

 新火種
2023-11-30
新火種
2023-11-30 


訓(xùn)練130億大模型僅3天,北大提出Chat-UniVi統(tǒng)一圖片和視頻理解
北京大學(xué)和中山大學(xué)等機(jī)構(gòu)研究者提出了統(tǒng)一的視覺語(yǔ)言大模型 ——Chat-UniVi。通過(guò)構(gòu)建圖片和視頻統(tǒng)一表征,該框架使得一個(gè) LLM 能夠在圖片和視頻的混合數(shù)據(jù)下訓(xùn)練,并同時(shí)完成圖片和視頻理解任務(wù)。更重要的是,該框架極大降低了視覺語(yǔ)言模型訓(xùn)練和推理的開銷,使得在三天以內(nèi)即可訓(xùn)練出具有 130 億參數(shù)的通用視覺語(yǔ)言大模型。Chat-UniVi 模型在圖片和視頻的下游任務(wù)中都取得了卓越的性能。所有代碼、數(shù)據(jù)集和模型權(quán)重均已開源。

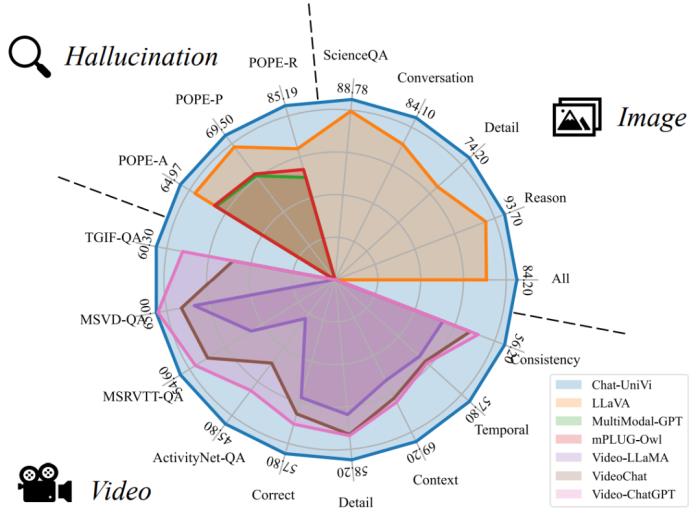
 在介紹本文方法之前,我們先看一下 Demo 展示:
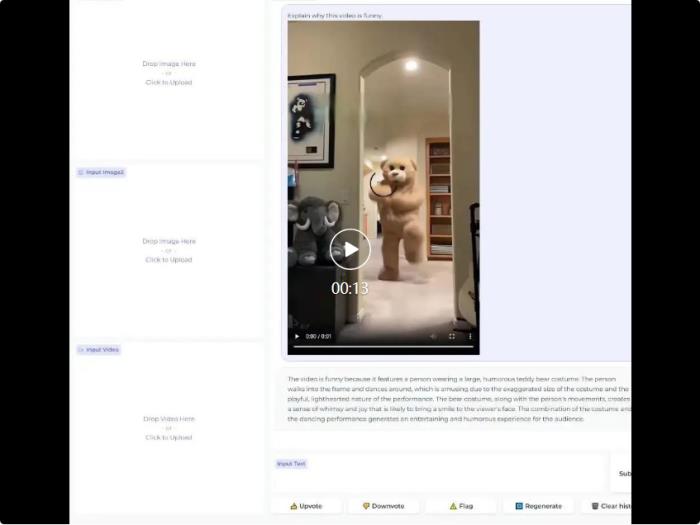
在介紹本文方法之前,我們先看一下 Demo 展示: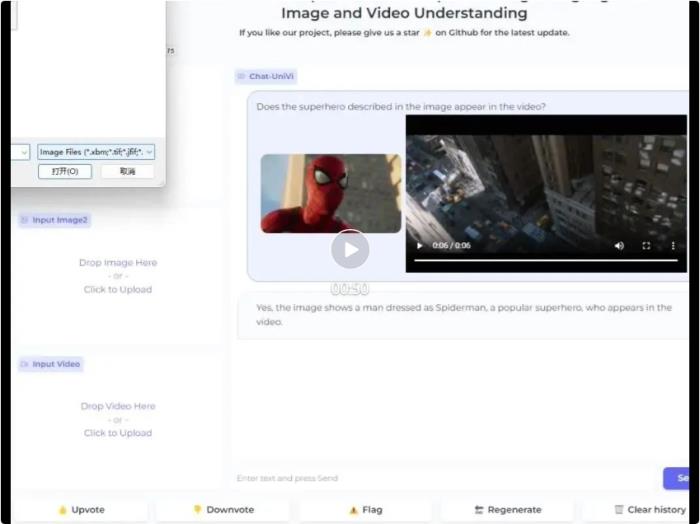
相關(guān)推薦




- 免責(zé)聲明
- 本文所包含的觀點(diǎn)僅代表作者個(gè)人看法,不代表新火種的觀點(diǎn)。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對(duì)本文可能提及或鏈接的任何項(xiàng)目不表示認(rèn)可。 交易和投資涉及高風(fēng)險(xiǎn),讀者在采取與本文內(nèi)容相關(guān)的任何行動(dòng)之前,請(qǐng)務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨(dú)立判斷。新火種不對(duì)因依賴本文觀點(diǎn)而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
