

 新火種
2023-12-26
新火種
2023-12-26 


西南交大楊燕/江永全團隊:基于雙任務的端到端圖至序列無模板反應預測模型

排版 |X
本文介紹西南交通大學楊燕/江永全團隊發表于《Applied Intelligence》的研究成果,第一作者是碩士生胡昊哲。

作者以目前無模板逆合成領域興起的圖至序列(Graph-to-Sequence)模型框架為基礎,進一步在同參數量規模下嘗試構建一類在單個模型中同時解決逆合成預測與正向反應預測任務的模型 BiG2S(Bidirectional Graph-to-Sequence)。
同時,作者初步分析了模型在主流逆合成數據集 USPTO-50k 上訓練時不同 SMILES 片段的預測難度差異以及模型在訓練期間對驗證集數據 Top-k 匹配率的波動,并對此針對性的引入了不平衡損失函數以及對模型集成與束搜索(beam search)策略的改進。
在三個主流反應預測數據集上對逆合成與正向反應預測任務的測試以及對上述模塊全面的消融實驗證明了 BiG2S 能夠在合適的參數規模下以單一模型處理逆合成與正向反應預測任務,且整體預測能力比肩已有的基于預訓練和數據增強的無模板方法。
研究背景
逆合成(Retrosynthesis)與正向合成(Forward Synthesis)是目前有機化學、計算機輔助合成規劃(CASP)以及計算機輔助藥物設計(CADD)領域的基礎性挑戰。
其中,前者旨在為目標產物搜索可用于合成該產物的反應及對應的反應物,后者則需要為給定的反應物集合預測其發生反應后的主要產物。
早期的逆合成規劃系統直接依賴于領域專家預先編碼的反應規則,或者是基于物理化學的計算,而隨著深度學習的快速發展。目前領域內的主流方法則是構建一個任務特異的神經網絡框架以從數據驅動的角度完成反應預測任務。其中,不依賴于特定先驗化學知識的無模板法通過其類似于端到端機器翻譯的簡潔思路以及靈活性逐漸成為了領域內的主流發展方向之一。
目前,大多數無模板逆合成模型的輸入與輸出均為分子的 SMILES 字符串,即采用了序列至序列(Seq2Seq)的流程。這種方法能夠很好的利用在 NLP 領域內已有的模型框架,以及針對于 SMILES 表示方法的成熟的數據處理流程。
然而,SMILES 作為一維的字符串序列無法很好的表征與利用分子圖所包含的二維/三維結構信息。因此,領域內逐漸出現了采用分子圖代替 SMILES 作為模型輸入的圖至序列(Graph2Seq)方法,亦或是將分子圖的額外結構信息嵌入 SMILES 的序列至序列方法;這兩類方法均能很好的受益于來自分子圖的豐富結構特征。
基于此,本文以新興的圖至序列方法為基礎,在原基于 SMILES 的模型對逆合成與正向反應預測任務同時訓練的相關探索的基準上,進一步全面的探究對此類雙任務模型的構建與實驗,同時也初步的探索與分析了模型在訓練過程中所展現的難度不平衡以及 Top-k 匹配率波動的問題;在此基礎上構建的 BiG2S 模型能夠較好的處理主流數據集中的逆合成與正向反應預測任務,并在不使用數據增強的情況下取得與其他無模板逆合成模型一致的反應預測能力。
總體框架
如圖 1 所示,BiG2S 整體是一個端到端的編碼器-解碼器結構,其中編碼器端通過局部的定向消息傳遞圖網絡以及融入圖結構偏置信息的全局圖 Transformer 生成最終的分子圖節點表征;解碼器則通過標準的 Transformer 解碼器以自回歸式的生成目標分子的 SMILES 序列。
值得注意的是,為了同時學習逆合成與正向反應預測,解碼器端的輸入額外包含了不添加位置信息的雙任務標簽,同時解碼器端的歸一化層以及最終的線性層均包含有兩套參數,用于分別學習逆合成任務與正向反應預測任務。
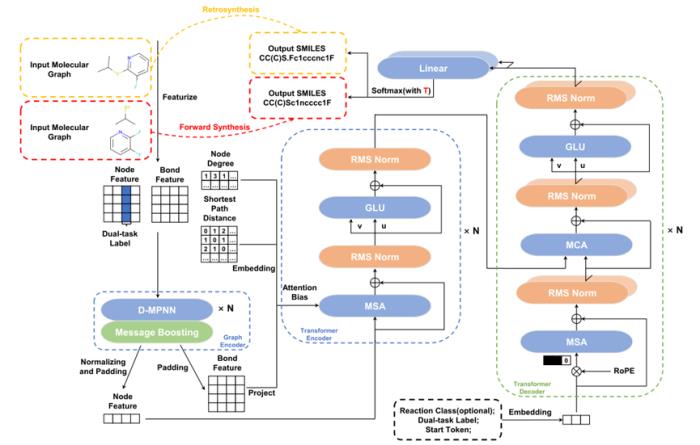
雙任務訓練框架
逆合成與正向反應預測作為目標相對的兩個任務,它們之間存在有非常緊密的聯系;因為將以產物作為輸入,反應物作為目標輸出的逆合成任務中的輸入與目標輸出互換即可轉換至正向反應預測任務。
因此,部分基于 SMILES 的無模板模型已經嘗試通過將逆合成與正向反應預測同時作為訓練目標來提升模型對化學反應的理解,并取得了一定的成效。基于此,作者進一步嘗試在圖至序列的模型中融入雙任務訓練。
具體來說,作者基于之前已在其它方法上使用過的參數共享策略,僅在解碼器的歸一化層與最終的線性層內構建了任務特異的兩套參數,而在其它模塊中對兩類任務共享一套參數,同時額外在輸入的分子圖節點以及解碼器的初始輸入序列中額外加入了雙任務標簽,以此在控制整體模型規模的情況下使模型能夠區分兩類任務并分別學習兩類任務的不同數據分布。
訓練與推理優化
在訓練過程中,作者進一步記錄并分析了模型在訓練過時所反映出了兩類問題。
首先,作者記錄了不同 SMILES 字符在 USPTO-50k 中的出現頻次以及其在訓練時對應的預測準確率,如圖 2 所示。在訓練過程中,對于在訓練集中占比分別為 0.4% 和 0.3% 的 S 與 Br,它們之間整體預測準確率的絕對差異達到了 8%。這初步表明了不同的分子結構/片段間預測的難度存在明顯的差異,由此,作者通過引入不平衡損失函數(如Focal Loss)來緩解此類問題,從而使模型能夠更加關注訓練時準確率更低的分子片段。
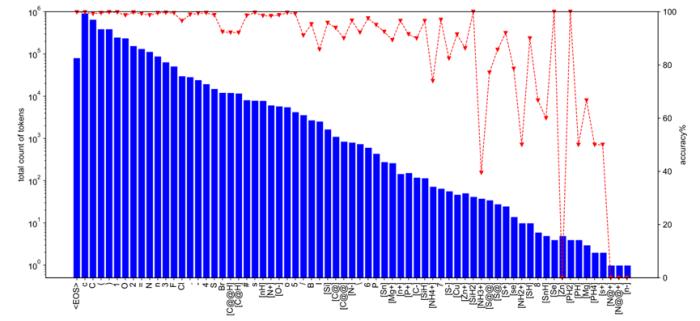
圖 2:USPTO-50k 訓練集中不同SMILES字符的出現頻次以及其在訓練時的整體預測準確率
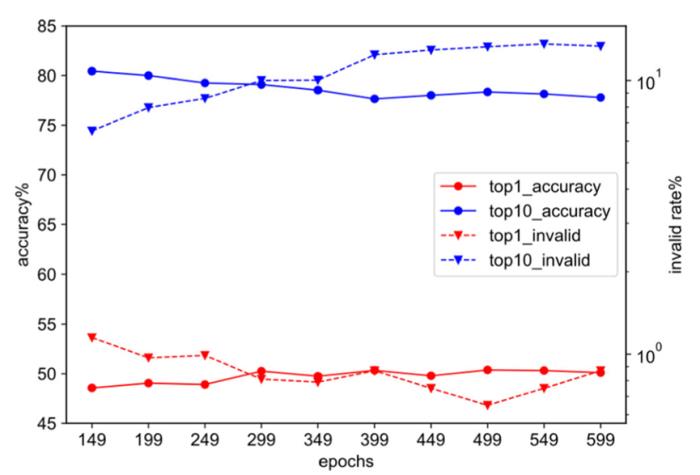
此外,作者進一步記錄了模型在訓練期間于驗證集中的預測結果質量變化,如圖 3 所示。作者發現在 USPTO-50k 的中后期訓練期間,模型整體在驗證集上的 Top-1 準確率仍然呈現一定的上升趨勢,但在 Top-3,5,10 的預測質量上存在有明顯的下滑。
為了在提升模型 Top-1 預測質量的同時保持模型前十位反應物生成結果的整體質量,作者額外構建了一類基于自定義評價指標的模型集成策略。具體來說,作者構建了一類存儲模型的隊列,同時依據預定義的評價指標(如 Top-1 準確率,加權的 Top-k 準確率等)對存入的模型進行排序;由此在整個訓練過程中動態的存入待選模型并自動生成基于隊列中前 3-5 位的集成模型,從而保留 Top-k 預測質量最高的模型。在推理階段,作者也基于新的框架重新構建了更加注重于搜索廣度的束搜索策略以提升模型 Top-k 生成結果的整體質量。
基準數據集雙任務實驗
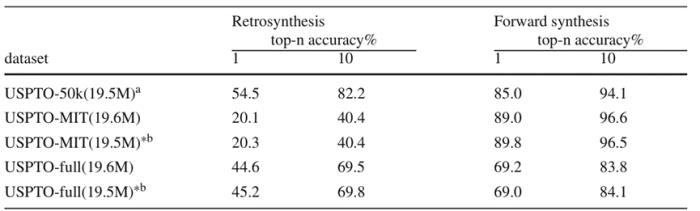
作者在分別包含 5 萬、50 萬以及 100 萬條化學反應的數據集 USPTO-50k、USPTO-MIT、USPTO-full 中分別測試了雙任務模型以及單任務模型在逆合成任務與正向反應預測任務中的表現,測試結果如圖4所示。
可以發現,在小規模數據集中,基于雙任務訓練的 BiG2S 在逆合成任務中取得了無模板逆合成模型中領先的預測精度,同時也保持了較高的正向反應預測精度;而在偏向于正向反應預測的 USPTO-MIT 數據集以及大規模數據集 USPTO-full 中。由于模型整體參數量的限制,導致引入雙任務訓練后的模型在更大規模數據集中的表現出現了降低。然而,從雙任務模型以幾乎一致的參數量與小幅度的反應預測能力降低( Top-k 準確率的絕對差值位于 0.5% 左右)獲得了同時處理逆合成任務與正向反應預測任務的能力這一角度來看,BiG2S 模型已經達到了預期目標。
消融實驗分析
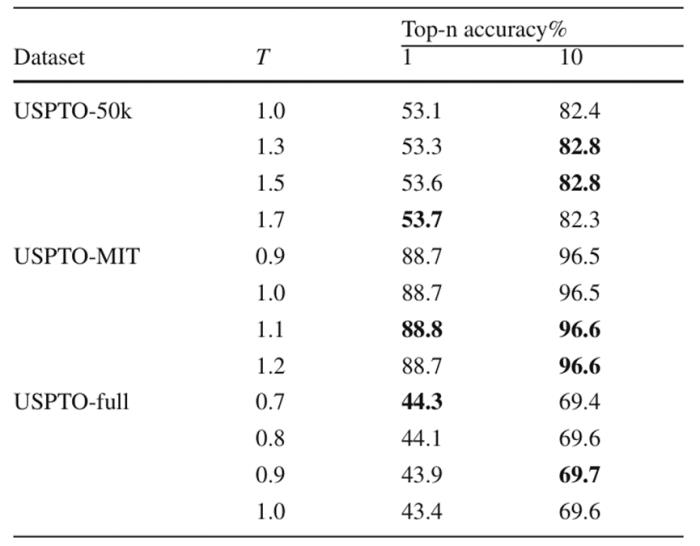
作者同時進一步通過消融實驗驗證了新的束搜索算法以及采用不平衡損失后 BiG2S 在不同數據集中進行預測的最適溫度超參數。這里的溫度超參數指 Softmax 中用于控制輸出概率分布的溫度參數 T,具體實驗結果分別如圖 5 與圖 6 所示。
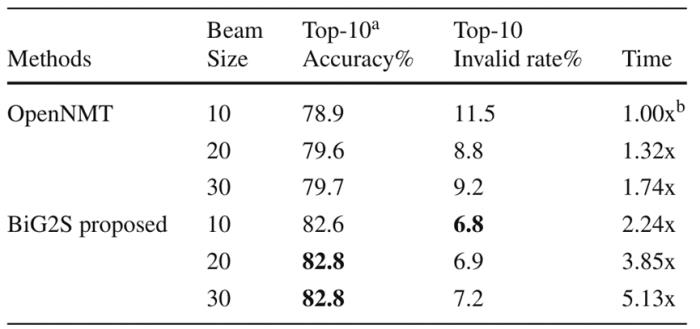
在針對束搜索算法的實驗中,可以發現 OpenNMT 在搜索寬度擴大至 3 倍的同時搜索耗時僅擴大至 1.74 倍,而新束搜索算法在 Top-1 精度與 OpenNMT一致的情況下整體的搜索耗時擴大了 1-2 倍;但在 Top-10 預測結果的質量上,新的束搜索算法與 OpenNMT 相比具有至少 3% 的絕對精度優勢以及 2% 的有效分子比例優勢,可以說新的束搜索算法以搜索耗時為帶來明顯提升了模型整體Top-k搜索結果的質量。
而在針對溫度超參數的實驗中,作者發現在小規模數據集上使用較大的溫度參數可以明顯提升整體的 Top-k 預測精度,而在更大規模的數據集中,由于 BiG2S 的模型規模無法完全的擬合所有的反應數據,此時選用更小的溫度參數往往有利于模型的搜索。
結論
本文中,作者提出了一類同時處理逆合成任務與正向反應預測任務的無模板反應預測模型 BiG2S。基于合適的參數共享策略與額外的雙任務標簽,BiG2S 能夠以較小的參數量在不同規模的數據集上以單一模型完成逆合成任務與反應預測任務,且整體預測能力與主流模型達到了同一水平。
而針對模型訓練時所反映出的不同 SMILES 字符預測難度不均衡以及 Top-k 預測精度波動的問題,作者額外引入了不平衡損失,基于自定義評價指標的模型自動集成策略,以及基于新框架的束搜索算法以緩解這兩類問題。
最終,BiG2S 在三個不同規模的主流數據集上均表現出了較好的雙任務預測能力,而進一步的消融實驗也證明了額外引入的訓練與推理策略的有效性。
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
