

 新火種
2024-01-17
新火種
2024-01-17 


精確指出特定事件發生時間!字節&復旦大學多模態大模型解讀視頻太香了
字節&復旦大學多模態理解大模型來了:
可以精確定位到視頻中特定事件的發生時間。
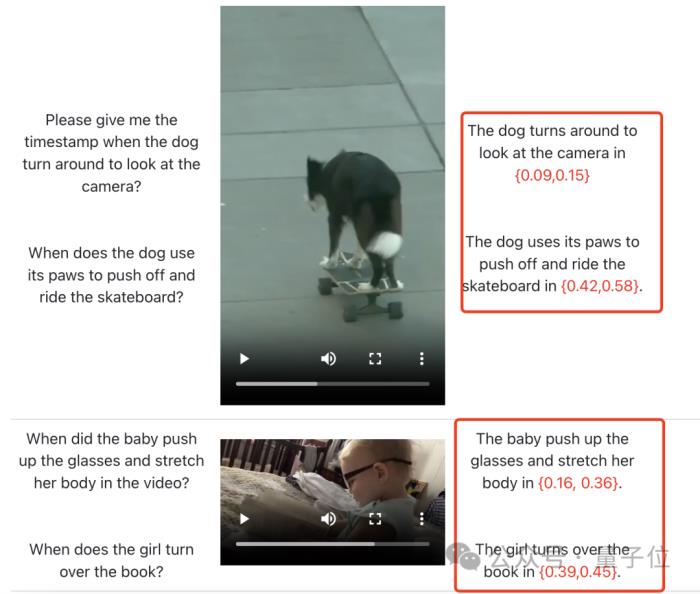
比如在下面這個視頻中:
狗子轉身看鏡頭時的時間戳是多少?
什么時候用爪子推開滑板?

在這里,視頻中的寶寶什么時候推起眼鏡、舒展了一下身體?又是什么時候翻的書?

對于這樣的問題,這個叫做LEGO的模型全都讀得懂,并毫不猶豫給出正確答案。
看起來,有了這些研究成果,以后我們看視頻查資料都要方便一大截咯?
可精確識別局部信息的多模態LLM來了LEGO全稱是一個語言增強的多模態grounding模型。

它主要解決的是多模態LLM跨多種模態進行細粒度理解的能力,此前業內的成果主要強調全局信息。
為了實現該目標,作者主要先從數據集下手,打造了一套用于模型訓練的多模式、多粒度問答形式數據集(即將開源)。
該數據集的構建涉及兩個關鍵流程。
一是數據集轉換(Dataset Conversion)。
在這個階段,作者的目的是構建用于模態對齊和細粒度對齊的基礎多模態數據集。
由于數據集質量相對較低,主要通過轉換公開數據集獲得。
如下圖上部分所示,他們向GPT-3.5提供任務描述以生成特定于任務的問題庫,最終生成單輪對話格式的問答對。
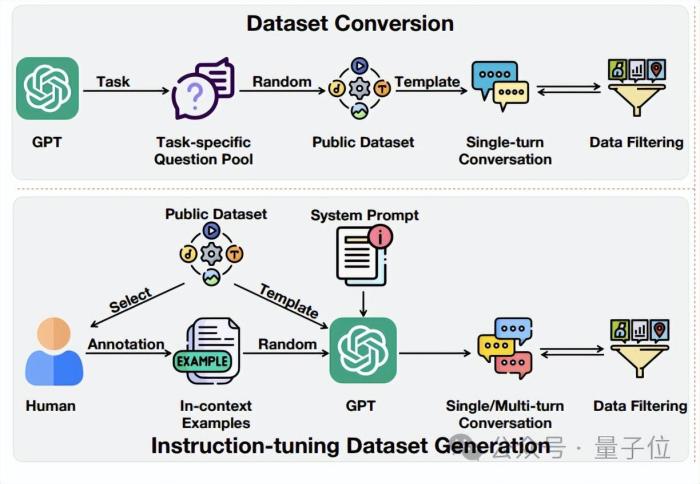
生成的數據集會進行過濾以確保其質量。
其中對于圖像模態,作者利用LLaVA-pretrain595K數據集進行模態對齊,細粒度對齊則使用特定數據集如RefCOCO。
視頻模態用Valley-Pretrain-703K進行模態對齊,Charades-STA數據集用于細粒度對齊。
二是指令調整數據集生成(Instruction-tuning Dataset Generation)。
這個數據集的目的是讓模型更好地理解和遵循人類指令。
如上圖下部分所示,作者也選擇了公開可用的數據集(Flickr30K Entities、VCR、DiDeMo等)的子集進行人工注釋,以創建上下文示例。它用于指導GPT-3.5在生成指令調整數據集時遵循類似的模式。
隨后,特定任務的系統提示和隨機選擇的示例被輸入到GPT-3.5中,以生成單輪或多輪對話。最后,進行數據過濾以確保數據集質量。
下面是經過三階段訓練產生的最終數據樣本示例:

下面是LEGO模型的架構:
每個模態的輸入通過獨立的編碼器進行處理,提取特征,然后使用適配器將這些特征映射到LLM的嵌入空間。
圖中演示的是視頻和圖像模式的兩個示例,藍色方框表示視頻作為輸入,而黃色方框表示圖像作為輸入。
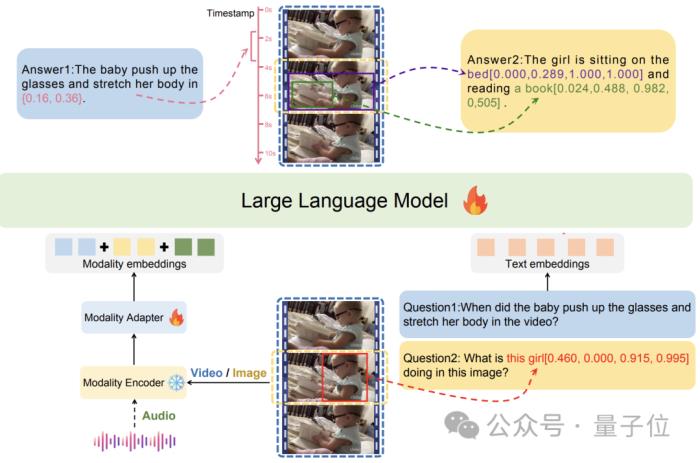
由于其基于模塊化設計和適配器的架構,LEGO可以無縫集成新的編碼器,處理額外的模態,如點云和語音,主打一個好擴展。
最后,LEGO使用Vicuna1.5-7B作為基礎語言模型,訓練由三個階段完成:多模態預訓練,細粒度對齊調整和跨模式指令調整。
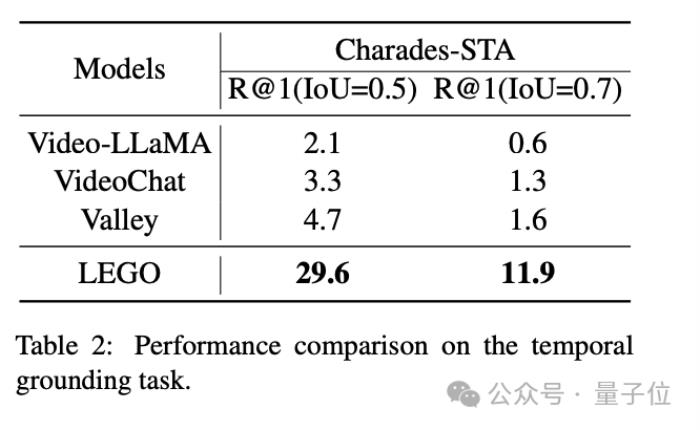
下面是實驗評估:
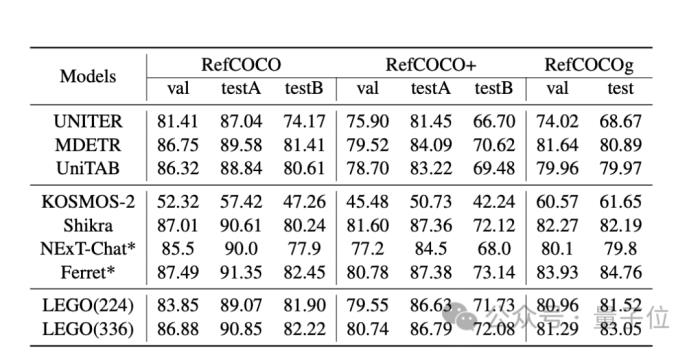
圖像任務中,LEGO模型和其他模型在REC任務中的性能如下表所示,可以看到它在所有數據集上都表現出了比較有競爭力的性能。
視頻任務中,由于LEGO側重對于整個視頻的理解,相比VideoLLaMA、VideoChat和Valley這三個模型,性能表現相當優異:
更多能力展示
如上所說,LEGO的能力不僅在于視頻定位,對圖片、音頻等多模態任務都很在行。
指的就是以下這些:
圖像內容解讀在這張風景圖中,它準確給出了游玩風險提示。

在這個meme圖中,它也準確發現這是一個炸雞拼成的簡單地圖。

視頻內容概括簡介
可以看到它能識別出非常細節的城市坐標和景點。

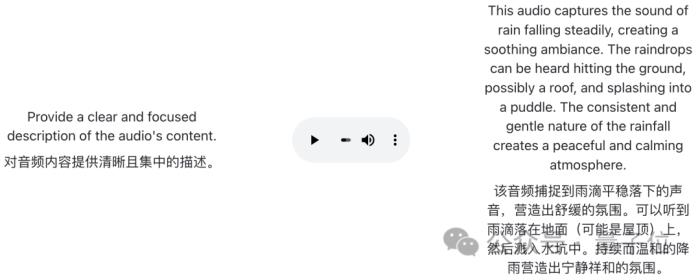
音頻解析
當然,這里測試的只是一個比較簡單的純雨聲短音頻。
聲音定位
給一段狗叫音頻+一張狗狗奔跑的圖像,它可以準確圈出聲音來源在狗嘴部。

作者介紹
本文一共12位作者。

除了一作Zhaowei Li來自復旦大學,還有一位叫做的Dong Zhang的也來自這里。
其余均為字節跳動員工,通訊作者為Tao Wang。
— 完 —
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
