

 新火種
2023-12-08
新火種
2023-12-08 


伯克利分校推開放大模型Starling-7B接受人工智能反饋訓練
要點:
由加州大學伯克利分校研究人員推出的Starling-7B是一款基于Reinforcement Learning from AI Feedback(RLAIF)的開放式大型語言模型(LLM),采用人工智能反饋來提升其性能,特別是在聊天機器人響應方面。
RLAIF采用來自其他人工智能模型的反饋進行訓練,以改進模型的性能。相比于以往的人工反饋,AI反饋具有更低的成本、更快的速度、更透明和更可擴展的潛力。Starling-7B通過RLAIF在性能上取得了顯著的改進。
Starling-7B在兩個基準測試中(MT-Bench和AlpacaEval)表現優異,尤其在安全性和幫助性方面。研究人員指出,雖然RLAIF主要提高了模型的幫助性和安全性,但在基本能力方面,如回答基于知識的問題、數學或編碼,改進不大。未來的研究方向可能包括引入高質量的人工反饋數據,以更好地適應模型對人類需求的理解。
站長之家11月29日 消息:加州大學伯克利分校的研究人員推出了一款名為Starling-7B的開放式大型語言模型(LLM),采用了一種稱為Reinforcement Learning from AI Feedback(RLAIF)的創新訓練方法。
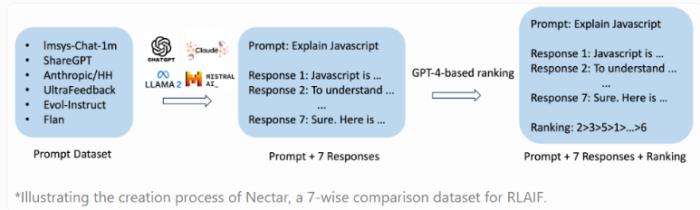
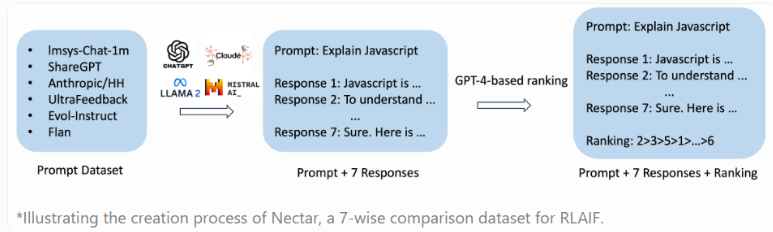
RLAIF的獨特之處在于利用其他人工智能模型的反饋來提升性能,相較于傳統的人工反饋,這種方法更具有成本效益、速度快、透明度高、可擴展性強的優勢。Starling-7B基于新的Nectar數據集進行訓練,包含183,000個聊天提示和380萬個成對比較。
研究人員使用兩個基準測試(MT-Bench和AlpacaEval)評估了Starling-7B的性能,這兩個測試使用GPT-4進行評分,分別關注模型在簡單指令跟隨任務中的安全性和幫助性。Starling-7B在MT-Bench中表現良好,與OpenAI的GPT-4和GPT-4Turbo相媲美,在AlpacaEval中達到了與商業聊天機器人相當的水平。
研究人員指出,RLAIF主要改善了模型的幫助性和安全性,而在基本能力方面,如回答基于知識的問題、數學或編碼等,改進較小。
盡管基準測試的實際應用有限,但對RLAIF的應用前景充滿希望。研究人員建議的下一步是通過引入高質量的人工反饋數據,更好地調整模型以滿足人類需求。
與此同時,研究人員強調,Starling-7B和其他類似的大型語言模型在需要推理或數學任務時仍然存在困難,并可能產生幻覺。他們將Nectar數據集、Starling-RM-7B-alpha獎勵模型和Starling-LM-7B-alpha語言模型發布在Hugging Face上,并提供了研究許可證,代碼和論文將很快公開。感興趣的人還可以在聊天機器人領域測試該模型。
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
