

 新火種
2023-11-27
新火種
2023-11-27 


MIT科學(xué)家DimitriP.Bertsekas最新《強(qiáng)化學(xué)習(xí)與最優(yōu)控制》課程
來源:專知
【新智元導(dǎo)讀】MIT科學(xué)家Dimitri P. Bertsekas在ASU開設(shè)了2022《強(qiáng)化學(xué)習(xí)》課程,講述了強(qiáng)化學(xué)習(xí)一系列主題。Dimitri 的專著《強(qiáng)化學(xué)習(xí)與最優(yōu)控制》,是一本探討人工智能與最優(yōu)控制的共同邊界的著作。本課程將聚焦于強(qiáng)化學(xué)習(xí)(RL),這是人工智能目前非常活躍的一個(gè)分支領(lǐng)域,并將有選擇性地討論一些基于近似動(dòng)態(tài)規(guī)劃(DP)方法的算法主題。
逼近值和策略空間,近似策略迭代,推出(策略迭代的一種一次性形式),模型預(yù)測(cè)控制,多智能體方法,挑戰(zhàn)組合優(yōu)化問題的應(yīng)用,使用模擬和神經(jīng)網(wǎng)絡(luò)架構(gòu)的實(shí)現(xiàn),策略梯度方法,聚合,以及工程和人工智能應(yīng)用,比如AlphaZero和TD-Gammon程序的高調(diào)成功,這兩個(gè)程序分別會(huì)下國際象棋和西洋雙陸棋。

我們的主要目標(biāo)之一是為RL和近似DP提出和開發(fā)一個(gè)新的概念框架。
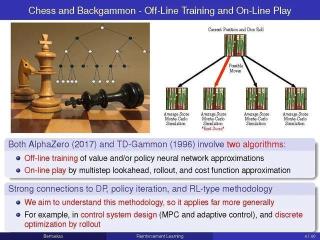
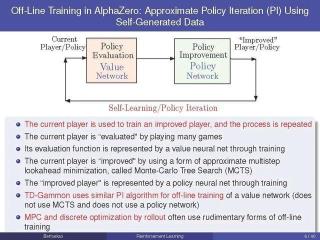
這個(gè)框架圍繞著兩種算法,它們?cè)诤艽蟪潭壬溪?dú)立設(shè)計(jì),并通過牛頓方法的強(qiáng)大機(jī)制協(xié)同運(yùn)行。我們稱之為離線訓(xùn)練和在線游戲算法;這些名字是借用了一些RL的主要成功游戲,如AlphaZero和TD-Gammon。
在這些程序的背景下,離線訓(xùn)練算法是用來教程序如何評(píng)估位置和在任何給定的位置產(chǎn)生好的移動(dòng)的方法,而在線比賽算法是用來實(shí)時(shí)對(duì)抗人或計(jì)算機(jī)對(duì)手的方法。
我們的主要目標(biāo)之一是,通過牛頓方法的算法思想和抽象DP的統(tǒng)一原則,表明AlphaZero和TD-Gammon方法的值空間逼近和鋪展非常廣泛地應(yīng)用于確定性和隨機(jī)最優(yōu)控制問題,包括離散和連續(xù)搜索空間,以及有限和無限視界。
此外,我們將展示我們的概念框架可以有效地與其他重要的方法集成,如模型預(yù)測(cè)和自適應(yīng)控制、多智能體系統(tǒng)和分散控制、離散和貝葉斯優(yōu)化,以及離散優(yōu)化的啟發(fā)式算法。本課程的主要重點(diǎn)是鼓勵(lì)研究生通過定向閱讀和與教師的互動(dòng)來加強(qiáng)學(xué)習(xí)。

作者Dimitri P. Bertsekas教授,1942年出生于希臘雅典,美國工程院院士,麻省理工大學(xué)電子工程及計(jì)算機(jī)科學(xué)教授。
Bertsekas教授因其在算法優(yōu)化與控制方面以及應(yīng)用概率論方面編寫了多達(dá)16本專著而聞名于世。他也是CiteSeer搜索引擎學(xué)術(shù)數(shù)據(jù)庫中被引用率最高的100位計(jì)算機(jī)科學(xué)作者之一。
Bertsekas教授還是Athena Scientific出版社的聯(lián)合創(chuàng)始人。
《強(qiáng)化學(xué)習(xí)與最優(yōu)控制》書籍

本書的目的是考慮大型和具有挑戰(zhàn)性的多階段決策問題,這些問題可以通過動(dòng)態(tài)規(guī)劃和最優(yōu)控制從原則上解決,但它們的精確解在計(jì)算上是難以解決的。
我們討論了依靠近似來產(chǎn)生性能良好的次優(yōu)策略(suboptimal policies)的求解方法。這些方法統(tǒng)稱為強(qiáng)化學(xué)習(xí)(reinforcement learning),也包括近似動(dòng)態(tài)規(guī)劃(approximate dynamic programming)和神經(jīng)動(dòng)態(tài)規(guī)劃( neuro-dynamic programming)等替代名稱。
我們的學(xué)科從最優(yōu)控制和人工智能的思想相互作用中獲益良多。本專著的目的之一是探索這兩個(gè)領(lǐng)域之間的共同邊界,并形成一個(gè)可以在任一領(lǐng)域具有背景的人員都可以訪問的橋梁。
這本書的數(shù)學(xué)風(fēng)格與作者的動(dòng)態(tài)規(guī)劃書和神經(jīng)動(dòng)態(tài)規(guī)劃專著略有不同。我們更多地依賴于直觀的解釋,而不是基于證據(jù)的洞察力。
在附錄中,我們還對(duì)有限和無限視野動(dòng)態(tài)規(guī)劃理論和一些基本的近似方法作了嚴(yán)格的簡要介紹。為此,我們需要一個(gè)適度的數(shù)學(xué)背景:微積分、初等概率和矩陣向量代數(shù)等。
實(shí)踐證明這本書中的方法是有效的,最近在國際象棋和圍棋中取得的驚人成就就是一個(gè)很好的證明。
然而,在廣泛的問題中,它們的性能可能不太可靠。這反映了該領(lǐng)域的技術(shù)現(xiàn)狀:沒有任何方法能夠保證對(duì)所有甚至大多數(shù)問題都有效,但有足夠的方法來嘗試某個(gè)具有挑戰(zhàn)性的問題,并有合理的機(jī)會(huì)使其中一個(gè)或多個(gè)問題最終獲得成功。
因此,我們的目標(biāo)是提供一系列基于合理原則的方法,并為其屬性提供直覺,即使這些屬性不包括可靠的性能保證。希望通過對(duì)這些方法及其變體的充分探索,讀者將能夠充分解決他/她自己的問題。

課程講義










Tags:
相關(guān)推薦




- 免責(zé)聲明
- 本文所包含的觀點(diǎn)僅代表作者個(gè)人看法,不代表新火種的觀點(diǎn)。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對(duì)本文可能提及或鏈接的任何項(xiàng)目不表示認(rèn)可。 交易和投資涉及高風(fēng)險(xiǎn),讀者在采取與本文內(nèi)容相關(guān)的任何行動(dòng)之前,請(qǐng)務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨(dú)立判斷。新火種不對(duì)因依賴本文觀點(diǎn)而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
