

 新火種
2023-12-27
新火種
2023-12-27 


醫學通用分割模型來了!一口氣分割200多個解剖類別,發布即開源
醫學領域的通用分割模型來啦,發布即開源!
來自智源,模型名為SegVol,劃重點:
是第一次實現同時支持框(box)、點(point)和文本(text) prompt進行任意尺寸原分辨率的3D體素分割。
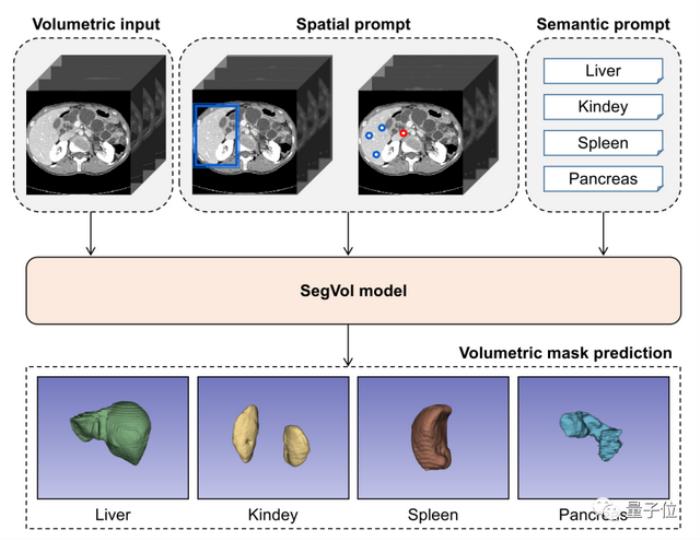
要知道,此前深度學習在醫學圖像分割方面已經取得了顯著進展,但仍然缺乏一種能夠通用分割各種解剖類別、易于用戶交互的基礎分割模型。
而SegVol正是一種通用的交互式醫學體素圖像分割模型,能夠對200多個解剖類別進行分割。
在實驗測試中,SegVol在多個benchmark中表現出色。特別在三個具有挑戰性的病變數據集上,SegVol比nnU-Net的Dice得分高20%左右。
目前,SegVol的代碼和權重已經在GitHub上公開。開源的模型權重文件包括:
使用96k CTs預訓練2,000 epochs的ViT模型;在預訓練基礎上,使用6k Masked CTs在A100上訓練30??21??8個GPU小時得到的SegVol。更多細節,我們接著往下看。
一口氣分割200多個解剖類別SegVol模型架構分為4個模塊:圖像編碼器、文本編碼器、提示編碼器、掩模解碼器。
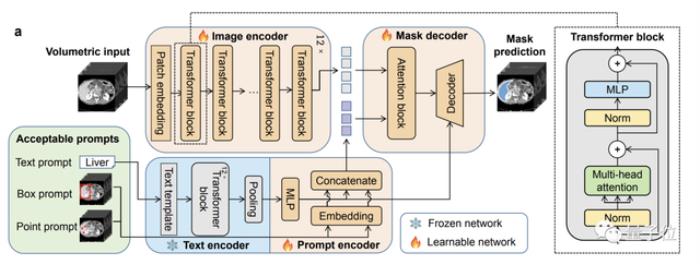
支持文本、點、框三種交互提示,其中為防止過擬合文本編碼器凍結,提示編碼器則是整合三種提示的嵌入,掩模解碼器使用自注意力和交叉注意力預測分割掩模。
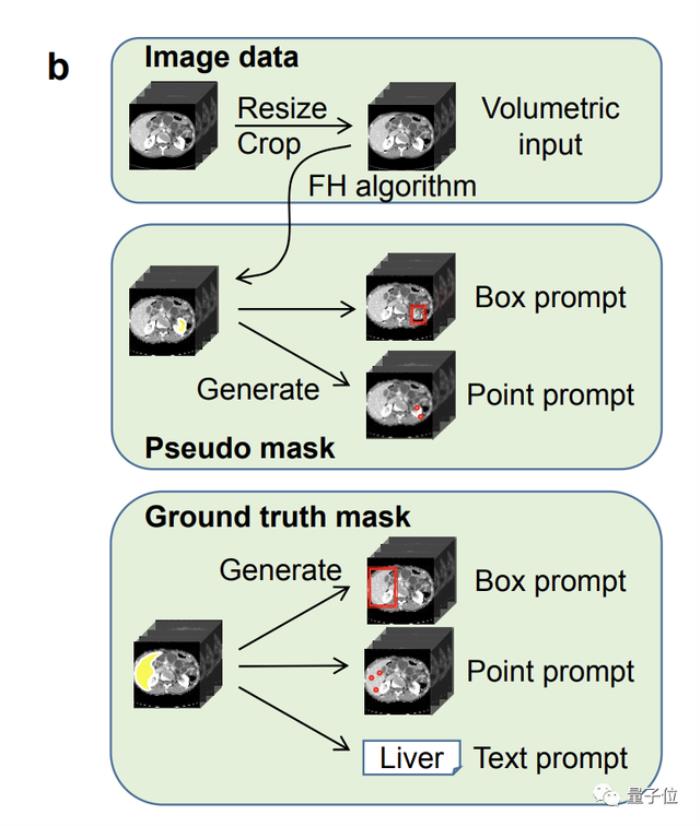
研究人員在96k CTs上對模型進行預訓練,并使用偽標簽解耦數據集和分割類別之間的虛假關聯。
通過將語言模型集成到分割模型中,并在25個數據集的200多個解剖類別上進行訓練,從而實現文本提示分割。
△ (a)聯合數據集概覽,(b)聯合數據集中掩碼數量排名前30的標簽,人體四個主要部位的掩碼標簽數量占比,(c)樣例同時協同語義提示(text prompt)和空間(point, box prompt)提示,實現高精度分割。
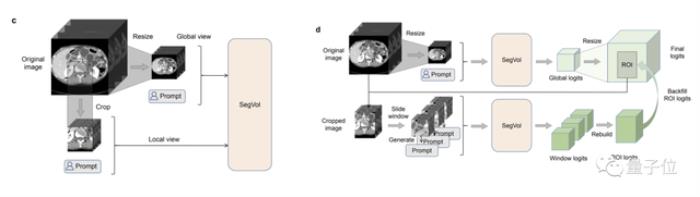
此外,研究人員還設計了一種名為zoom-out-zoom-in的機制,可以顯著降低計算成本,同時保持精確分割。
實驗結果
研究人員在多個分割數據集上充分評估了SegVol。
19種重要解剖結構的實驗結果在prompt learning的支持下,SegVol能夠支持200多個類別的分割。
其中19種重要解剖結構的實驗結果如下:
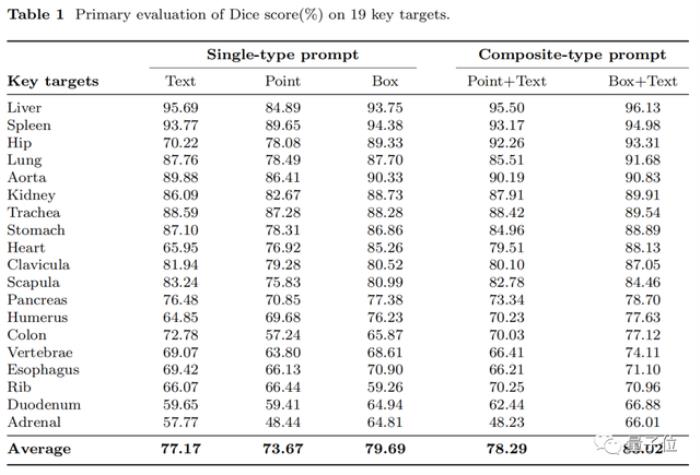
如上表所示,肝臟的Dice得分高達96.13%,19個主要目標的平均得分為83.02%。
研究人員表示,其強大的通用分割功能來自于spatial和semantic的復合prompt。
一方面,spatial prompt可以讓模型理解分割目標的具體空間和位置。由上表可知,對于各種器官的平均分割結果,“box+text” prompt的Dice score比text prompt高5.85%。
另一方面,semantic prompt分割目標的語義指代,消除了多種可能的結果。
這也反映在上表中,“point+text” prompt的平均Dice score比單獨使用point prompt高4.62%。spatial prompt和semantic prompt相互支持,最終賦予模型強大的分割能力。
對比實驗研究人員還將SegVol與五個重要數據集上的四種最先進的方法進行了比較。
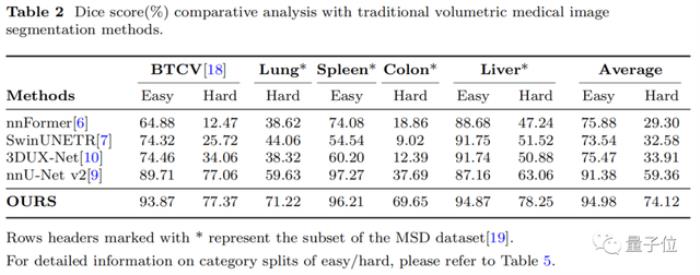
對于體量在數十到數百個病例的醫學體素圖像數據集,由于SegVol能夠在25個數據集上聯合訓練,顯著優于在單個數據集上訓練的傳統分割模型。
從表2可以看出,SegVol在肝、腎、脾等easy類別上超過了傳統模型,平均Dice score達到了94.98%。
研究人員認為這主要是由于它從其他數據集的相同或相似類別中學到了更多的知識。
更重要的是,這種方法在肝腫瘤、肺腫瘤、腎上腺等hard類別的分割中也保持領先地位。
SegVol對hard類的平均Dice score比排名第二的nnU-net高14.76%。
原因是SegVol可以通過spatial prompt和semantic prompt獲得先驗信息,從而增強對hard樣本的理解,顯著改善了分割結果。
病灶分割能力此外,研究人員使用nnU-net作為基線模型,該模型在傳統的醫學體素圖像分割模型中表現出最強的分割能力。
如下表3所示,SegVol分割這些具有挑戰性的病變的能力明顯優于nnU-net。
在這三個病變數據集中,SegVol的Dice score超過nnU-net 19.58%,這代表在復雜體素病灶分割方面SegVol的重大進步。

下圖(c)給出了一系列示例,展示了nnUnet和本文方法的病變分割性能,這些例子包括肝腫瘤、結腸癌和肺腫瘤。
△病灶分割可視化結果顯示,與nnU-net產生的結果相比,SegVol重建的這些病變解剖結構更接近于Ground Truth。
消融實驗Zoom-out-zoom-in機制:
研究人員在MSD-Liver數據集上進行了消融研究,以評估Zoom-out-zoom-in機制的貢獻。
MSD-Liver數據集包括肝臟和肝腫瘤兩個類別,允許研究Zoomout-zoom-in機制對“MegaStructures”和“MicroStructures”目標分割效果的影響。
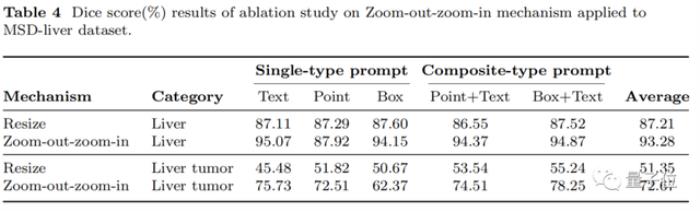
如表4所示,將Zoom-out-zoom-in機制應用于SegVol模型使肝臟類別的Dice score提高了6.07%。這種提升在肝腫瘤類別上更為明顯,Zoom-out-zoom-in機制將SegVol的肝腫瘤Dice score提高了21.32%。
有趣的是,Zoom-out-zoom-in機制對point prompt分割肝臟結果的改善十分微小。這可能歸因于global一級的point prompt相對稀疏,當zoom in到local區域時,其稀疏性變得更加明顯,從而限制了該機制的潛力。
Dataset Scale:
數據規模是基礎模型構建的關鍵因素之一。研究人員進行了消融研究,以研究Image和Mask的數量對SegVol性能的影響。
他們將包含13個重要器官的BTCV數據集作為測試錨點,分別對1、2和8個數據集上訓練了500個epoch的模型,以及在25個數據集上訓練的最終模型進行評估。
△數據集scale。(a)在不同數量的數據集中CTs和相應的Ground Truth Mask數量,(b)不同數據規模訓練SegVol的Dice Score詳細的結果如上圖a和b所示。作為輕量級模型,當只使用一個數據集時,SegVol的性能不是最優的。
然而,隨著數據量的增加,SegVol的Dice score顯著增加,特別是在使用text prompt進行分割的情況下。因為text prompt嚴重依賴帶有語義信息的ground truth mask的數量。
總之,研究人員提出了SegVol,一個交互式的通用醫學體素圖像分割的基礎模型。
該模型是使用90k無標注數據和25個開源分割數據集訓練和評估的。與最強大的傳統體素分割方法nnU-net(自動為每個數據集配置參數)不同,SegVol的目的是將各種醫學體素分割任務統一到一個單一的架構中。
SegVol作為一個通用的分割工具能夠對超過200個解剖目標產生準確的分割響應。
此外,與傳統方法相比,SegVol具有最先進或接近最先進的體素分割性能,特別是對于病灶目標。盡管具有通用性和精確性,但與其他體素分割方法相比,SegVol保持了輕量級架構。
SegVol作為一個開源的基礎模型,將很容易適用于廣泛的醫學圖像表征和分析領域,可以很容易地被研究人員和從業人員集成和利用。
該研究論文一作杜雨新,作者Fan Bai同時來自港中文,作者Tiejun Huang同時來自北大,通訊作者為Bo Zhao。

相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
