

 新火種
2023-12-26
新火種
2023-12-26 


一文幫您了解生成對抗網(wǎng)絡(luò)(GAN)的概念和原理
生成對抗網(wǎng)絡(luò)(GAN)是一種深度學(xué)習(xí)模型,它可以通過兩個(gè)神經(jīng)網(wǎng)絡(luò)的相互博弈來學(xué)習(xí)生成數(shù)據(jù)。GAN由一個(gè)生成器(Generator)和一個(gè)判別器(Discriminator)組成。生成器的目標(biāo)是從一個(gè)隨機(jī)噪聲向量生成類似于真實(shí)數(shù)據(jù)的樣本,比如圖片、文本或音頻。判別器的目標(biāo)是區(qū)分輸入的數(shù)據(jù)是真實(shí)的還是生成器生成的。通過不斷地更新生成器和判別器的參數(shù),GAN可以逐漸提高生成數(shù)據(jù)的質(zhì)量和真實(shí)性。
GAN的原理是:判別器要最大化自己對真實(shí)數(shù)據(jù)和生成數(shù)據(jù)的正確判斷概率,生成器要最小化判別器對生成數(shù)據(jù)的正確判斷概率,也就是最大化判別器對生成數(shù)據(jù)的錯(cuò)誤判斷概率。這樣,生成器和判別器就形成了一個(gè)零和博弈的過程,最終達(dá)到一個(gè)納什均衡點(diǎn),即生成器生成的數(shù)據(jù)和真實(shí)數(shù)據(jù)無法被判別器區(qū)分。
GAN的算法流程可以用以下的偽代碼來描述:
# 初始化生成器G和判別器D的參數(shù)theta_g = initialize_parameters_for_G()theta_d = initialize_parameters_for_D()# 迭代訓(xùn)練for i in range(num_iterations): # 固定生成器G,更新判別器D的參數(shù) for k in range(num_steps): # 一般取k=1 # 從真實(shí)數(shù)據(jù)分布中采樣m個(gè)樣本x x = sample_from_data_distribution(m) # 從噪聲分布中采樣m個(gè)樣本z z = sample_from_noise_distribution(m) # 用生成器G生成m個(gè)樣本G(z) g_z = G(z, theta_g) # 計(jì)算判別器D對真實(shí)數(shù)據(jù)和生成數(shù)據(jù)的輸出概率 d_x = D(x, theta_d) d_g_z = D(g_z, theta_d) # 計(jì)算判別器D的損失函數(shù) loss_d = - (log(d_x) + log(1 - d_g_z)) # 根據(jù)損失函數(shù)對判別器D的參數(shù)進(jìn)行梯度下降更新 theta_d = theta_d - learning_rate * gradient(loss_d, theta_d) # 固定判別器D,更新生成器G的參數(shù) # 從噪聲分布中采樣m個(gè)樣本z z = sample_from_noise_distribution(m) # 用生成器G生成m個(gè)樣本G(z) g_z = G(z, theta_g) # 計(jì)算判別器D對生成數(shù)據(jù)的輸出概率 d_g_z = D(g_z, theta_d) # 計(jì)算生成器G的損失函數(shù) loss_g = - log(d_g_z) # 根據(jù)損失函數(shù)對生成器G的參數(shù)進(jìn)行梯度下降更新 theta_g = theta_g - learning_rate * gradient(loss_g, theta_g)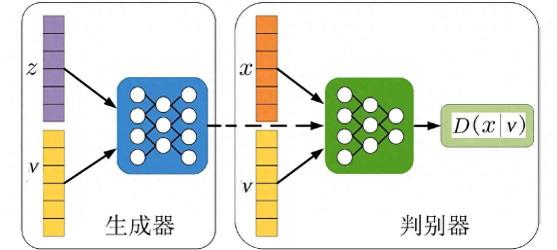
相關(guān)推薦



- 免責(zé)聲明
- 本文所包含的觀點(diǎn)僅代表作者個(gè)人看法,不代表新火種的觀點(diǎn)。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對本文可能提及或鏈接的任何項(xiàng)目不表示認(rèn)可。 交易和投資涉及高風(fēng)險(xiǎn),讀者在采取與本文內(nèi)容相關(guān)的任何行動(dòng)之前,請務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨(dú)立判斷。新火種不對因依賴本文觀點(diǎn)而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
