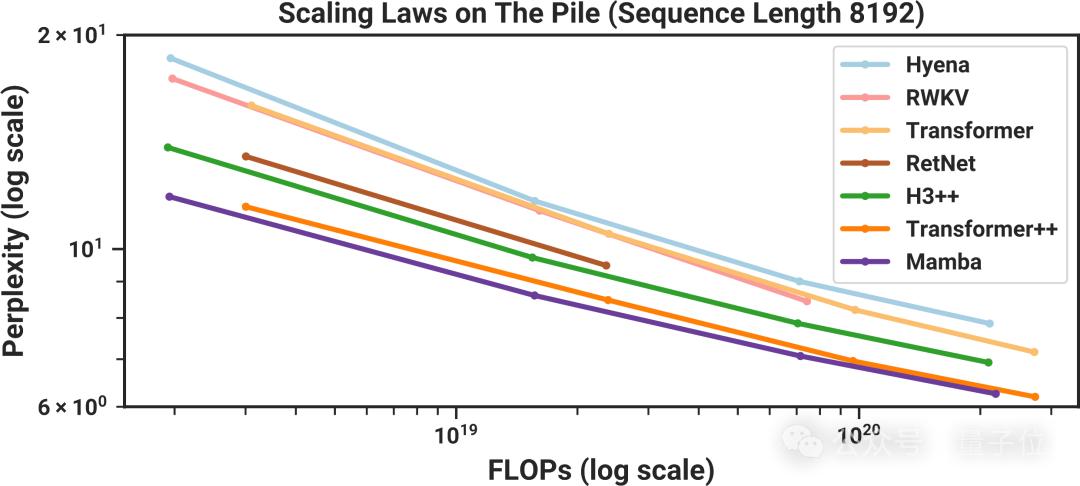
我們可以看到,模型大小向右增加,語言建模性能則隨著進一步向下而提高。
這意味著最好的模型應該位于左側:體積小(因此速度快),并且非常擅長建模語言。
由于Mamba作者都是學者,搞不來數千個GPU來訓練GPT-4大小的模型,因此實驗是通過訓練一堆較小的模型(大約125M到1.3B參數)來進行比較的。
如上圖所示,結果看起來非常有希望。與其他類似尺寸的模型相比,Mamba似乎是最擅長建模語言的。
為什么被“二連拒”
寫到最后,本文作者再次表達了對Mamba被拒的惋惜:
我真的認為Mamba以一種非常獨特和有趣的方式在語言建模上進行了創新。但很不幸,一些審稿人并不同意。
從最新的駁回意見來看,其中一位審稿人的拒絕理由與“兩個重大基準評估”有關。
一是缺少LRA(Long Range Arena)評估,公認的長序列建模基準。
二是僅將困惑度評估作為主要評價指標不行,理由是低困惑度與生成性能不一定正相關。
最終的總體意見是:再增加額外的實驗。
對此結果,有網友也再次評價道:
這只能說明一篇論文被會議接收與否與它對社區的價值貢獻并不掛鉤。因為前者很容易依賴于極少數人的判斷。

其實說到公認的好論文被頂會pass一事,Mamba還真不是頭一個。
大約十年前,Word2vec也曾被ICLR“丑拒”,然而去年,它還捧回了NeurIPS的時間檢驗獎。
你覺得時間會為Mamba“正名”嗎?
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
