

 新火種
2023-12-12
新火種
2023-12-12 


一句話解鎖100k+上下文大模型真實力,27分漲到98,GPT-4、Claude2.1適用
各家大模型紛紛卷起上下文窗口,Llama-1時標配還是2k,現在不超過100k的已經不好意思出門了。
然鵝一項極限測試卻發現,大部分人用法都不對,沒發揮出AI應有的實力。
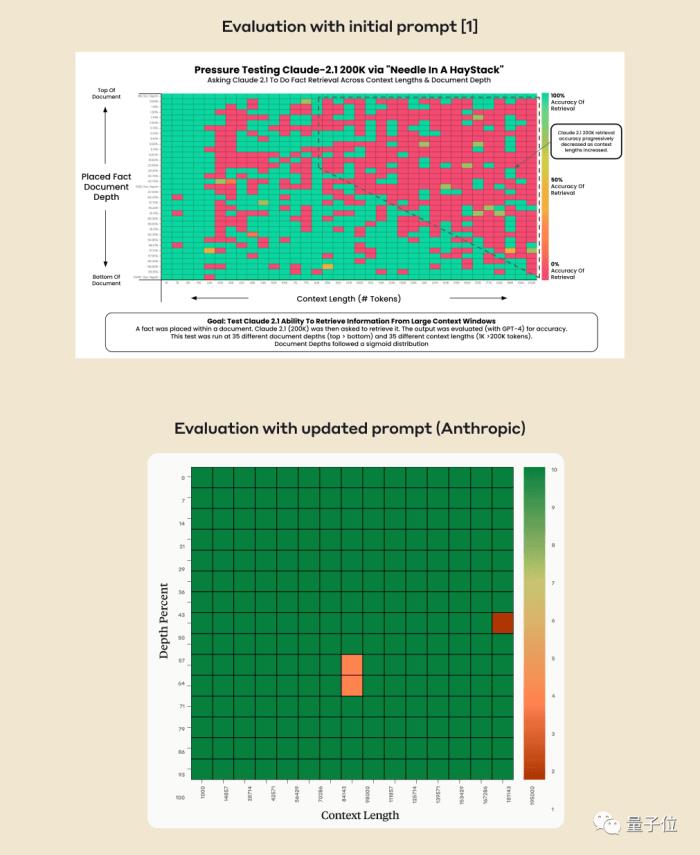
AI真的能從幾十萬字中找到特定關鍵事實嗎?顏色越紅代表AI犯的錯越多。
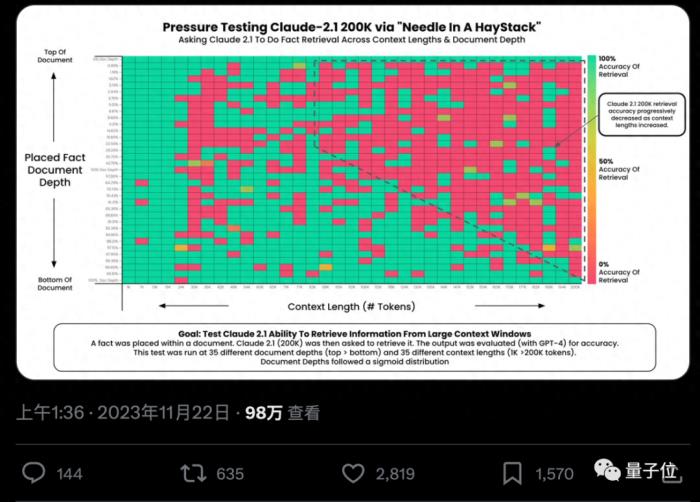
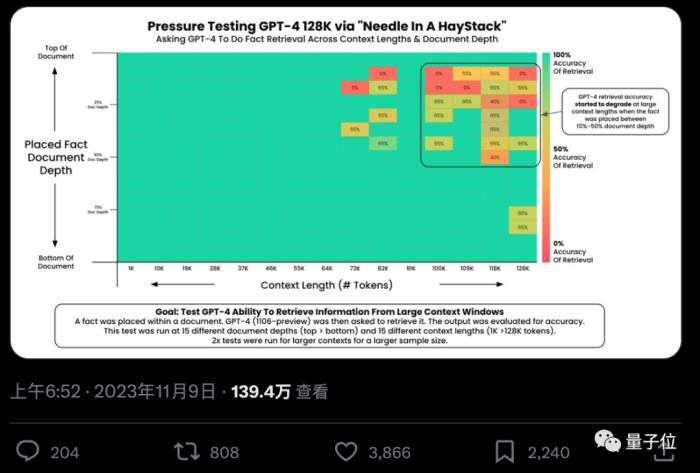
默認情況下,GPT-4-128k和最新發布的Claude2.1-200k成績都不太理想。
但Claude團隊了解情況后,給出超簡單解決辦法,增加一句話,直接把成績從27%提升到98%。
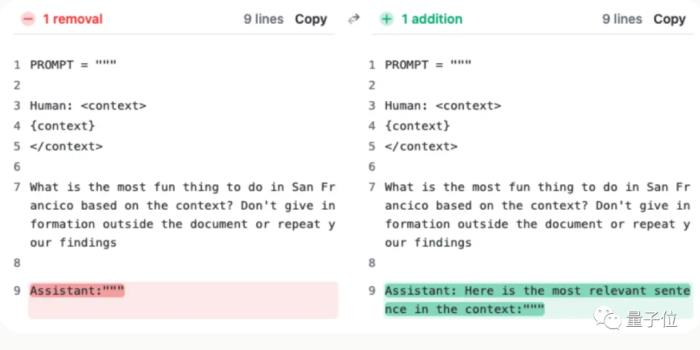
只不過這句話不是加在用戶提問上的,而是讓AI在回復的開頭先說:
“Here is the most relevant sentence in the context:”
(這就是上下文中最相關的句子:)
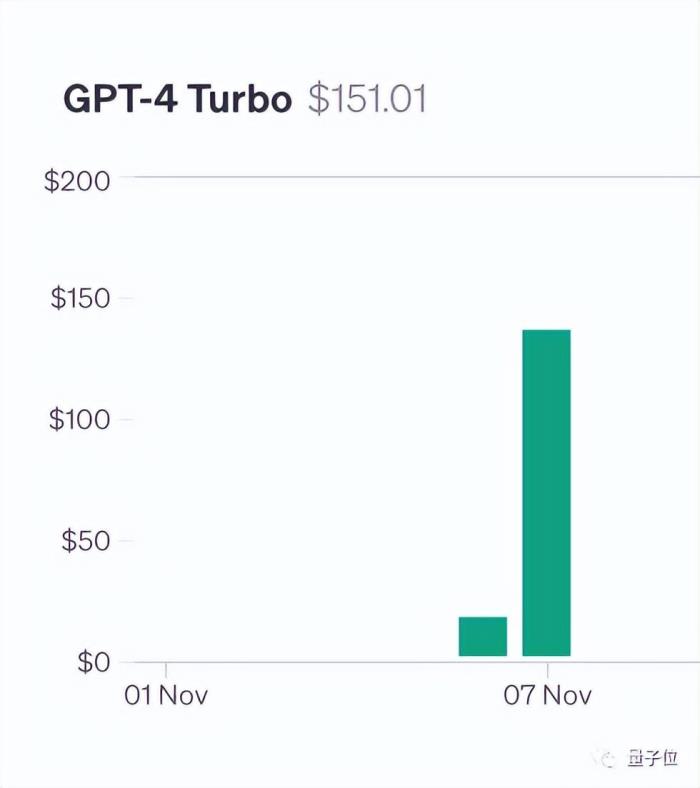
讓大模型大海撈針為了做這項測試,作者Greg Kamradt自掏腰包花費了至少150美元。
好在測試Claude2.1時,Anthropic伸出援手給他提供了免費額度,不然還得多花1016美元。
其實測試方法也不復雜,都是選用YC創始人Paul Graham的218篇博客文章當做測試數據。
在文檔中的不同位置添加特定語句:在舊金山最好的事情,就是在陽光明媚的日子坐在多洛雷斯公園吃一個三明治。
請GPT-4和Claude2.1僅僅使用所提供的上下文來回答問題,在不同上下文長度和添加在不同位置的文檔中反復測試。

最后使用Langchain Evals庫來評估結果。
作者把這套測試命名為“干草堆里找針/大海撈針”,并把代碼開源在GitHub上,已獲得200+星,并透露已經有公司贊助了對下一個大模型的測試。
AI公司自己找到解決辦法
幾周后,Claude背后公司Anthropic仔細分析后卻發現,AI只是不愿意回答基于文檔中單個句子的問題,特別是這個句子是后來插入的,和整篇文章關系不大的時候。
也就是說,AI判斷這句話和文章主題無關,就偷懶不去一句一句找了。

這時就需要用點手段晃過AI,要求Claude在回答開頭添加那句“Here is the most relevant sentence in the context:”就能解決。
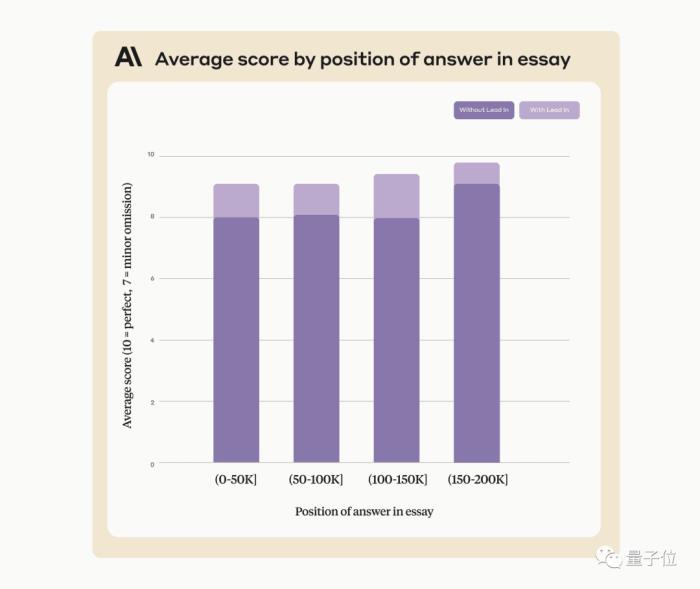
使用這個辦法,在尋找不是后來人為添加、本來就在原文章中的句子時,也能提高Claude的表現。
Anthropic公司表示將來會不斷的繼續訓練Claude,讓它能更適應此類任務。
在API調用時要求AI以指定開頭回答,還有別的妙用。
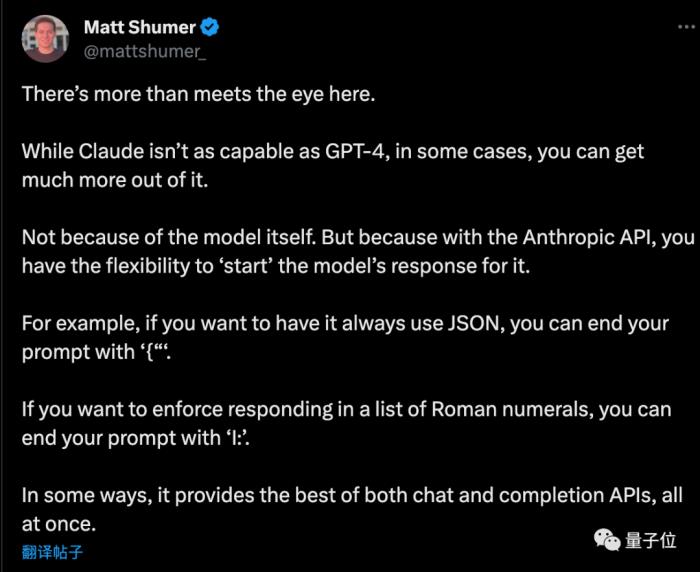
創業者Matt Shumer看過這個方案后補充了幾個小技巧:
如果想讓AI輸出純JSON格式,提示詞的最后以“{”結尾。同理,如果想讓AI列出羅馬數字,提示詞以“I:”結尾就行。
不過事情還沒完……
國內大模型公司也注意到了這項測試,開始嘗試自家大模型能不能通過。
同樣擁有超長上下文的月之暗面Kimi大模型團隊也測出了問題,但給出了不同的解決方案,也取得了很好的成績。

這樣一來,修改用戶提問Prompt,又比要求AI在自己的回答添加一句更容易做到,特別是在不是調用API,而是直接使用聊天機器人產品的情況下。
月之暗面還用自己的新方法幫GPT-4和Claude2.1測試了一下,結果GPT-4改善明顯,Claude2.1只是稍微改善。
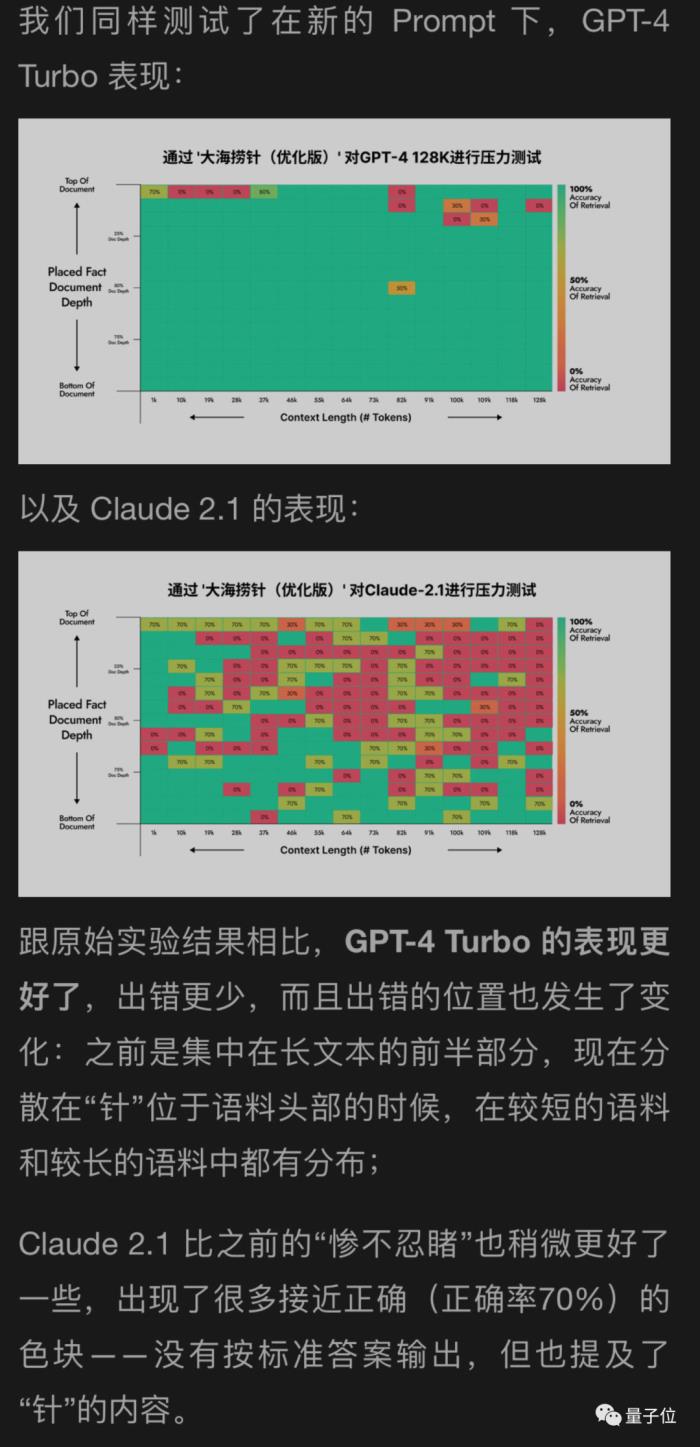
看來這個實驗本身有一定局限性,Claude也是有自己的特殊性,可能與他們自己的對齊方式Constituional AI有關,需要用Anthropic自己提供的辦法更好。
后來,月之暗面的工程師還搞了更多輪實驗,其中一個居然是……

壞了,我成測試數據了。

相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
