

 新火種
2024-01-31
新火種
2024-01-31 


編程能力超GPT-4,羊駝代碼版“超大杯”來了,小扎還親自劇透Llama3
羊駝家族的“最強開源代碼模型”,迎來了它的“超大杯”——
就在今天凌晨,Meta宣布推出Code Llama的70B版本。
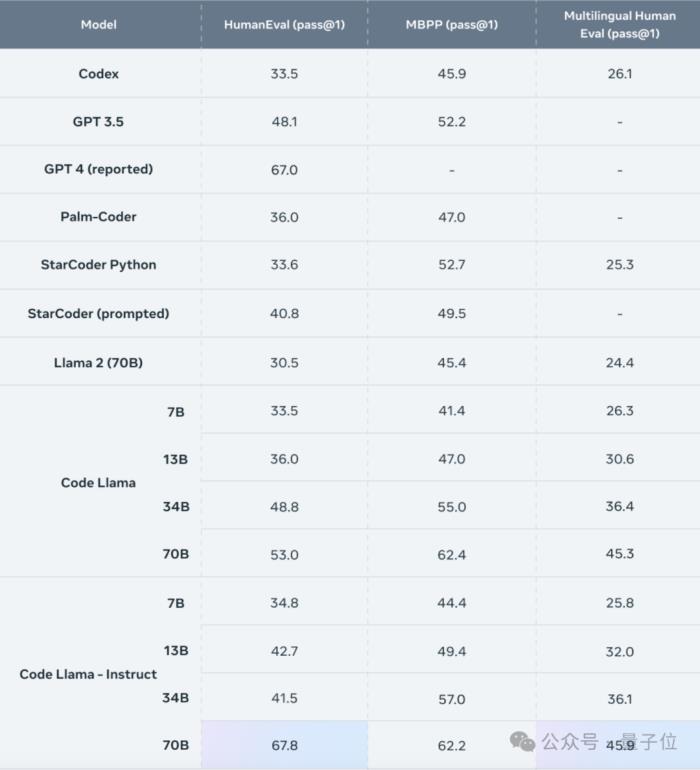
在HumanEval測試中,Code Llama-70B的表現在開源代碼模型中位列第一,甚至超越了GPT-4。
此次發布的超大杯,保持著與小號版本相同的許可協議,也就是仍然可以免費商用。
版本上,也和往常一樣分為原版、針對自然語言指令微調的Instruct版和針對Python微調的Python版。
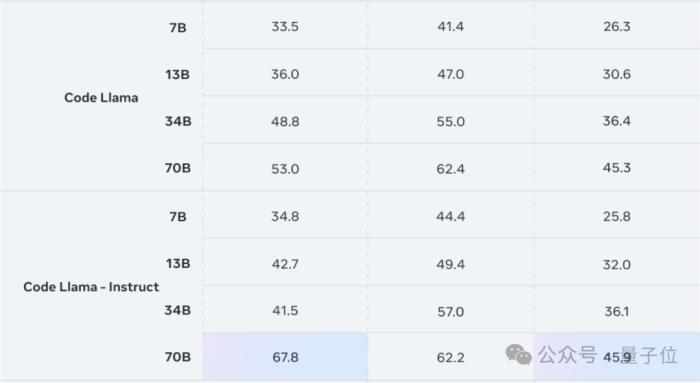
其中擊敗GPT-4的是Instruct版本,它取得了67.8分的pass@1成績,勝過了GPT-4的67分。
與34B模型相比,基礎版和Instruct版的成績分別提高了8.6%和63.4%。
Code Llama的所有版本均在16000個token的序列上進行訓練,上下文長度可達10萬token。
這意味著,除了生成更長的代碼,Code Llama還可以從用戶的自定義代碼庫讀取更多內容,將其傳遞到模型中。
這樣一來就可以針對具體問題的相關代碼進行快速定位,解決了用戶面對海量代碼進行調試時“無從下手”的問題。
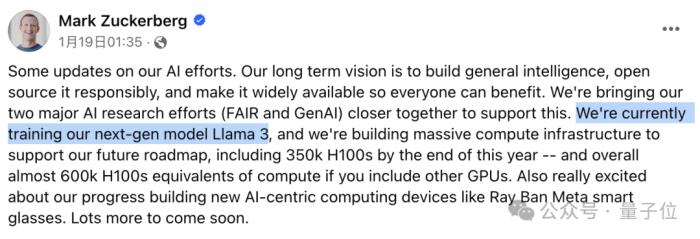
Meta CEO小扎也在個人博客中宣布了這一消息,表示為70B Code Llama感到驕傲。

而小扎的這則帖文,也被細心的網友發現了玄機。
Llama 3要來了?
的確,在帖文的結尾處,小扎說希望這些成果能夠應用到Llama 3當中。

難道,Llama 3,真的要來了嗎?
早在去年8月,有關Llama 3的傳聞就已經出現,而直到上周小扎才正式透露,Llama 3的訓練過程正在進行。
同時,Meta也在進一步擴充算力,預計到今年年底將擁有35萬塊H100。
如果將其他顯卡也折算成H100,Meta總計將擁有等效于60萬塊H100的算力。
不過小扎透露的消息似乎沒有滿足網友的好奇心,關于Llama 3究竟何時能上線的討論也不絕于耳。
關于這個問題,暫時還沒有官方消息,有人推測就在今年第一季度。
但可以確定的是,Llama 3將繼續保持開源。
同時小扎還表示,AGI將是下一代人工智能的一大標志,也是Meta所追求的目標。
為了加速AGI的實現,Meta還將旗下的FAIR團隊和GenAI團隊進行了合并。
卷參數量,有必要嗎?
除了Llama 3這個“意外發現”,關于Code Llama本身,網友們也提出了不少問題和期待。
首先是關于運行Code Llama所需要的硬件資源,有網友期待在蘋果M2 Max等芯片上就能運行。

但實際情況是,由于沒有N卡用不了CUDA,Code Llama在M系蘋果芯片上的運行結果并不理想。

針對N卡則有人猜測,如果對模型進行量化操作,可能4090就能帶動。
也有人質疑這種想法是過度樂觀,4090能帶動的量化程度可能并不適用于這款模型。
但如果愿意用運算速度換取顯存空間,用兩塊3090來代替也未嘗不可。

但即便4090屬于消費級顯卡,大部分程序員仍然不一定有能高效運行70B模型的設備。
這也就引發了另一個問題——堆參數量,是否真的有必要?
從Pass@1排行榜中,深度求索團隊的DeepSeek Coder表現就比Code Llama高出2.3分,但參數量卻只有6.7B,不足后者的十分之一。

如果縱向比較,DeepSeek Coder的6.7B和33B版本僅差了2.5分,參數量帶來的性能提升并沒有Code Llama當中明顯。
所以,除了堆參數量,Meta或許還得在模型本身上再下點功夫。

相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
