

 新火種
2023-12-17
新火種
2023-12-17 


Transformer不讀《紅樓夢(mèng)》,上下文長(zhǎng)度真的越長(zhǎng)越好?
原文來(lái)源:硅星人

圖片來(lái)源:由無(wú)界 AI生成
在 Transformer 的自注意力(self-attention)機(jī)制中,每個(gè)token都與其他所有的token有關(guān)聯(lián)。所以,如果我們有n個(gè)token,那么自注意力的計(jì)算復(fù)雜性是O(n^2)。隨著序列長(zhǎng)度n的增加,所需的計(jì)算量和存儲(chǔ)空間會(huì)按平方增長(zhǎng),這會(huì)導(dǎo)致非常大的計(jì)算和存儲(chǔ)開(kāi)銷。
這意味著,當(dāng)你已經(jīng)不滿足喂給大模型一個(gè)兩百字的段落,想扔給他一篇兩萬(wàn)字的論文,它的計(jì)算量增加了1萬(wàn)倍。
圖源:Harm de Vries博客
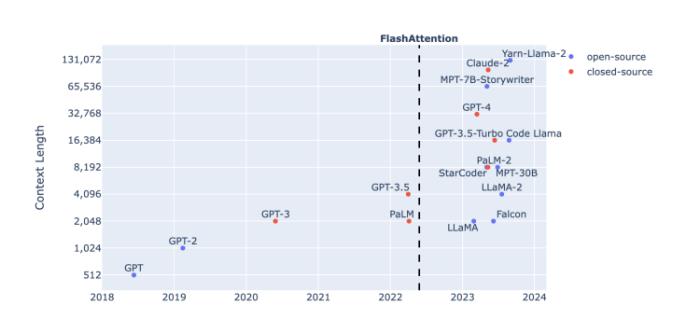
那個(gè)負(fù)責(zé)輸入和輸出的對(duì)話框就像人工智能通往現(xiàn)實(shí)世界的一個(gè)隘口。從ChatGPT第一次躍上4096個(gè)token,到GPT-4將上下文輸入長(zhǎng)度擴(kuò)展到32k,再到MetaAI提出的數(shù)百萬(wàn)tokens的MegaByte方法,以及國(guó)內(nèi)大模型廠商月之暗面和百川智能之間,20萬(wàn)與35萬(wàn)漢字的長(zhǎng)度競(jìng)賽,大模型解決實(shí)際問(wèn)題的進(jìn)程,輸入窗的胃口正在變成一個(gè)重要的先決條件。
換句話說(shuō),當(dāng)它讀《紅樓夢(mèng)》也能像讀一個(gè)腦筋急轉(zhuǎn)彎那么認(rèn)真仔細(xì),事情就好辦多了。
突破奇點(diǎn)落在了token數(shù)上。關(guān)于它的研究也從來(lái)沒(méi)有停下。
越長(zhǎng)越好?
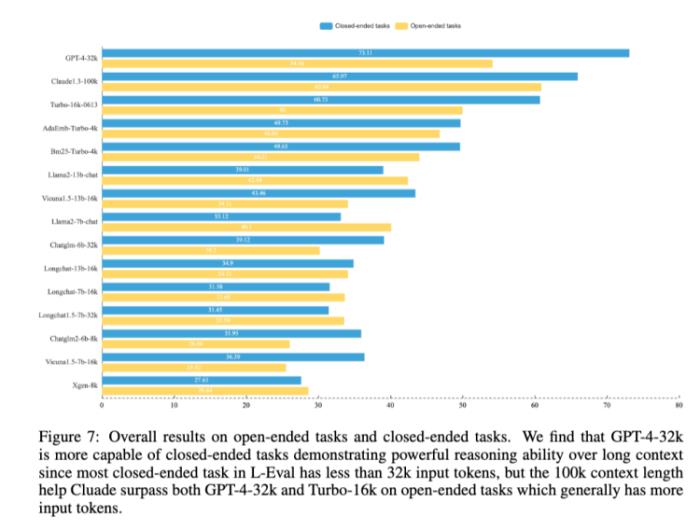
對(duì)于上下文長(zhǎng)度的推進(jìn)是必要的,復(fù)旦和香港大學(xué)的研究團(tuán)隊(duì)在一篇論文中做了論證。他們做了一個(gè)L-Eval的評(píng)價(jià)基準(zhǔn),在這個(gè)基準(zhǔn)的測(cè)試下,Claude-100k在封閉任務(wù)上的推理能力仍然弱于GPT-4-32k,但在開(kāi)放式任務(wù)中,長(zhǎng)度更長(zhǎng)——也就意味著通常擁有更多輸入標(biāo)記——的Claude-100k在表現(xiàn)上超過(guò)GPT-4-32k。
圖源:《L-Eval:Instituting Standardized Evaluation for Long Context Language Models》
結(jié)論很積極,意味著勤能補(bǔ)拙的故事仍然是成立的,如果腦子不好,你可以多囑咐幾句,笨一點(diǎn)的學(xué)生也能成事。
在那之前,Google Brain也已經(jīng)做了類似試驗(yàn),一直參與Bard的研發(fā)訓(xùn)練的工程師Li Wei告訴硅星人,去年Google團(tuán)隊(duì)已經(jīng)通過(guò)控制訓(xùn)練輸入上下文長(zhǎng)度的方式來(lái)觀察模型的輸出表現(xiàn),結(jié)果確實(shí)上下文長(zhǎng)度與模型表現(xiàn)成正相關(guān)。這個(gè)認(rèn)識(shí)也對(duì)后來(lái)Bard的研發(fā)有所幫助。
至少這是個(gè)業(yè)內(nèi)非常篤定的方向。那理論上,一直擴(kuò)展上下文長(zhǎng)度不就好了?
問(wèn)題是擴(kuò)張不得,而這個(gè)障礙仍然落在Transformer上。
梯度
基于transformer架構(gòu)的大模型,也就意味著接受了自注意力機(jī)制賦予的能力和限制。自注意力機(jī)制對(duì)理解能力鐘情,卻天然與長(zhǎng)文本輸入有所違背。文本越長(zhǎng),訓(xùn)練就越艱難,最壞的結(jié)果可能是梯度的爆炸或者消失。
梯度是參數(shù)更新的方向和大小。理想的訓(xùn)練下,大模型在生成內(nèi)容上與人類想要的回答之間的差距應(yīng)該在每一輪深度學(xué)習(xí)后都比之前更接近。如果把模型想象成試圖在學(xué)習(xí)一個(gè)線性關(guān)系y=wx+b的話,w表示模型正在尋找的那個(gè)權(quán)重。而梯度的概念就是在表達(dá)w是如何變化的。
一個(gè)穩(wěn)定的學(xué)習(xí)過(guò)程是漸進(jìn)的,漸進(jìn)意味著微調(diào)有跡可循。就是說(shuō)權(quán)重不能不變化,也不能突變。
不變化或者變化非常微弱——也就是梯度消失——意味著深度學(xué)習(xí)網(wǎng)絡(luò)的學(xué)習(xí)時(shí)間無(wú)限延長(zhǎng);突變則被叫做梯度爆炸,權(quán)重更新過(guò)大,導(dǎo)致網(wǎng)絡(luò)不穩(wěn)定。這可能會(huì)導(dǎo)致權(quán)重變得非常大或模型發(fā)散,使得訓(xùn)練無(wú)法進(jìn)行。
三角
而最核心的,短文本很多時(shí)候無(wú)法完整描述復(fù)雜問(wèn)題,而在注意力機(jī)制的限制下,處理長(zhǎng)文本需要大量算力,又意味著提高成本。上下文長(zhǎng)度本身決定了對(duì)問(wèn)題的描述能力,自注意力機(jī)制又決定了大模型的理解和拆解能力,而算力則在背后支撐了這一切。

圖源:ArXiv
問(wèn)題仍然在Transformer上,由于自注意力機(jī)制的計(jì)算復(fù)雜度問(wèn)題,上下文長(zhǎng)度的擴(kuò)展被困在一個(gè)三角形里。
這個(gè)不可能三角就擺在這兒,解決方案也在這里。為了增加上下文長(zhǎng)度,如果能夠把算力(錢和卡)推向無(wú)限顯然是最理想的。顯然現(xiàn)在這不現(xiàn)實(shí),那就只能動(dòng)注意力機(jī)制的心思,從而讓計(jì)算復(fù)雜度從n^2降下來(lái)。
對(duì)擴(kuò)展上下文輸入的努力很大程度上推動(dòng)者一場(chǎng)Transformer的革新。
Transformer變形記
谷歌DeepMind研究團(tuán)隊(duì)在今年7月提出了一種新的Focused Transformer(FoT)框架,它采用了一個(gè)受對(duì)比學(xué)習(xí)啟發(fā)的訓(xùn)練過(guò)程,以改善(key, value)空間的結(jié)構(gòu),并且允許一些注意力層通過(guò) k-最近鄰 (kNN) 算法訪問(wèn)外部記憶中的(key, value)對(duì)。這種機(jī)制有效地?cái)U(kuò)展了總的上下文長(zhǎng)度。
這有點(diǎn)像是谷歌在2022年另一個(gè)Memorizing Transformer的衍生,后者基于Transformer的調(diào)整邏輯是在編碼長(zhǎng)文本時(shí),模型一邊往下讀,邊把之前見(jiàn)過(guò)的所有 token 保存在一個(gè)數(shù)據(jù)庫(kù)中;在讀當(dāng)前片段時(shí),會(huì)用kNN 的方式找到數(shù)據(jù)庫(kù)中相似的內(nèi)容。
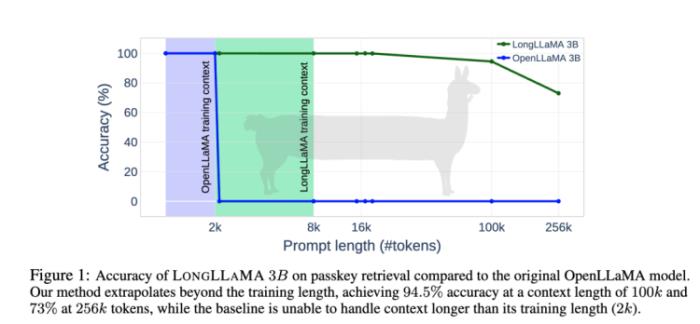
Focused Transformer和LLaMA-3B開(kāi)源模型做了結(jié)合,變成LongLLaMA-3B,再和LLaMA-3B在上下文輸入的長(zhǎng)度方面做了橫向?qū)Ρ取=Y(jié)果是上下文輸入長(zhǎng)度到100k之后,LongLLaMA-3B的回答準(zhǔn)確率才開(kāi)始從94.5%迅速下滑。而LLaMA-3B在超過(guò)2k就瞬間跌倒0了。
圖源:《Focused Transformer: Contrastive Training for Context Scaling》
從Transformer-XL在2019年出現(xiàn),引入了分段循環(huán)機(jī)制(Segment Recurrent Mechanism)為模型提供了額外的上下文,到一年后Longformer和BigBird引入了稀疏注意力機(jī)制,將長(zhǎng)度第一次擴(kuò)展到4096個(gè)tokens,循環(huán)注意力和稀疏注意力機(jī)制就開(kāi)始成為T(mén)ransformer的改造方向。
Focused Transformer通過(guò) kNN 算法也是實(shí)現(xiàn)了某種形式的稀疏注意力,更新的架構(gòu)調(diào)整方案則是Ring Attention。
今年10月,伯克利的團(tuán)隊(duì)提出了環(huán)注意力(Ring Attention),Ring Attention從內(nèi)存角度改變Transformer框架。通過(guò)分塊處理自注意力機(jī)制和前饋網(wǎng)絡(luò)計(jì)算的方法,上下文序列可以分布在多個(gè)設(shè)備上,并更有效地進(jìn)行分析。這也理論上消除了單個(gè)設(shè)備所施加的內(nèi)存限制,使得序列的訓(xùn)練和推斷能夠處理比之前的內(nèi)存效率更高的Transformer長(zhǎng)得多的序列。
也就是說(shuō),Ring Attention實(shí)現(xiàn)了“近乎無(wú)限的上下文”。
當(dāng)頭一棒
但這件事也不是絕對(duì)的。斯坦福在9月公布了一項(xiàng)研究表明,如果上下文太長(zhǎng),模型會(huì)略過(guò)中間不看。
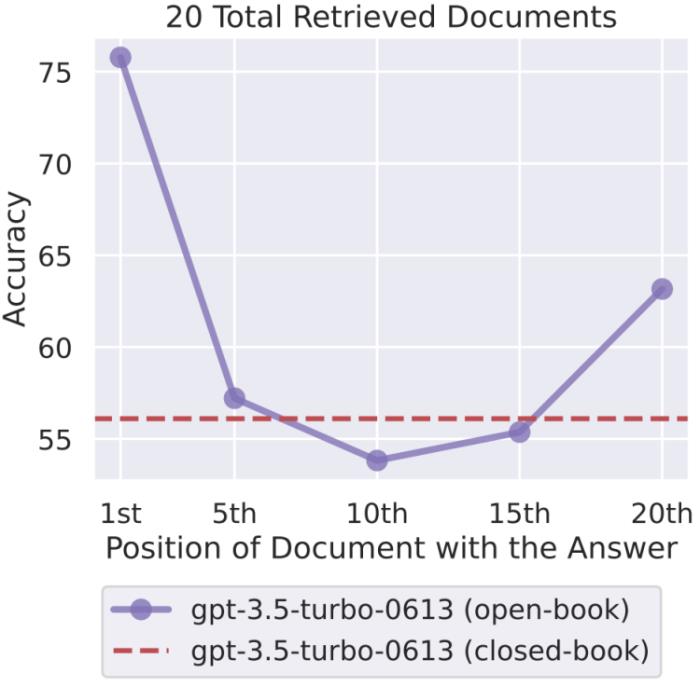
他們對(duì)多種不同的開(kāi)源(MPT-30B-Instruct、LongChat-13B (16K))和閉源(OpenAI 的 GPT-3.5-Turbo 和Anthropic 的 Claude)的語(yǔ)言模型進(jìn)行了對(duì)照實(shí)驗(yàn)。研究者通過(guò)向輸入上下文添加更多文檔來(lái)增大輸入上下文的長(zhǎng)度(類似于在檢索增強(qiáng)式生成任務(wù)中檢索更多文檔);以及通過(guò)修改輸入上下文中文檔的順序,將相關(guān)信息放置在上下文的開(kāi)頭、中間或結(jié)尾,從而修改上下文中相關(guān)信息的位置。
圖源:《Lost in the Middle: How Language Models Use Long Contexts》
結(jié)果是隨著相關(guān)信息位置的變化,模型性能呈現(xiàn)出明顯的 U 型趨勢(shì)。也就是說(shuō),當(dāng)相關(guān)信息出現(xiàn)在輸入上下文的開(kāi)頭或末尾時(shí),語(yǔ)言模型的性能最高;而當(dāng)模型必須獲取和使用的信息位于輸入上下文中部時(shí),模型性能會(huì)顯著下降。舉個(gè)例子,當(dāng)相關(guān)信息被放置在其輸入上下文中間時(shí),GPT3.5-Turbo 在多文檔問(wèn)題任務(wù)上的性能劣于沒(méi)有任何文檔時(shí)的情況(即閉卷設(shè)置;56.1%)。此外,研究者還發(fā)現(xiàn),當(dāng)上下文更長(zhǎng)時(shí),模型性能會(huì)穩(wěn)步下降;而且配有上下文擴(kuò)展的模型并不一定就更善于使用自己的上下文。
當(dāng)頭一棒!
但這或許也是好事,如果文章太長(zhǎng),人們大概也只會(huì)記得開(kāi)頭和結(jié)尾,大模型與人類大腦何其相似。
交鋒
目前全球主流的大模型中,GPT-4與LLaMA 2 Long的上下文長(zhǎng)度都已經(jīng)達(dá)到了32k,Claude 2.1達(dá)到200k。國(guó)內(nèi)的大模型中,ChatGLM-6B的上下文長(zhǎng)度達(dá)到了32k,最晚亮相的明星公司月之暗面直接拿出了一個(gè)200k的Kimi Chat。
月之暗面的思路同樣是改造Transformer,但楊植麟同時(shí)也引出一場(chǎng)交鋒。
蝌蚪模型和蜜蜂模型。
直白說(shuō),凹一個(gè)造型讓模型看起來(lái)可以支持更長(zhǎng)的上下文輸入有很多途徑,最簡(jiǎn)單的辦法是犧牲模型本身的參數(shù)。
模型參數(shù)的降低,意味著內(nèi)存消耗的減少以及計(jì)算的簡(jiǎn)單化,內(nèi)存和計(jì)算資源的重新分配能夠轉(zhuǎn)變成同樣算力資源下上下文輸入長(zhǎng)度的增加。回過(guò)頭來(lái)看,F(xiàn)ocused Transformer的驗(yàn)證放在一個(gè)3B的小參數(shù)模型上,對(duì)于Ring Attention的試驗(yàn)也更側(cè)重于所提出方法的有效性驗(yàn)證,而沒(méi)有經(jīng)歷百億參數(shù)以上的大模型。
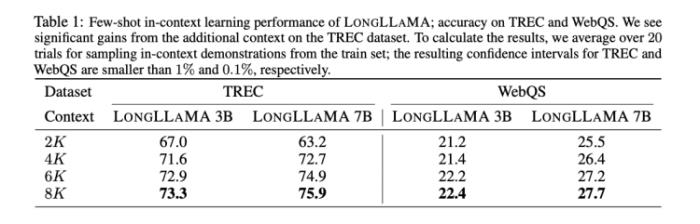
圖源:《Focused Transformer: Contrastive Training for Context Scaling》
但10億級(jí)別的模型參數(shù)并不具備太好的智能涌現(xiàn)能力。楊植麟形容其為蝌蚪模型,因?yàn)樗霾涣烁嗍虑椤?/p>
除此之外,另一種可以增加長(zhǎng)度的方式是從外部引入搜索機(jī)制。
探索的原理
這也是目前相當(dāng)多大模型能快速擴(kuò)展上下文長(zhǎng)度所采取的辦法——如果不動(dòng)自注意力機(jī)制,另一種方式就是把長(zhǎng)文本變成短文本的集合。
比如常見(jiàn)的Retrieval-augmented generation (RAG) 。它是一個(gè)結(jié)合了檢索 (retrieval) 和生成 (generation) 兩種機(jī)制的深度學(xué)習(xí)框架,目的是將信息檢索的能力引入到序列生成任務(wù)中,使得模型在生成響應(yīng)或內(nèi)容時(shí)可以利用一個(gè)外部的知識(shí)庫(kù)。
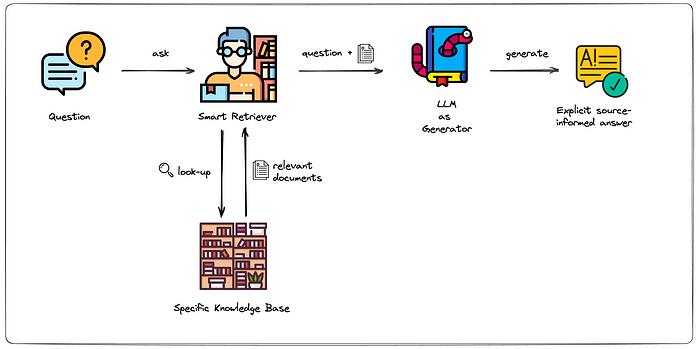
圖源:Towhee
模型在處理長(zhǎng)文本時(shí),引入的搜索機(jī)制會(huì)在數(shù)據(jù)庫(kù)中對(duì)短文本進(jìn)行檢索,以此來(lái)獲得多個(gè)短文本回答構(gòu)成的長(zhǎng)文本。每次只加載所需要的短文本片段,從而避開(kāi)了模型無(wú)法一次讀入整個(gè)長(zhǎng)文本的問(wèn)題。
楊植麟將這類模型稱為蜜蜂模型。
傳統(tǒng)的 Transformer 機(jī)構(gòu),如 GPT,其輸入長(zhǎng)度有限,通常限于幾百到幾千的token。這意味著當(dāng)需要處理大量的信息或長(zhǎng)文檔時(shí),模型可能會(huì)遇到困難。RAG 通過(guò)其檢索機(jī)制可以在一個(gè)大型的外部知識(shí)庫(kù)中檢索信息,然后僅將最相關(guān)的片段與原始輸入一起送入生成模型。這使得模型能夠處理比其原始輸入長(zhǎng)度更大。
這個(gè)觀點(diǎn)背后的原理很有意思。如果循環(huán)注意力和稀疏注意力都是在模型內(nèi)部對(duì)注意力機(jī)制進(jìn)行改進(jìn),屬于模型結(jié)構(gòu)級(jí)的優(yōu)化,那么通過(guò)在外部數(shù)據(jù)庫(kù)中檢索相關(guān)信息片段,然后將最相關(guān)的片段與原始輸入一起送入生成模型,來(lái)避免直接處理完整的長(zhǎng)文本,這僅僅屬于輸入級(jí)的優(yōu)化。
這種方法的主要目的是從大量的文檔中快速捕獲與當(dāng)前問(wèn)題最相關(guān)的信息片段,而這些信息片段可能只代表了原始輸入的部分上下文或某些特定方面。也就是說(shuō),這種方法更重視局部的信息,可能無(wú)法把握一個(gè)長(zhǎng)文本輸入的整體含義。
就像蜂巢中互相隔開(kāi)的一個(gè)個(gè)模塊。
蜜蜂模型的說(shuō)法有一些戲謔意味的指向了市面上用外掛搜索來(lái)拓展窗口容量的大模型廠商,很難讓人不想到近幾個(gè)月發(fā)展迅速,一直強(qiáng)調(diào)自己“搜索基因”的百川智能。
10月30日,百川智能發(fā)布全新的Baichuan2-192K大模型。上下文窗口長(zhǎng)度拉長(zhǎng)到192K,折算成漢字約等于35萬(wàn)字。月之暗面的Kimi Chat才將Claude-100k的上下文長(zhǎng)度擴(kuò)充了2.5倍,Baichuan2-192K又幾乎把Kimi Chat的上限翻了倍。
在長(zhǎng)窗口文本理解評(píng)測(cè)榜單LongEval上,Baichuan2-192K的表現(xiàn)遠(yuǎn)優(yōu)于Claude-100k,在窗口長(zhǎng)度超過(guò) 100K后依然能夠保持強(qiáng)勁性能,后者在70k之后的表現(xiàn)就極速下跌了。
也沒(méi)這么多長(zhǎng)文本
但關(guān)于“我們?yōu)槭裁床辉囋嚫L(zhǎng)的上下文”這個(gè)問(wèn)題,還有另一個(gè)觀察角度。
公開(kāi)可用的互聯(lián)網(wǎng)抓取數(shù)據(jù)集CommonCrawl是 LLaMA 訓(xùn)練數(shù)據(jù)集的主要數(shù)據(jù)來(lái)源,包括從CommonCrawl中獲取的另一個(gè)主要的數(shù)據(jù)集C4,兩者占據(jù)了LLaMA 訓(xùn)練數(shù)據(jù)集中的82%,
CommonCrawl中的語(yǔ)料數(shù)據(jù)是很短的。ServiceNow 的研究員Harm de Vries在一篇分析文章中表示,這個(gè)占比龐大的數(shù)據(jù)集中,95%以上的語(yǔ)料數(shù)據(jù)文件的token數(shù)少于2k,并且實(shí)際上其中絕大多數(shù)的區(qū)間在1k以下。
圖源:Harm de Vries博客
“如果要在其中尋找到有明顯上下文邏輯的長(zhǎng)文本就更少了”,Li Wei說(shuō)。
更長(zhǎng)的訓(xùn)練預(yù)料被寄希望于書(shū)籍或論文甚至者維基百科等來(lái)源。Harm de Vries的研究表明,有50%以上的維基百科文章的詞元數(shù)超過(guò)了4k個(gè)tokens,75%以上的圖書(shū)詞元數(shù)超過(guò)了16k個(gè)tokens。但無(wú)奈以LLaMA訓(xùn)練預(yù)料的主要數(shù)據(jù)來(lái)源分布來(lái)看,維基百科和書(shū)籍的占比都僅僅是4.5%,論文(ArXiv)的占比只有2.5%。三者相加只有270GB的數(shù)據(jù),不到CommonCrawl一成。
或許目前也壓根沒(méi)有這么多長(zhǎng)文本語(yǔ)料能夠用于訓(xùn)練,Transformer們不讀《紅樓夢(mèng)》也沒(méi)有那么多《紅樓夢(mèng)》可讀,是橫貫在所有追求上下文長(zhǎng)度的人們面前真正的難題。
Tags:
相關(guān)推薦




- 免責(zé)聲明
- 本文所包含的觀點(diǎn)僅代表作者個(gè)人看法,不代表新火種的觀點(diǎn)。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對(duì)本文可能提及或鏈接的任何項(xiàng)目不表示認(rèn)可。 交易和投資涉及高風(fēng)險(xiǎn),讀者在采取與本文內(nèi)容相關(guān)的任何行動(dòng)之前,請(qǐng)務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨(dú)立判斷。新火種不對(duì)因依賴本文觀點(diǎn)而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
