來自阿里的研究團隊提出了一種名為 Animate Anyone 的方法,只需一張人物照片,再配合骨骼動畫引導,就能生成動畫視頻。
最近一段時間,你可能或多或少的聽到過「科目三」,搖花手、半崴不崴的腳,配合著節奏鮮明的音樂,這一舞蹈動作遭全網模仿。如果相似的舞蹈,讓 AI 生成會怎樣?就像下圖所展示的,不管是現代人、還是紙片人,都做著整齊劃一的動作。你可能猜不到的是,這是根據一張圖片生成的舞蹈視頻。

人物動作難度加大,生成的視頻也非常絲滑(最右邊):

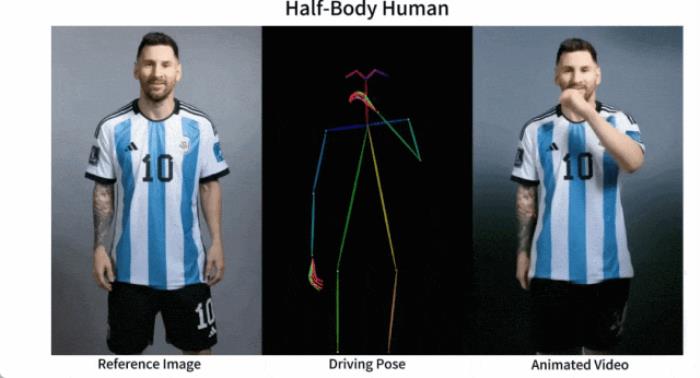
讓梅西、鋼鐵俠動起來,也不在話下:

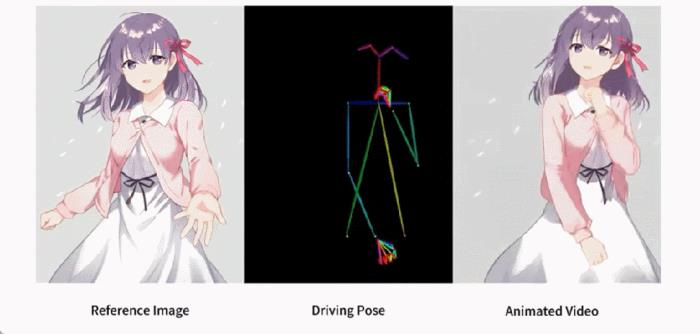
還有各種動漫小姐姐。
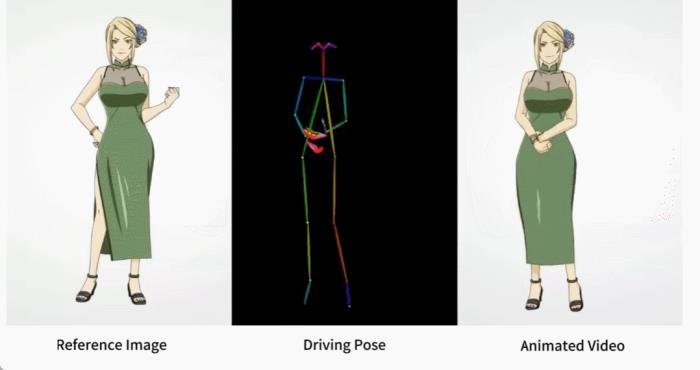
上述效果是如何做到的呢?我們接著往下看。角色動畫(Character Animation)是將源角色圖像按照所需的姿態序列動畫化為逼真視頻的任務,具有許多潛在的應用,例如在線零售、娛樂視頻、藝術創作和虛擬角色等。從 GAN 開始,研究者一直在不斷深入了解將圖像進行動畫化以及進行姿態遷移的探索,然而,生成的圖像或視頻仍然存在局部失真、細節模糊、語義不一致和時間不穩定等問題,從而阻礙了這些方法的應用。本文,來自阿里的研究者提出了一種名為 Animate Anybody 的方法,該方法能夠將角色圖像轉換為動畫視頻,而形成的視頻遵循所要求的姿態序列。該研究繼承了 Stable Diffusion 的網絡設計和預訓練權重,并修改了去噪 UNet 以適應多幀輸入。
為了保持外觀一致性,該研究還引入了 ReferenceNet,它被設計為對稱的 UNet 結構,用于捕獲參考圖像的空間細節。在 UNet 塊的每個相應層,該研究使用空間 - 注意力將 ReferenceNet 的特征集成到去噪 UNet 中,這種架構使模型能夠在一致的特征空間中全面學習與參考圖像的關系。為了確保姿態可控性,該研究設計了一種輕量級姿態引導器,以有效地將姿態控制信號集成到去噪過程中。為了實現時間穩定性,本文引入了時間層( temporal layer)來對多個幀之間的關系進行建模,從而在模擬連續且平滑的時間運動過程的同時保留視覺質量的高分辨率細節。Animate Anybody 是在 5K 角色視頻剪輯的內部數據集上訓練而成,圖 1 顯示了各種角色的動畫結果。與以前的方法相比,本文的方法具有幾個顯著的優點:首先,它有效地保持了視頻中人物外觀的空間和時間一致性。其次,它生成的高清視頻不會出現時間抖動或閃爍等問題。第三,它能夠將任何角色圖像動畫化為視頻,不受特定領域的限制。本文在兩個特定的人類視頻合成基準(UBC 時尚視頻數據集和 TikTok 數據集)上進行了評估。結果顯示,Animate Anybody 取得了 SOTA 結果。此外,該研究還將 Animate Anybody 方法與在大規模數據上訓練的一般圖像到視頻方法進行了比較,結果顯示 Animate Anybody 在角色動畫方面展示了卓越的能力。

Animate Anybody 與其他方法的比較:

方法介紹本文方法如下圖 2 所示,網絡的初始輸入由多幀噪聲組成。研究者基于 SD 設計來配置去噪 UNet,采用了相同的框架和塊單元,并繼承了來自 SD 的訓練權重。具體來講,該方法包含了三個關鍵組成部分,分別如下:ReferenceNet,編碼參考圖像角色的外觀特征;Pose Guider(姿態引導器),編碼動作控制信號以實現可控角色運動;Temporal layer(時間層),編碼時間關系以確保角色動作的連續性。
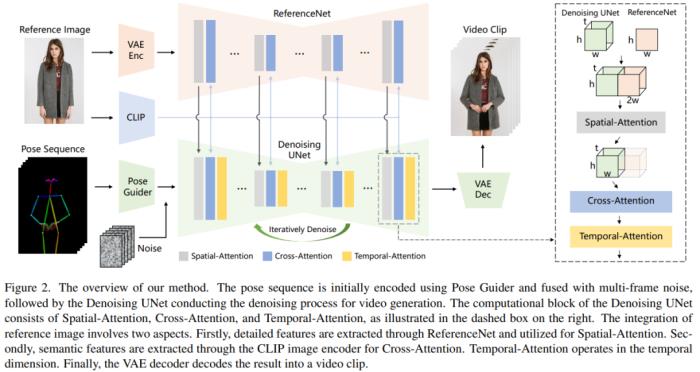
ReferenceNetReferenceNet 是一個參考圖像特征提取網絡,它的框架與去噪 UNet 大致相同,僅有時間層不同。因此,ReferenceNet 繼承了與去噪 UNet 類似的原始 SD 權重,并且每個權重更新都是獨立進行的。研究者解釋了將 ReferenceNet 的特征集成到去噪 UNet 的方法。ReferenceNet 的設計有兩個優勢。第一,ReferenceNet 可以利用原始 SD 的預訓練圖像特征建模能力,產生初始化良好的特征。第二,由于 ReferenceNet 與去噪 UNet 本質上具有相同的網絡結構和共享初始化權重,因而去噪 UNet 可以選擇性地從 ReferenceNet 中學習在同一特征空間關聯的特征。姿態引導器輕量級的姿態引導器使用四個卷積層(4×4 內核、2×2 步幅、使用 16、32、64、128 個通道,類似于 [56] 中的條件編碼器)來對齊分辨率與潛在噪聲相同的姿態圖像,接著處理后的姿態圖像在被輸入到去噪 UNet 之前添加到潛在噪聲中。姿態引導器使用高斯權重進行初始化,并在最終的映射層用到了零卷積。時間層時間層的設計靈感來自 AnimateDiff。對于一個特征圖 x∈R^b×t×h×w×c,研究者首先將它變形為 x∈R^(b×h×w)×t×c,然后執行時間注意力,即沿著維度 t 的自注意力。時間層的特征通過殘差連接合并到了原始特征中,這種設計與下文的雙階段訓練方法相一致。時間層專門在去噪 UNet 的 Res-Trans 塊內使用。
訓練策略訓練過程分為兩個階段。第一階段,使用單個視頻幀進行訓練。在去噪 UNet 中,研究者暫時排除了時間層,模型將單幀噪聲作為輸入。參考網絡和姿態引導器也在這一階段進行訓練。參考圖像是從整個視頻片段中隨機選取的。他們根據 SD 的預訓練權重初始化去噪 UNet 和 ReferenceNet 的模型。姿態引導器使用高斯權重進行初始化,但最后的投影層除外,該層使用零卷積。VAE 的編碼器和解碼器以及 CLIP 圖像編碼器的權重都保持不變。這一階段的優化目標是使模型在給定參考圖像和目標姿態的條件下生成高質量的動畫圖像。在第二階段,研究者將時間層引入先前訓練好的模型,并使用 AnimateDiff 中預先訓練好的權重對其進行初始化。模型的輸入包括一個 24 幀的視頻片段。在這一階段,只訓練時間層,同時固定網絡其他部分的權重。實驗與結果定性結果:如圖 3 顯示,本文方法可以制作任意角色的動畫,包括全身人像、半身人像、卡通人物和仿人角色。該方法能夠生成高清晰度和逼真的人物細節。即使在大幅度運動的情況下,它也能與參考圖像保持時間上的一致性,并在幀與幀之間表現出時間上的連續性。

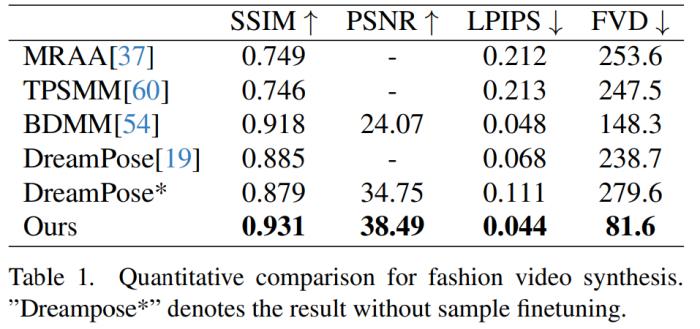
時尚視頻合成。時尚視頻合成的目的是利用驅動姿態序列將時尚照片轉化為逼真的動畫視頻。實驗在 UBC 時尚視頻數據集上進行,該數據集由 500 個訓練視頻和 100 個測試視頻組成,每個視頻包含約 350 個幀。定量比較見表 1。在結果中可以發現,本文方法優于其他方法,尤其是在視頻度量指標方面表現出明顯的領先優勢。
定性比較如圖 4 所示。為了進行公平比較,研究者使用 DreamPose 的開源代碼獲得了未進行樣本微調的結果。在時尚視頻領域,對服裝細節的要求非常嚴格。然而,DreamPose 和 BDMM 生成的視頻無法保持服裝細節的一致性,并在顏色和精細結構元素方面表現出明顯的誤差。相比之下,本文方法生成的結果能更有效保持服裝細節的一致性。

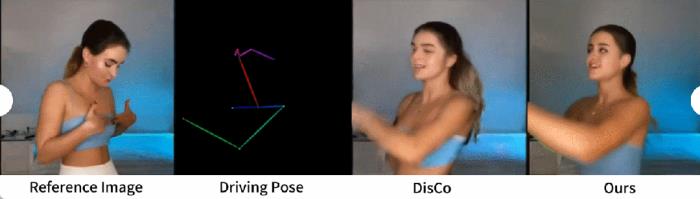
人類舞蹈生成。人類舞蹈生成聚焦于將現實舞蹈場景圖像進行動畫處理。研究者們使用了 TikTok 數據集,其中包括 340 個訓練視頻和 100 個測試視頻。按照 DisCo 的數據集劃分方法,使用利用相同的測試集,其中包含 10 個 TikTok 風格的視頻,研究者進行了定量比較,見表 2。本文方法取得了最佳結果。為了增強泛化能力,DisCo 結合了人類屬性預訓練,利用大量圖像對進行模型預訓練。相比之下,研究者訓練只在 TikTok 數據集上進行,結果優于 DisCo。
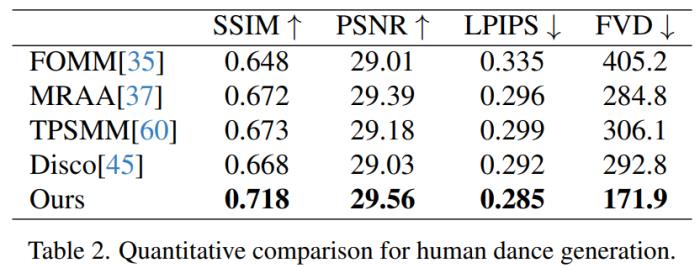
圖 5 中展示了與 DisCo 的定性比較。考慮到場景的復雜性,DisCo 的方法需要額外使用 SAM 來生成人類前景掩碼。相反,本文方法表明,即使沒有明確的人體掩碼學習,模型也能從被攝體的運動中掌握前景與背景的關系,而無需事先進行人體分割。此外,在復雜的舞蹈序列中,該模型在保持整個動作的視覺連續性方面表現突出,并在處理不同的角色外觀方面表現出更強的穩健性。

圖像 - 視頻的通用方法。目前,許多研究都提出了基于大規模訓練數據、具有強大生成能力的視頻擴散模型。研究者選擇了兩種最著名、最有效的圖像 - 視頻方法進行比較:AnimateDiff 和 Gen2。由于這兩種方法不進行姿態控制,因此研究者只比較了它們保持參考圖像外觀保真度的能力。如圖 6 所示,當前的圖像 - 視頻方法在生成大量角色動作方面面臨挑戰,并且難以在視頻中保持長期的外觀一致性,從而阻礙了對一致角色動畫的有效支持。

了解更多內容,請參考原論文。


 新火種
2023-12-05
新火種
2023-12-05 






