

 新火種
2024-01-02
新火種
2024-01-02 

大模型竟然能玩手機了,還能用軟件修圖:「AppAgent」會成為2024年的新趨勢嗎?
這就是2024年的新趨勢嗎?近日,一項名為 AppAgent 的創新技術引起了廣泛關注。簡單來說,AppAgent 的智能代理能力可以用于操作任何 App,它在 50 個復雜手機任務上展示了強大的能力。 推特用戶 Logan Thorneloe 評價道:“這太酷了!但是我知道它會被用來制造水軍機器人,這讓我有些擔心。”
推特用戶 Logan Thorneloe 評價道:“這太酷了!但是我知道它會被用來制造水軍機器人,這讓我有些擔心。”


據論文介紹,這項技術通過引入一種基于大型語言模型(LLMs)的多模態智能代理(Agent)框架,賦予了智能體操作智能手機應用的能力。與傳統的智能助手如 Siri 不同,AppAgent 不依賴于系統后端訪問,而是通過模擬人類的點擊和滑動等操作,直接與手機應用的圖形用戶界面(GUI)互動。這種獨特的方法不僅提高了安全性和隱私性,還確保了智能體能夠適應應用界面的變化和更新。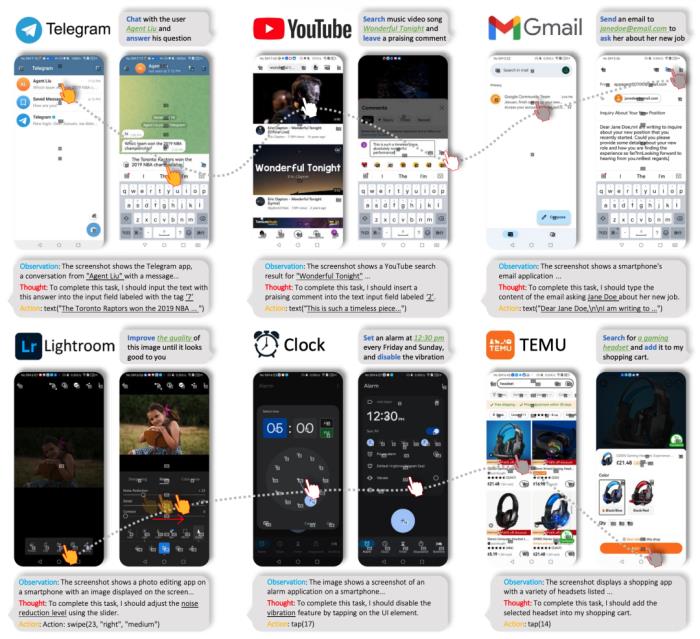 AppAgent 的核心在于其創新的學習方式。智能體可以通過自主探索或觀察人類演示來學習如何導航和使用新應用。在自主探索過程中,智能體通過一系列預定義的動作與應用互動,觀察每個動作帶來的界面變化,從而構建知識庫。這個過程還可以通過觀察少數幾個人類演示來加速,使智能體能夠更快地理解復雜功能。為了驗證其實用性,研究團隊對 AppAgent 進行了廣泛測試,覆蓋了社交媒體、電子郵件、地圖、購物以及復雜的圖像編輯工具等 10 種不同的應用中的 50 個任務。
AppAgent 的核心在于其創新的學習方式。智能體可以通過自主探索或觀察人類演示來學習如何導航和使用新應用。在自主探索過程中,智能體通過一系列預定義的動作與應用互動,觀察每個動作帶來的界面變化,從而構建知識庫。這個過程還可以通過觀察少數幾個人類演示來加速,使智能體能夠更快地理解復雜功能。為了驗證其實用性,研究團隊對 AppAgent 進行了廣泛測試,覆蓋了社交媒體、電子郵件、地圖、購物以及復雜的圖像編輯工具等 10 種不同的應用中的 50 個任務。
測試結果證明,AppAgent 在處理各種高級任務方面表現出色,顯示出其適應性、用戶友好性以及高效的學習和操作能力。推特大 V Andrew Torba 評價道:「一切都結束了,自 2017 年以來整個互聯網都已經是 AI 的天下。互聯網已死的理論是真實的。構建并推動盡可能多的基于 AI 的機器人來充斥網絡空間,用紅色藥丸 (來自電影《黑客帝國》) 淹沒它們是唯一的出路。」


推特用戶 Logan Thorneloe 評價道:“這太酷了!但是我知道它會被用來制造水軍機器人,這讓我有些擔心。”
方法概述環境搭建AppAgent 的實驗環境是基于命令行界面(CLI),使得代理能與安卓系統上的智能手機應用進行交互。代理接收兩種關鍵輸入:一是展示應用界面的實時屏幕截圖,二是詳細描述交互元素的 XML 文件。為了提升代理識別和交互這些元素的能力,每個元素都被賦予了一個唯一標識符。這些標識符要么來源于 XML 文件中的資源 ID(如果提供),要么通過結合元素的類名、大小和內容來構建。這些以半透明數字形式覆蓋在屏幕截圖上的元素,幫助代理在不需指定精確位置的情況下準確互動,從而提升控制手機的精確度。動作空間模擬了人類與智能手機的常見交互方式,包括點擊和滑動。
設計了四個基本功能:點擊(Tap)、長按(Long_press)、滑動(Swipe)和文本輸入(Text),以及兩個系統級功能:返回(Back)和退出(Exit)。這些預定義動作旨在簡化代理的交互流程,并減少對精確屏幕坐標的依賴,解決了語言模型在準確預測中可能遇到的挑戰。App 探索階段探索階段是 AppAgent 框架的核心,代理通過自主交互或觀察人類演示來學習應用程序的功能和特性。在自主交互模式下,代理被分配一個任務并開始與 UI 元素進行自主互動。它嘗試不同的動作,并觀察應用界面的變化以理解其工作原理。
代理通過分析每個動作前后的屏幕截圖,嘗試弄清楚 UI 元素的功能和特定動作的效果,并將這些信息編譯成文檔,記錄下不同元素所執行動作的效果。當一個 UI 元素被多次操作時,代理會根據之前的文檔和當前的觀察來更新信息,以提高認知質量。為了提高探索效率,如果當前 UI 頁面似乎與應用的主要任務無關(如廣告頁面),代理將停止進一步探索并使用 Android 系統的返回功能返回到前一個 UI 頁面。這種目標導向的探索方法,相比隨機探索(如深度優先搜索和廣度優先搜索),確保代理專注于對應用有效操作至關重要的元素。
此外,代理還利用語言模型的現有關于用戶界面的知識來提高探索效率,直到完成分配的任務。在通過觀察人類演示進行探索的方式中,代理通過觀察人類用戶的操作來學習應用的復雜功能,這對于那些可能難以通過自主交互發現的功能尤其有效。在此方法中,代理記錄人類使用的元素和動作,這種策略縮小了探索空間,并阻止代理與無關的應用頁面進行交互,從而比自主交互更為高效和有條理。
部署階段,AppAgent 參考整理好的文檔,不斷的觀察思考總結來完成復雜的任務。實驗結論AppAgent 通過一系列的量化和定性實驗,證明了其在操控多樣化智能手機應用方面的顯著能力。該評估涉及了 10 種廣泛使用的應用,覆蓋了從社交媒體、地圖導航到音樂播放和圖片編輯等多個領域。通過特別針對 Adobe Lightroom 這一圖像編輯應用的深入案例研究,AppAgent 的視覺處理能力得到了詳盡的考察。AppAgent 采用了先進的多模態大型語言模型 GPT-4 來處理交錯的圖像和文本輸入,這種獨特的能力使其能夠無縫地解釋和互動應用中的視覺及文本信息。實驗結果表明,通過簡化動作空間的設計,AppAgent 在準確性和效率上大幅度超越了原始的 GPT-4 模型。這主要是因為簡化動作空間消除了對生成精確 xy 坐標的需求,這是傳統語言模型的一個挑戰點。
在成功率、獎勵和平均步驟數三個關鍵性能指標上,AppAgent 表現優異。即便在任務步驟上遇到失敗,它也能根據其最終狀態獲得一定的獎勵分數,這反映出其在理解和執行任務方面的適應性和韌性。特別是在多樣化的應用中,AppAgent 通過有效地完成任務,展現了其出色的操作能力。通過自主探索和觀察人類演示生成的文檔,AppAgent 的性能顯著優于僅依賴原始 GPT-4 模型的基線。這些文檔的有效性與人工編寫的文檔相媲美,凸顯了設計在增強代理跨多樣化應用表現的有效性。定性結果進一步證明了 AppAgent 在準確感知、推理和響應任務要求方面的能力。
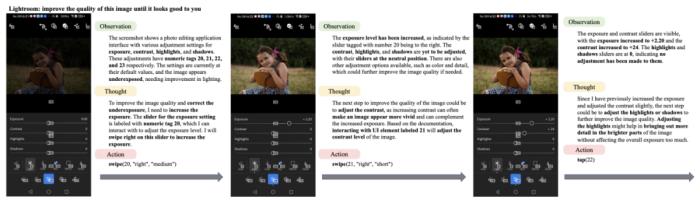
在 Adobe Lightroom 的案例研究中,AppAgent 對具有不同視覺問題的圖片進行編輯,展現了其處理視覺任務的高級能力。用戶研究的結果顯示,相較于 GPT-4 基線,AppAgent 在圖像編輯質量上有了明顯提升。尤其是在使用觀察演示生成的文檔時,AppAgent 傾向于使用更多工具來提升圖像質量,而 GPT-4 基線通常使用較少的工具。總而言之,AppAgent 在多項任務中展示了出色的性能和適應性。其創新的多模態框架和有效的探索策略,不僅驗證了 AppAgent 的實用性,還為智能代理在理解和操作多樣化智能手機應用方面的研究提供了寶貴的見解和基準。
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
