

 新火種
2023-12-04
新火種
2023-12-04 


ChatGPT發(fā)布一年后,馬斯克的大模型Grok也將正式上線
原文來源:阿爾法公社

圖片來源:由無界 AI生成
在ChatGPT發(fā)布一年之后,生成式AI已經(jīng)成為一個(gè)具有確定性的技術(shù)浪潮,而伊隆·馬斯克旗下的xAI公司計(jì)劃在本周將它11月初發(fā)布的大模型Grok接入X平臺(tái)(推特),對(duì)X Premium+訂閱者們開放。
xAI在今年7月成立,之后迅速訓(xùn)練出Grok-0這個(gè)基礎(chǔ)模型,然后又經(jīng)過調(diào)優(yōu)進(jìn)化成Grok-1。這個(gè)模型雖然參數(shù)只有大約330億,但是能力已經(jīng)超過llama2 70B和GPT-3.5,尤其在數(shù)學(xué)和編碼方面表現(xiàn)突出。研究團(tuán)隊(duì)也在大模型的推理能力和可靠性方面開展研究。
馬斯克組建了一個(gè)豪華的核心技術(shù)團(tuán)隊(duì),團(tuán)隊(duì)成員們來自DeepMind、OpenAI、谷歌研究院、微軟研究院、特斯拉和多倫多大學(xué),主導(dǎo)過多個(gè)AI基礎(chǔ)算法研究和知名AI項(xiàng)目,華人比例奇高,其中還有兩位研究人員的論文引用數(shù)超過20萬。
Grok將通過獨(dú)家訪問X(原推特)及其實(shí)時(shí)的用戶生成的帖子和信息來實(shí)現(xiàn)差異化,它能訪問在X上發(fā)布的最新數(shù)據(jù),并在用戶詢問實(shí)時(shí)問題時(shí)提供最新信息。
打造“追求真理的”的AI,馬斯克組建了豪華核心團(tuán)隊(duì)
作為xAI的創(chuàng)始人,馬斯克對(duì)AI有深刻的積累和認(rèn)知。一方面,早在2013年,他就開啟了特斯拉在自動(dòng)駕駛方面的探索,目前特斯拉的自動(dòng)駕駛硬件迭代到第四代,F(xiàn)SD算法迭代到V12版本,并將在近期更新。
另一方面,馬斯克是OpenAI的聯(lián)合創(chuàng)始人之一,當(dāng)OpenAI還是非盈利研究組織時(shí),他為OpenAI注入了5000萬-1億美元資金,支持它的早期發(fā)展。而OpenAI的聯(lián)合創(chuàng)始人之一Andrej Karpathy在2017年6月-2022年7月?lián)翁厮估腁I總監(jiān),主導(dǎo)著特斯拉的自動(dòng)駕駛項(xiàng)目。
2018年,馬斯克離開了OpenAI,根據(jù)OpenAI的博客文章和馬斯克后來的推文,理由是防止隨著特斯拉更加專注于人工智能而與OpenAI產(chǎn)生利益沖突;根據(jù)Semafor報(bào)道,馬斯克曾提議他接管OpenAI的領(lǐng)導(dǎo),并在提議被拒絕后離開;而《金融時(shí)報(bào)》報(bào)道稱,馬斯克的離開也是由于與其他董事會(huì)成員和員工在OpenAI的人工智能安全方法上的沖突。
在離開OpenAI多年,且ChatGPT引發(fā)了AI熱潮后,馬斯克于今年7月宣布成立xAI,這家公司的目標(biāo)是構(gòu)建能“理解宇宙真正本質(zhì)”的人工智能。
馬斯克在接受采訪時(shí)表示:“從人工智能安全的角度來看,一個(gè)極度好奇的人工智能,一個(gè)試圖理解宇宙的人工智能,將會(huì)支持人類。”
豪華的核心技術(shù)團(tuán)隊(duì)
馬斯克搭建了一個(gè)豪華的核心技術(shù)團(tuán)隊(duì),他們來自DeepMind、OpenAI、谷歌研究院、微軟研究院、特斯拉和多倫多大學(xué)。
他們?cè)谶^去主導(dǎo)過不少AI研究和技術(shù)的突破,例如Adam優(yōu)化器,對(duì)抗性示例,Transformer-XL,Memorizing Transformer,自動(dòng)形式化等。此外,還包括AlphaStar、AlphaCode、Inception、Minerva、GPT-3.5和GPT-4等工程和產(chǎn)品方面的重要成果。
這個(gè)團(tuán)隊(duì)除了來自大廠和研究院外,還有一個(gè)特點(diǎn)是大多數(shù)擁有扎實(shí)的數(shù)學(xué)、物理背景。

例如xAI聯(lián)合創(chuàng)始人楊格(Greg Yang )在哈佛取得數(shù)學(xué)學(xué)士與計(jì)算機(jī)碩士學(xué)位,師從丘成桐。丘成桐帶著楊格出席活動(dòng)、認(rèn)識(shí)各個(gè)方向的博士生、數(shù)學(xué)家,還推薦他申請(qǐng)數(shù)學(xué)界本科生能取得的最高榮譽(yù):摩根獎(jiǎng)。

楊格透露,xAI將深入研究人工智能的一個(gè)方面—“深度學(xué)習(xí)的數(shù)學(xué)”,并“為大型神經(jīng)網(wǎng)絡(luò)發(fā)展‘萬物理論’”,以將人工智能“提升到下一個(gè)層次”。
除了作為聯(lián)合創(chuàng)始人的楊格外,在核心團(tuán)隊(duì)中還有張國棟 (Guodong Zhang),戴自航 (Zihang Dai),吳宇懷(Yuhuai Tony Wu),以及之后加入的Jimmy Ba、xiao sun、Ting Chen等華人成員,他們都在底層技術(shù)上有建樹。
戴自航(Zihang Dai)是CMU和Google Brain于2019年發(fā)布預(yù)訓(xùn)練語言模型XLNet論文的共同一作,這個(gè)模型在20項(xiàng)任務(wù)上超越了當(dāng)時(shí)的SOTA模型BERT。

戴自航2009年入讀清華經(jīng)管學(xué)院的信息管理與信息系統(tǒng)專業(yè),此后前往 CMU開啟六年的計(jì)算機(jī)碩博生涯,師從Yiming Yang。在博士期間深度參與圖靈獎(jiǎng)得主Yoshua Bengio創(chuàng)立的Mila實(shí)驗(yàn)室,Google Brain團(tuán)隊(duì),并在博士畢業(yè)后正式加入Google Brain,擔(dān)任研究科學(xué)家,主要方向?yàn)樽匀徽Z言處理、模型預(yù)訓(xùn)練。
張國棟( Guodong Zhang)本科就讀于浙江大學(xué),他在輔修的竺可楨學(xué)院工程教育高級(jí)班中連續(xù)三年排名專業(yè)第一;此后,他前往多倫多大學(xué)攻讀機(jī)器學(xué)習(xí)博士學(xué)位。

讀博期間,他在Geoffrey Hinton的指導(dǎo)下,作為谷歌大腦團(tuán)隊(duì)的實(shí)習(xí)生從事大規(guī)模優(yōu)化與快速權(quán)重線性注意力研究(Large-scale optimization and fast-weights linear attention),而他也在多智能體優(yōu)化與應(yīng)用、深度學(xué)習(xí)、貝葉斯深度學(xué)習(xí)等領(lǐng)域發(fā)表頂會(huì)論文。
博士畢業(yè)后,張國棟全職加入DeepMind,成為Gemini計(jì)劃(直接對(duì)標(biāo)GPT-4)的核心成員,負(fù)責(zé)訓(xùn)練與微調(diào)大型語言模型。
吳宇懷 Yuhuai (Tony) Wu的高中和大學(xué)時(shí)光均在北美度過,他本科在紐布倫斯威克大學(xué)讀數(shù)學(xué),并在多倫多大學(xué)獲得機(jī)器學(xué)習(xí)學(xué)位,師從Roger Grosse和Jimmy Ba(也是xAI核心團(tuán)隊(duì)成員)。

在求學(xué)期間,吳宇懷在Mila,OpenAI,DeepMind和Google做過研究員。而在他的一項(xiàng)研究中,他和其他研究人員訓(xùn)練了一個(gè)增強(qiáng)大語言模型Minerva,這個(gè)模型數(shù)學(xué)能力很強(qiáng),在波蘭的2022年國家數(shù)學(xué)考試中,答對(duì)了65%的問題。這與xAI深入研究“深度學(xué)習(xí)的數(shù)學(xué)”的目標(biāo)非常匹配。
Jimmy Ba曾擔(dān)任多倫多大學(xué)的助理教授(AP),他的本碩博也都在多倫多大學(xué)完成,博士時(shí)的導(dǎo)師是Geoffrey Hinton。

他還是加拿大先進(jìn)研究院人工智能主席,長期目標(biāo)是如何構(gòu)建具有類人效率和適應(yīng)性的通用問題解決機(jī)器。Jimmy Ba在谷歌學(xué)術(shù)的引用數(shù)達(dá)到200844,而光是與Adam優(yōu)化器有關(guān)的論文就超過16萬,2015年與注意力相關(guān)的論文引用也超過1.1萬。他事實(shí)上也是現(xiàn)在大模型技術(shù)的理論奠基人之一。
xiao sun在北京大學(xué)獲得學(xué)士學(xué)位,在耶魯大學(xué)獲得EE的博士學(xué)位,此后在IBM Watson和Meta擔(dān)任研究科學(xué)家。他的技術(shù)背景不在于AI模型,而在于AI相關(guān)的硬件和半導(dǎo)體,尤其是AI的軟硬件協(xié)同。他曾獲得MIT TR35(35歲以下創(chuàng)新35人)獎(jiǎng)項(xiàng)。
Ting Chen在北京郵電大學(xué)獲得學(xué)士學(xué)位,在美國東北大學(xué)和UCLA分別獲得一個(gè)博士學(xué)位。之后他在谷歌Brain擔(dān)任研究科學(xué)家,他的谷歌學(xué)術(shù)總引用數(shù)達(dá)到22363。他引用數(shù)最高的論文提出SimCLR,一個(gè)簡單的視覺表示對(duì)比學(xué)習(xí)框架。這篇論文是與Geoffrey Hinton合作的,引用數(shù)達(dá)到了14579。
除了Jimmy Ba外,創(chuàng)始團(tuán)隊(duì)中還有另一位谷歌學(xué)術(shù)論文應(yīng)用數(shù)超過20萬的資深研究者,他是Christian Szegedy。Szegedy是吳宇懷在谷歌時(shí)的團(tuán)隊(duì)負(fù)責(zé)人,在谷歌工作了13年,有兩篇論文引用數(shù)超過5萬,另有多篇超過1萬,文章的方向都指向AI的本質(zhì)性算法研究。Szegedy是波恩大學(xué)應(yīng)用數(shù)學(xué)博士。
Igor Babuschkin和Toby Pohlen共同參與了DeepMind著名的AI項(xiàng)目AlphaStar,AlphaStar從50萬局「星際爭霸 2」游戲中學(xué)習(xí),隨后自己玩了1.2億局來精進(jìn)技術(shù)。最終,它達(dá)到了最高的宗師段位,水平超越了99.8%玩家。
Grok-1模型能力僅次于GPT-4,在推理和數(shù)學(xué)能力上優(yōu)化
xAI在11月初發(fā)布了他們的第一個(gè)基礎(chǔ)大語言模型Grok-1(約330億參數(shù)),這個(gè)模型是在它們的原型大模型Grok-0的基礎(chǔ)上經(jīng)過微調(diào)和RLHF完成。他的訓(xùn)練數(shù)據(jù)截至2023年第三季度,輸出上下文長度為8k。
據(jù)稱,Grok-0只使用了一半的訓(xùn)練資源,就達(dá)到了接近llama 2 70B的能力,之后又在推理和編碼能力進(jìn)行了針對(duì)性的優(yōu)化。
在xAI官方公布的測(cè)試中,我們可以評(píng)估Grok-1的能力。在這個(gè)評(píng)測(cè)中,主要包括:
1.GSM8k:中學(xué)數(shù)學(xué)文字問題,使用思維鏈提示。
2.MMLU:多學(xué)科選擇題,考驗(yàn)綜合理解能力。
3.HumanEval:Python代碼完成任務(wù),考驗(yàn)編碼能力。
4.MATH:中學(xué)和高中數(shù)學(xué)問題,用LaTeX編寫,考驗(yàn)更高階的數(shù)學(xué)能力。
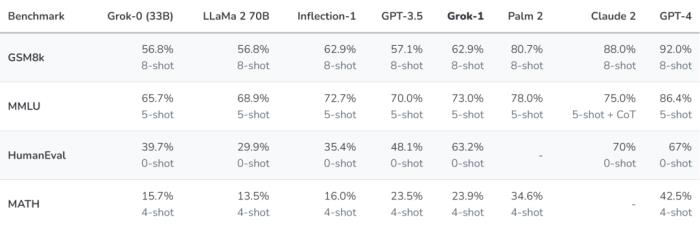
從圖表中可以看出,Grok-1在幾乎所有的測(cè)試中都領(lǐng)先llama 2 70B和GPT-3.5,在HumanEval和Math這兩個(gè)測(cè)試中更是大幅領(lǐng)先llama 2 70B。但是它與Claude2和GPT-4仍然存在可見的差距。
不過鑒于Grok-1的模型規(guī)模應(yīng)該只有33B,而且訓(xùn)練資源上只花費(fèi)了llama 2 70B的一半,我們可以說它在效率方面有突出表現(xiàn)。未來若推出參數(shù)規(guī)模更大的版本,能力還有提升的空間。
由于以上的測(cè)試都比較主流,為了摒除刻意優(yōu)化的因素,xAI測(cè)試了Grok與主要競爭對(duì)手在2023年匈牙利國家高中數(shù)學(xué)期末考試上的實(shí)際表現(xiàn),這更貼近真實(shí)場景,為表公平,xAI沒有為這次評(píng)估做特別的調(diào)整。

實(shí)驗(yàn)結(jié)果顯示,Grok以C級(jí)(59%)通過了考試,而Claude-2也獲得了相同的成績(55%),GPT-4則以B級(jí)(68%)通過。
除了大模型,xAI還公布了PromptIDE,這是一個(gè)集成的開發(fā)環(huán)境,專為提示工程和可解釋性研究而設(shè)計(jì)。PromptIDE的目的是為了讓工程師和研究人員能夠透明地訪問Grok-1。這個(gè)IDE旨在賦予用戶能力,幫助他們快速探索LLM的能力。
在11月初剛發(fā)布大模型時(shí),Grok-1只對(duì)有限的用戶開放,在本周xAI計(jì)劃將Grok的能力向X Premium+訂閱者們開放,xAI也為Grok提供了搜索工具和實(shí)時(shí)信息的訪問權(quán)限,這一點(diǎn)相較于其他模型具有差異化優(yōu)勢(shì)。
它還提供專用的“趣味”模式、多任務(wù)處理、可分享的聊天和對(duì)話反饋。趣味模式將是所有功能中最有趣的,因?yàn)樗x予Grok獨(dú)特的個(gè)性,使其能夠以帶有諷刺和幽默的方式進(jìn)行更吸引人的對(duì)話。
大模型的競爭格局會(huì)變么?能力將往何處發(fā)展?
在ChatGPT發(fā)布正好一年的這一天,看起來OpenAI的模型能力和生態(tài)產(chǎn)品建設(shè)在各個(gè)大模型廠商中仍舊是明顯領(lǐng)先的。能夠與它競爭的公司Anthropic,Inflection,包括xAI都還處于追趕態(tài)勢(shì)。谷歌,亞馬遜等大廠也仍然落后。
基礎(chǔ)大模型廠商之間的競爭,是全方位的競爭,而且鑒于AI模型預(yù)訓(xùn)練需要的高成本,當(dāng)未來模型版本迭代時(shí),又需要持續(xù)投入巨大的算力和資金成本。除此之外,找到能夠充分釋放模型能力價(jià)值的場景也非常重要,不然無法形成反饋的循環(huán)。
目前來看,xAI不缺人才,也不缺算力和資金,此外因?yàn)閄(推特)的存在,它也不愁在前期找不到應(yīng)用場景。盡管Grok-1現(xiàn)在的絕對(duì)能力與GPT-4仍然有差距,但是當(dāng)后續(xù)它有更大規(guī)模參數(shù)的版本出現(xiàn)后,將會(huì)大大縮小與OpenAI的距離。
大模型的競爭是大廠與超級(jí)獨(dú)角獸的競爭,但是正因?yàn)橛羞@些公司在競爭和迭代,做應(yīng)用的公司和終端的用戶才會(huì)有越來越強(qiáng),越來越便宜的AI能力使用,最終所有行業(yè)都會(huì)被AI翻新一遍。
在大模型進(jìn)入公眾視野一年后,對(duì)于大模型的局限性我們有了更清楚的認(rèn)知,那就是推理能力和可靠性的不足。而在發(fā)展方向上,肯定是多模態(tài)。
xAI為了應(yīng)對(duì)這些問題,也做了定向研究,對(duì)于推理能力不足,他們研究可擴(kuò)展的工具輔助監(jiān)督學(xué)習(xí),讓AI和人類協(xié)同對(duì)AI模型進(jìn)行調(diào)優(yōu)。
對(duì)于AI的可靠性不足,他們研究形式驗(yàn)證,對(duì)抗性魯棒性等技術(shù),增強(qiáng)AI的可靠性。此外,盡管目前Grok因?yàn)閰?shù)量的原因在多模態(tài)能力上不如GPT-4等模型,但是xAI也在積極研究這個(gè)方向,未來會(huì)有具備視覺和音頻能力的模型。
相關(guān)推薦




- 免責(zé)聲明
- 本文所包含的觀點(diǎn)僅代表作者個(gè)人看法,不代表新火種的觀點(diǎn)。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對(duì)本文可能提及或鏈接的任何項(xiàng)目不表示認(rèn)可。 交易和投資涉及高風(fēng)險(xiǎn),讀者在采取與本文內(nèi)容相關(guān)的任何行動(dòng)之前,請(qǐng)務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨(dú)立判斷。新火種不對(duì)因依賴本文觀點(diǎn)而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
