

 新火種
2023-11-23
新火種
2023-11-23 


PyTorch團隊重寫「分割一切」模型,比原始實現快8倍
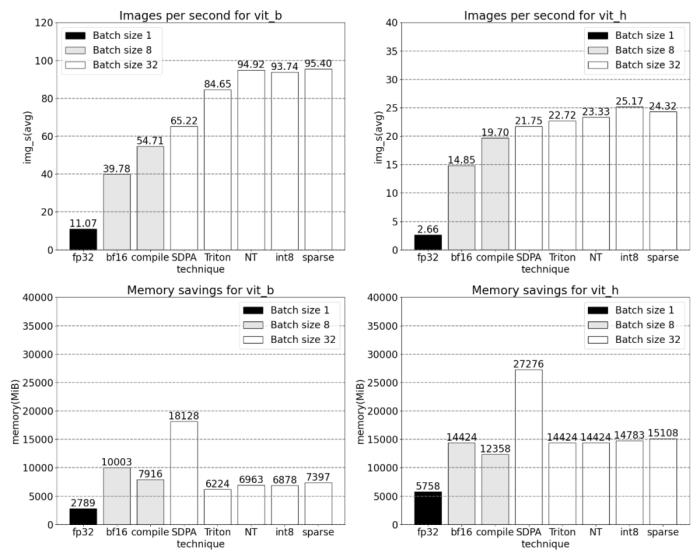
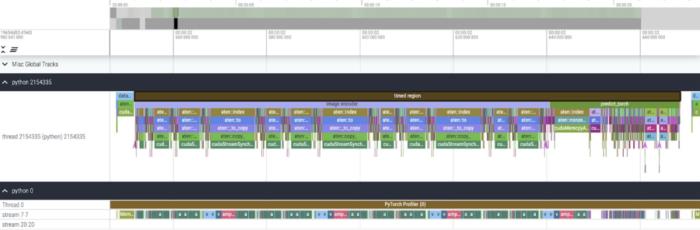
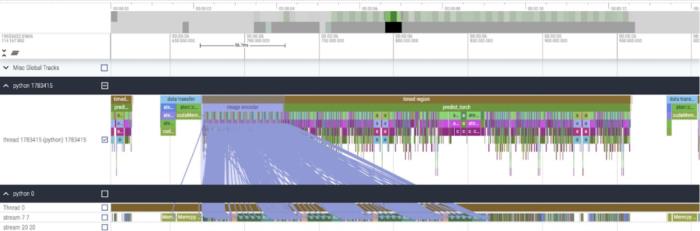
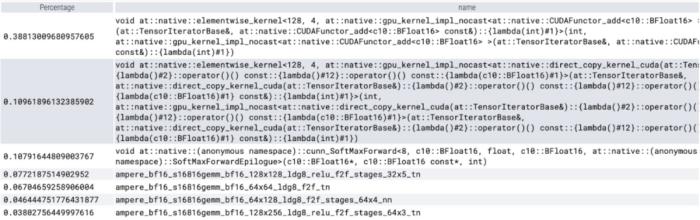
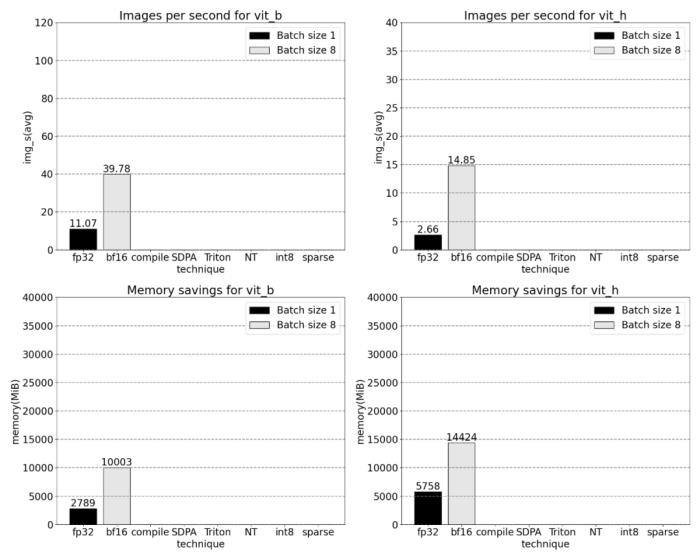
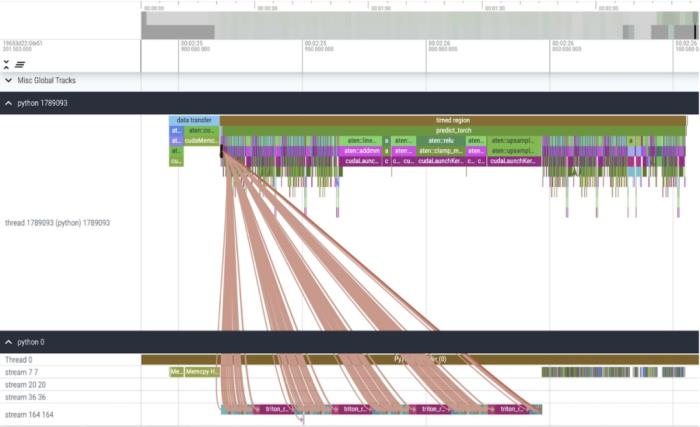
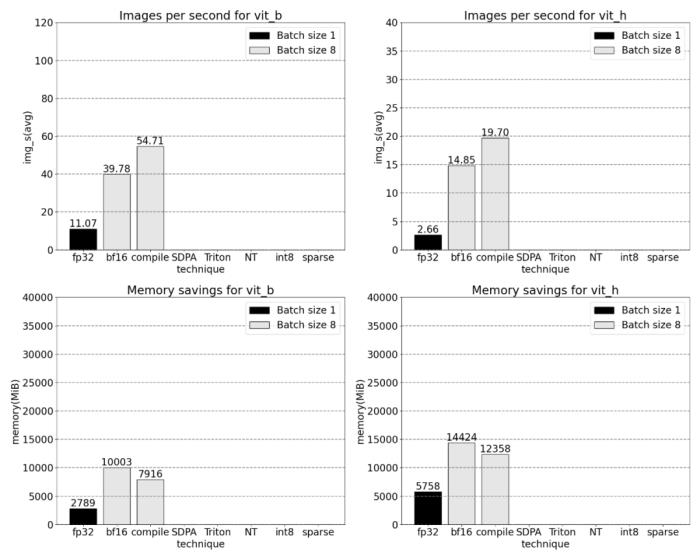
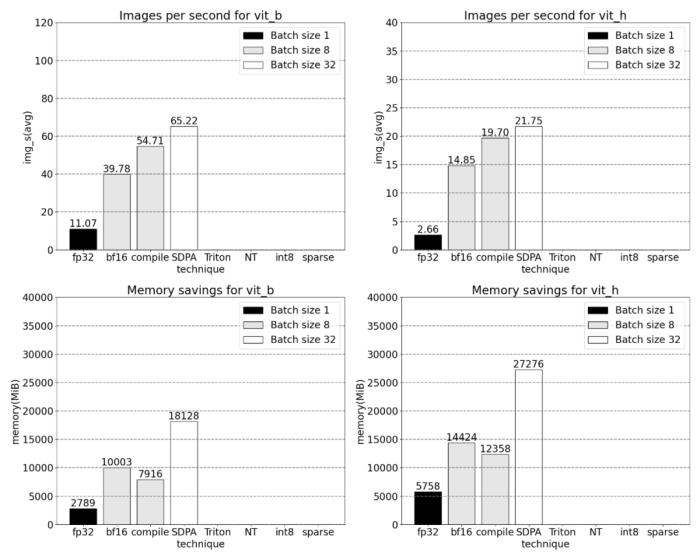
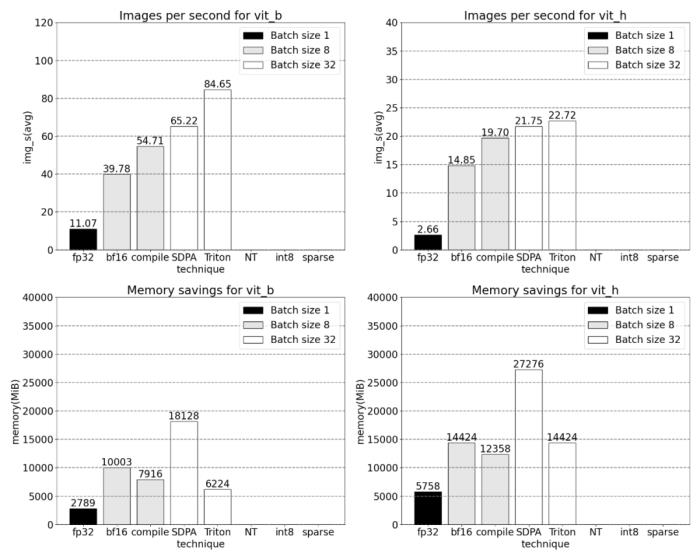
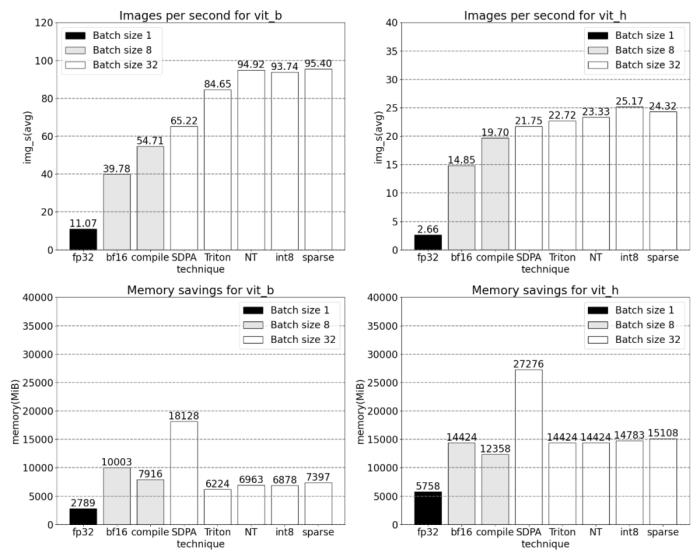
我們該如何優化 Meta 的「分割一切」模型,PyTorch 團隊撰寫的這篇博客由淺入深的幫你解答。從年初到現在,生成式 AI 發展迅猛。但很多時候,我們又不得不面臨一個難題:如何加快生成式 AI 的訓練、推理等,尤其是在使用 PyTorch 的情況下。本文 PyTorch 團隊的研究者為我們提供了一個解決方案。文章重點介紹了如何使用純原生 PyTorch 加速生成式 AI 模型,此外,文章還介紹了 PyTorch 新功能,以及如何組合這些功能的實際示例。結果如何呢?PyTorch 團隊表示,他們重寫了 Meta 的「分割一切」 (SAM) 模型,從而使代碼比原始實現快 8 倍,并且沒有損失準確率,所有這些都是使用原生 PyTorch 進行優化的。
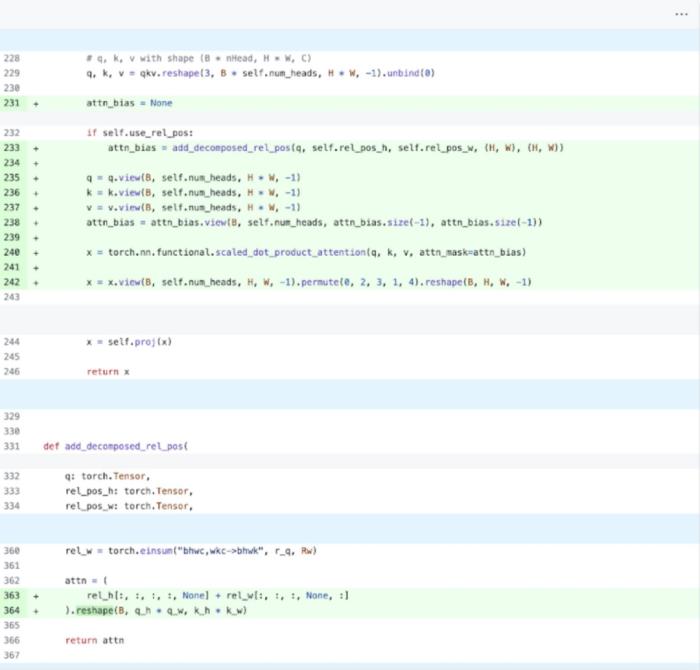
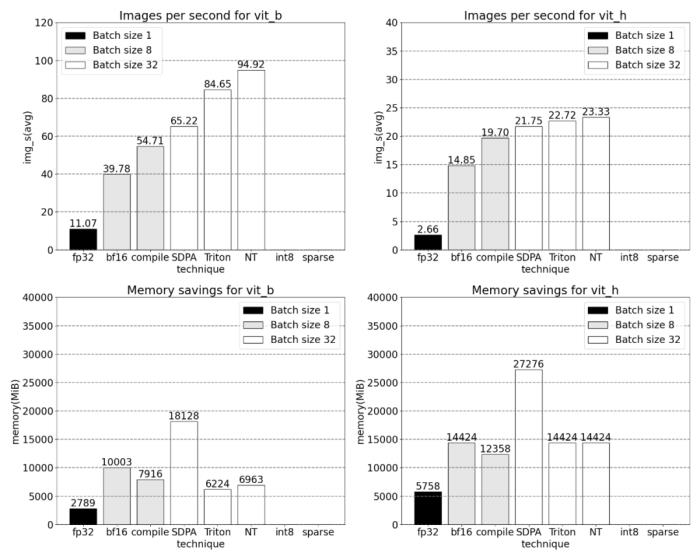
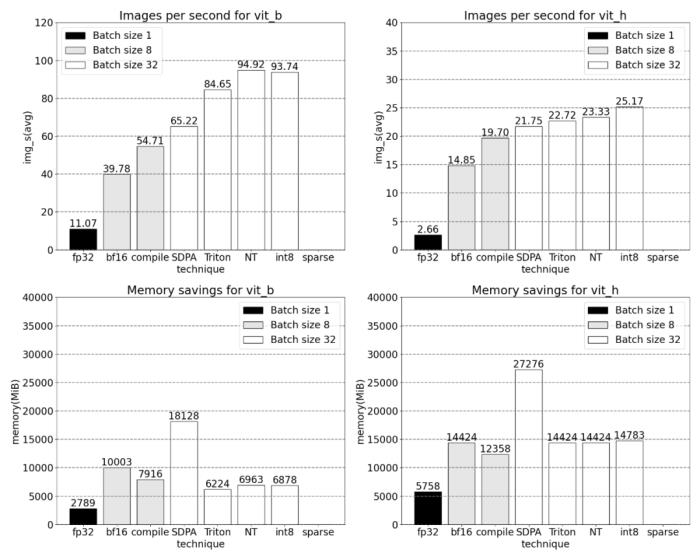
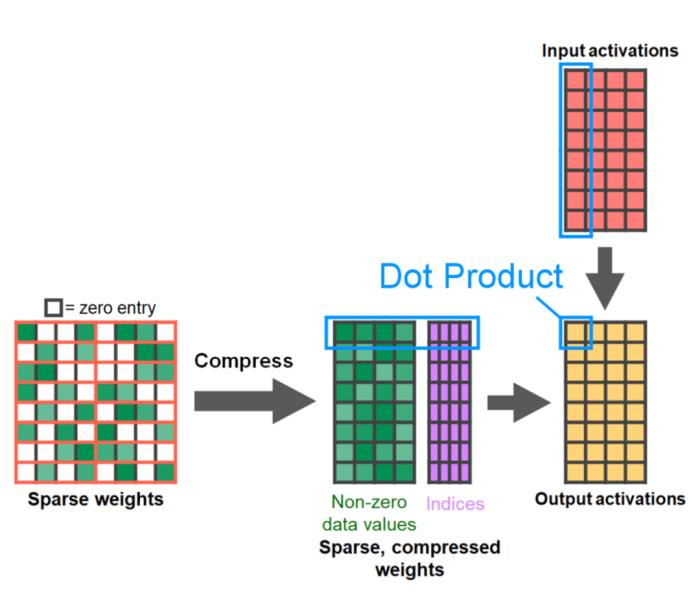
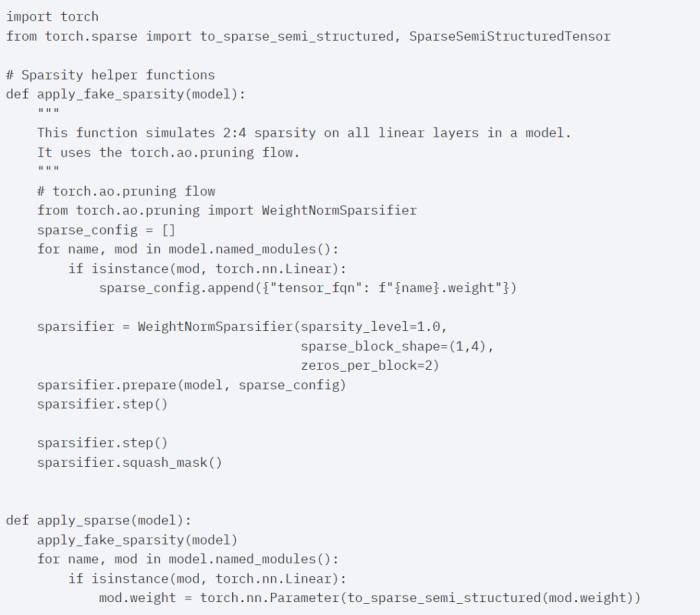
PyTorch 模型編譯器, PyTorch 2.0 加入了一個新的函數,叫做 torch.compile (),能夠通過一行代碼對已有的模型進行加速;GPU 量化:通過降低運算精度來加速模型;SDPA(Scaled Dot Product Attention ):內存高效的注意力實現方式;半結構化 (2:4) 稀疏性:一種針對 GPU 優化的稀疏內存格式;Nested Tensor:Nested Tensor 把 {tensor, mask} 打包在一起,將非均勻大小的數據批處理到單個張量中,例如不同大小的圖像;Triton 自定義操作:使用 Triton Python DSL 編寫 GPU 操作,并通過自定義操作符注冊輕松將其集成到 PyTorch 的各種組件中。
PyTorch 模型編譯器, PyTorch 2.0 加入了一個新的函數,叫做 torch.compile (),能夠通過一行代碼對已有的模型進行加速;GPU 量化:通過降低運算精度來加速模型;SDPA(Scaled Dot Product Attention ):內存高效的注意力實現方式;半結構化 (2:4) 稀疏性:一種針對 GPU 優化的稀疏內存格式;Nested Tensor:Nested Tensor 把 {tensor, mask} 打包在一起,將非均勻大小的數據批處理到單個張量中,例如不同大小的圖像;Triton 自定義操作:使用 Triton Python DSL 編寫 GPU 操作,并通過自定義操作符注冊輕松將其集成到 PyTorch 的各種組件中。






相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
