

 新火種
2024-01-26
新火種
2024-01-26 

湯曉鷗弟子帶隊:免調優長視頻生成,可支持512幀!任何擴散模型都能用
想要AI生成更長的視頻?
現在,有人提出了一個效果很不錯的免調優方法,直接就能作用于預訓練好的視頻擴散模型。
它最長可支持512幀(假設幀率按30fps算,理論上那就是能生成約17秒長的作品了)。


可應用于任何視頻生成模型,比如AnimateDiff、LaVie等等。
以及還能支持多文本生成,比如可以讓駱駝一會跑一會停:

(提示詞:”A camel running on the snow field.” -> “…… standing ……”)
這項成果來自騰訊AI Lab、南洋理工大學以及港科大,入選了ICLR 2024。

值得一提的是,與此前業內性能最佳的同類方法帶來255%的額外時間成本相比,它僅產生約17%的時間成本,因此直接可以忽略不計。
可以說是成本和性能兩全了~
具體來看看。
通過重新調度噪聲實現
該方法主要解決的是兩個問題:
一是現有視頻生成通常在有限數量的幀上完成訓練,導致推理過程中無法生成高保真長視頻。
二是這些模型還僅支持單文本生成(即使你給了“一個人睡在桌子上,然后看書”這種提示詞,模型也只會響應其中一個條件),而應用到現實中其實是需要多文本條件,畢竟視頻內容是會隨時間不斷變化的。
在此,作者首先分析視頻擴散模型的時間建模機制,并研究了初始噪聲的影響,提出免調優、實現更長視頻推理的FreeNoise。
具體而言,以VideoLDM模型為例,它生成的幀不僅取決于當前幀的初始噪聲,還取決于所有幀的初始噪音。
這意味著,由于臨時注意力層負責促成整個交互,所以對任何幀的噪聲重新采樣都會顯著影響其它幀。
產生的問題就是我們要想保持原視頻主要內容的同時引入新東西就很難。
在此,作者檢查VideoLDM的時間建模機制發現,其中的時間注意力模塊是順序無關的,而時間卷積模塊是順序相關的。
實驗觀察表明,每幀噪聲是決定視頻整體外觀的基礎,而它們的時間順序會影響建立在該基礎上的內容。
受此啟發,作者提出了FreeNoise,其關鍵思想是構建一個具有長程相關性的噪聲幀序列,并通過基于窗口的融合對其進行時間關注。
它主要包括兩個關鍵設計:局部噪聲去除和基于窗口的注意力融合。
通過將局部噪聲混洗應用于固定隨機噪聲幀序列以進行長度擴展,作者實現了具有內部隨機性和長程相關性的噪聲幀序列。
同時,基于窗口的注意力融合使預先訓練的時間注意力模塊能夠處理任何較長的幀。
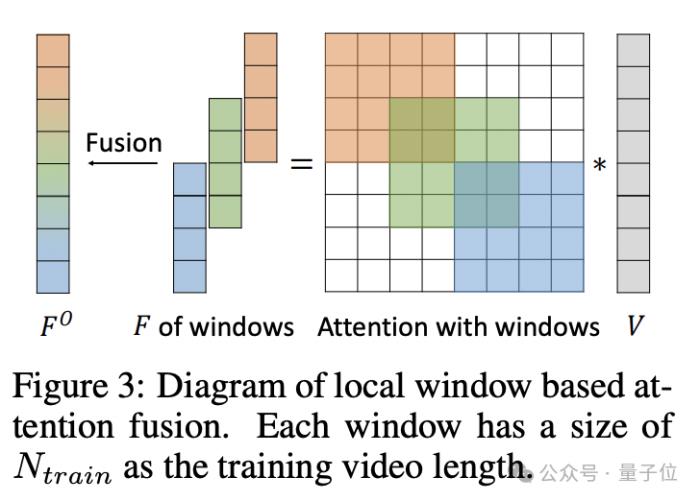
并且最重要的是,重疊窗口切片和合并操作只發生在時間注意力上,而不會給VideoLDM的其他模塊帶來計算開銷,這也大大提高了計算效率。
接下來,為了解決多文本條件問題,作者則提出了動作注入(Motion Injection)方法。
其核心利用的是擴散模型不同步驟在去噪過程中恢復不同級別信息(圖像布局、物體形狀和精細視覺細節)的特性。
在模型完成上一個動作之后,該方法就在與物體形狀相關的時間步長內逐漸注入新的運動。
這樣的操作,既保證多提示長視頻生成,又具備很好的視覺連貫性。
超越此前最先進的無調優方法
首先來看長視頻生成的結果。
可以看到,FreeNoise詮釋“宇航服吉娃娃”和“熊貓吃披薩”這兩個場景最為連貫自然。
相比之下,直接推理的(最左列)的狗有嚴重偽影且沒有生成背景,Gen-L-Video(此前最先進的無調優方法)則由于無法保持長距離的視覺一致性,存在明顯內容突變。

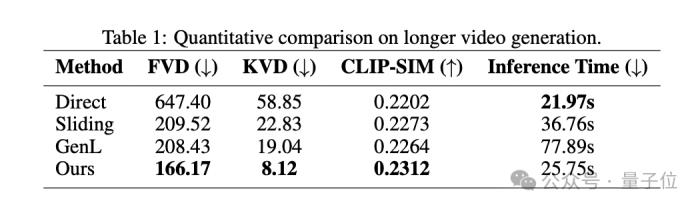
定性結果也用數據證明了FreeNoise的效果:
其中CLIP-SIM的得分代表該方法做到了良好的內容一致性。
其次是多文本條件生成效果。
可以看到該方法(中間列和最右列)可以實現連貫的視覺顯示和運動:
駱駝從奔跑逐漸變為站立,遠處的山脈一直保持同樣的外觀。

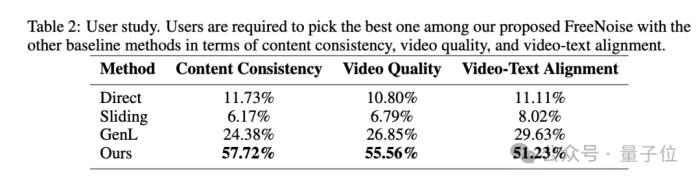
定性結果如下:
可以看到該方法在內容一致性、視頻質量和視頻文本對齊都實現SOTA,且與第二名拉開的差距幾乎達到兩倍之多。
最后,再給大家展示一下FreeNoise用在潛視頻擴散模型AnimateDiff、LaVie上的效果。
AnimateDiff:
第一列為原效果,第二列為應用后的效果。

LaVie:

效果提升都是肉眼可見的~
哦對,還有生成的滿打滿算512幀的視頻,大家覺得效果如何呢:
通訊作者之一是湯曉鷗弟子
本文一共7位作者。
一作為南洋理工大學計算機科學與工程學院博士生邱浩楠。
他的研究方向為AIGC、對抗性機器學習和深偽檢測,本科畢業于港中文。

通訊作者有兩位:
一位是騰訊AI Lab視覺計算中心研究員Menghan Xia。
他的研究方向為計算機視覺和深度學習,尤其是圖像/視頻的生成和翻譯。
Menghan Xia博士畢業于港中文,本碩先后畢業于武漢大學的攝影測量與遙感學、模式識別與智能系統專業。

另一位是南洋理工大學計算機科學與工程學院助理教授劉子緯。
他2017年博士畢業于港中文,師從湯曉鷗教授和王曉剛教授。
畢業后曾在UC伯克利做博士后、港中文擔任四年研究員。

相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
