

 新火種
2023-11-22
新火種
2023-11-22 


【論文解讀】RLAIF基于人工智能反饋的強化學習
一、簡要介紹

人類反饋強化學習(RLHF)可以有效地將大型語言模型(LLM)與人類偏好對齊,但收集高質量的人類偏好標簽是一個關鍵瓶頸。論文進行了一場RLHF與來自人工智能反饋的RL的比較(RLAIF) 一種由現成的LLM代替人類標記偏好的技術,論文發現它們能帶來相似的改善。在總結任務中,人類評估者在70%的情況下更喜歡來自RLAIF和RLHF的生成,而不是基線監督微調模型。此外,當被要求對RLAIF和RLHF總結進行評分時,人們傾向于兩者評分相等。這些結果表明,RLAIF可以產生人類水平的性能,為RLHF的可擴展性限制提供了一個潛在的解決方案。
二、研究背景
從人類反饋中強化學習(RLHF)是一種使語言模型適應人類偏好的有效技術,并被認為是現代會話語言模型如ChatGPT和Bard成功的關鍵驅動力之一。通過強化學習(RL)的訓練,語言模型可以在復雜的序列級目標上進行優化,這些目標不易用傳統的監督微調進行區分。
對高質量的人類標簽的需求是擴大RLHF規模的一個障礙,一個很自然的問題是,人工生成的標簽能否達到類似的結果。一些研究表明,大型語言模型(LLM)表現出與人類判斷的高度一致——甚至在某些任務上優于人類。Bai等人(2022b)是第一個探索使用人工智能偏好來訓練一種用于RL微調的反饋模型——一種被稱為“來自人工智能反饋的強化學習”(RLAIF)的技術。雖然他們表明,將人類和人工智能偏好的混合結合“Constitutional AI”自我視覺技術優于監督的精細基線,但他們的工作并沒有直接比較人類和人工智能反饋的效率,RLAIF能否成為RLHF合適的替代品仍是一個保留問題。
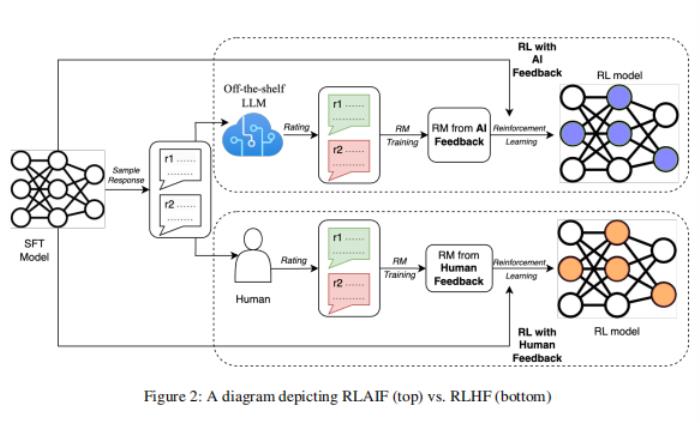
在這項工作中,論文直接比較了RLAIF和RLHF的總結任務。給定一個文本和兩個候選響應,論文使用現成的LLM分配一個偏好標簽。然后,論文訓練了一個關于LLM偏好的反饋模型(RM)。最后,論文使用強化學習來微調一個策略模型,使用RM來提供反饋。
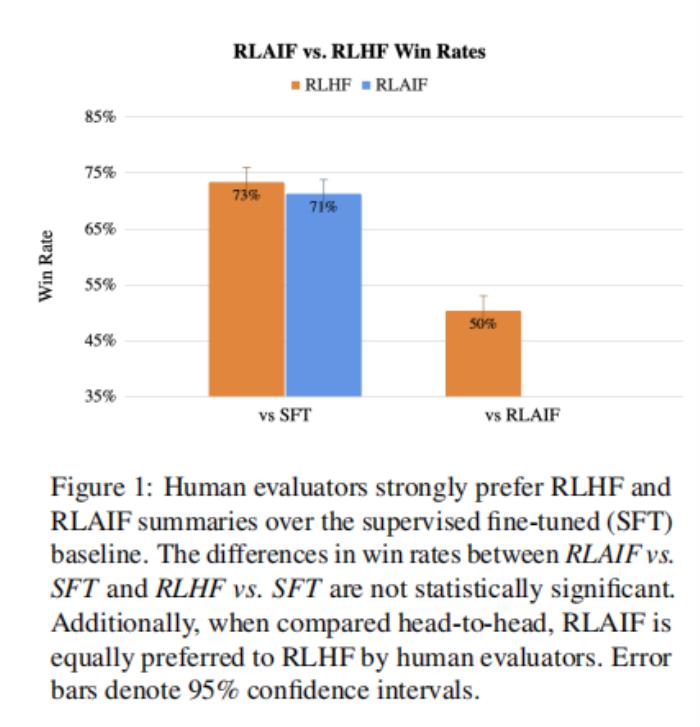
論文的結果表明,RLAIF達到了與RLHF相當的性能,以兩種方式測量。首先,論文觀察到,RLAIF和RLHF策略分別有71%和73%的時間比監督微調(SFT)基線更受到人類的青睞,但這兩種獲勝率在統計學上沒有顯著差異。第二,當被要求直接比較來自RLAIF和RLHF的生成時,人類對兩種方案同樣喜歡(即50%的win rate)。這些結果表明,RLAIF是RLHF可行的替代方案,不依賴人類注釋,提供吸引人的縮放屬性。
此外,論文還研究了最大限度地將人工智能產生的偏好與人類偏好對齊的技術。論文發現,用詳細的提示驅動論文的LLM和使用思維鏈推理可以改善對齊。令人驚訝的是,論文觀察到少量的情境學習和自洽性——在這個過程中,論文對多個思維鏈的基本原理進行抽樣并對最終偏好進行平均——都沒有提高準確性,甚至降低準確性。最后,論文進行了縮放實驗,以量化LLM標簽器的大小和在訓練中使用的偏好示例的數量與與人類偏好對齊之間的權衡。
論文的主要貢獻如下:
1.論文證明了RLAIF在總結任務上取得了與RLHF相當的性能
2.論文比較了各種生成人工智能標簽的技術,并為RLAIF從業者確定最佳設置
三、準備工作(Preliminaries)
論文首先回顧了現有工作引入的RLHF pipeline,包括3個階段:監督微調、反饋模型訓練和基于強化學習的微調。
監督微調(Supervised Fine-tuning)

反饋建模(Reward Modeling)

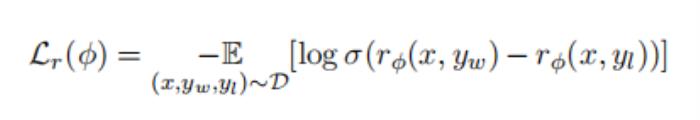
其中σ是sigmoid函數。
強化學習(Reinforcement Learning)

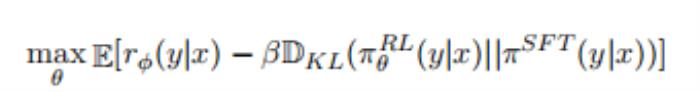
四、RLAIF方法(RLAIF Methodology)
在本節中,論文將描述用于使用LLM生成首選項標簽的技術、論文如何執行RL,以及評估度量。
4.1 LLM的首選項標簽(Preference Labeling with LLMs)
論文用一個“現成的”LLM對候選對象之間的反饋偏好,這個LLM是一個預先訓練或指令調整的模型,但沒有針對特定的下游任務進行微調。給定一篇文本和兩個候選摘要,LLM被要求評價哪個摘要更好。LLM的輸入結構如下(示例見表1):

1. Preamble-介紹和描述手頭任務的說明
2.Few-shot exemplars(可選)-一個文本的例子,一對摘要,一個思維鏈推理(如果適用),和一個偏好判斷
3.Sample to annotate-被標記的一個文本和一對摘要
4.Ending-用來提示LLM的結束字符串(例如:“Preferred Summary=”)
在給出LLM的輸入后,論文得到生成令牌“1”和“2”的對數概率,并計算softmax來推導出偏好分布。從LLM中獲得偏好標簽有很多選擇,比如從模型中解碼自由響應并啟發式地提取偏好(例如output = "The first summary is better"),或者將偏好分布表示為一個熱表示。然而,論文沒有嘗試這些替代方案,因為論文的方法已經產生了很高的準確性。
尋址位置偏差(Addressing Position Bias)
候選向LLM展示的順序可能會影響它更喜歡的候選。論文發現了存在這種位置偏差的證據,特別是對于較小尺寸的LLM標簽器(見附錄a)。
為了減少偏好標記中的位置偏差,論文對每一對候選者進行兩個推斷,其中候選者呈現給LLM的順序是相反的。然后將這兩種推斷的結果取平均值,得到最終的偏好分布。
思維鏈推理(Chain-of-thought Reasoning)
論文實驗從人工智能標簽用戶中引出思維鏈(COT)推理,以改善與人類偏好的一致性。論文將標準提示符(即“Preferred Summary=”)的結尾替換為“ Consider the coherence, accuracy, coverage, and overall quality of each summary and explain which one is better. Rationale:”然后解碼來自LLM的響應。最后,論文將原始提示符、響應和原始結束字符串“首選摘要=”連接在一起,并按照第前文中的評分程序來獲得偏好分布。插圖如圖3所示。
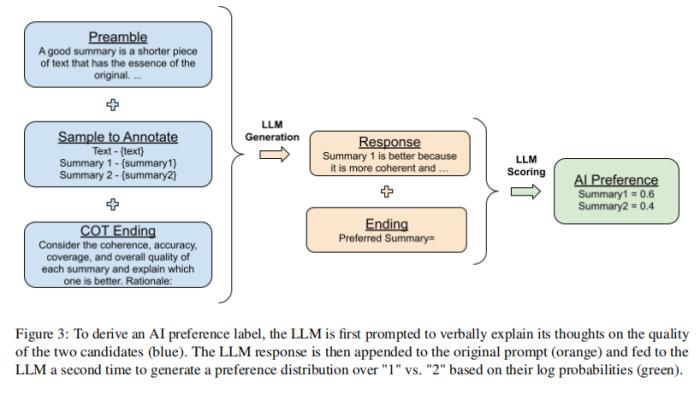
在zero-shot提示中,LLM沒有給出推理應該是什么樣的例子,而在few-shot提示中,論文提供了COT推理的例子。有關例子見表7和表8。


自洽性(Self-Consistency)
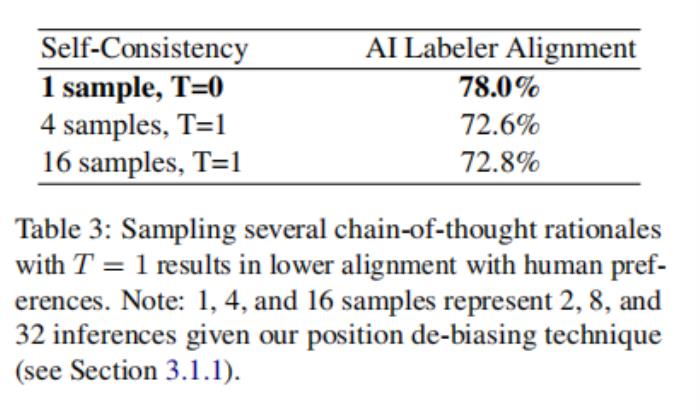
對于思維鏈提示,論文還進行了自洽性的實驗——這是一種通過抽樣多個推理路徑,并聚合每個路徑末端產生的最終答案來改進思維鏈推理的技術。在非零解碼下對多個思想鏈原理進行采樣,然后按照前文中的方法得到每個原理的LLM偏好分布。然后取結果的平均值,得到最終的偏好分布。
4.2從人工智能反饋中獲得的強化學習(Reinforcement Learning from AI Feedback)
在偏好被LLM標記出來之后,一個反饋模型(RM)就會被訓練來預測偏好。由于論文的方法產生了軟標簽(例如,preferencei= [0.6,0.4]),論文將交叉熵損失應用于RM產生的反饋分數的softmax,而不是前文中提到的損失。softmax將RM中的無界分數轉換為一個概率分布。
在人工智能標簽的數據集上訓練一個RM可以看作是模型蒸餾的一種形式,特別是因為論文的人工智能標簽器通常比論文的RM更大、更強大。另一種方法是繞過RM,在RL中直接使用AI反饋作為反饋信號,盡管這種方法計算上更昂貴,因為AI標簽比RM大。
使用經過訓練的RM,論文使用適應于語言建模領域的Advantage Actor Critic(A2C)算法進行強化學習(詳見附錄B)。雖然最近的許多工作使用近端策略優化(PPO)—一種類似的方法,增加了一些技術,使訓練更加保守和穩定(例如,裁剪目標函數),論文使用A2C,因為它更簡單,但仍然有效的解決論文的問題。
4.3 評估
論文用三個指標來評估論文的結果-人工智能標簽器對齊(Labeler Alignment),成對準確性(Pairwise Accuracy),和獲勝率(win rate)。
人工智能標簽對齊測量人工智能標記的偏好與人類偏好的準確性。對于一個單一的例子,它是通過將一個軟ai標記的偏好轉換為一個二進制表示(例如,preferencei= [0.6,0.4]→[1,0])來計算的,如果標簽與目標人類偏好一致,則分配一個1,否則為0。它可以這樣表示為:
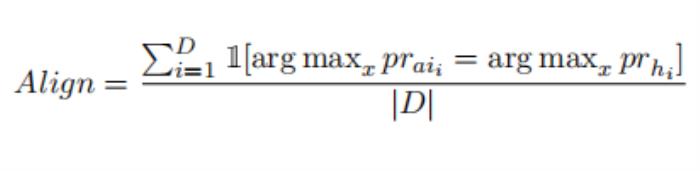

成對準確性衡量的是一個訓練過的反饋模型對一組人類偏好的準確性。給定一個共享的上下文和一對候選響應,根據人類標簽,如果RM對首選候選對象的得分高于非首選候選對象的得分,則成對準確性為1。否則,該值為0。這個量在多個例子上取平均值,以測量RM的總精度。
獲勝率Win Rate通過衡量一個策略被人類偏好高于另一個策略的頻率來評估兩個策略的端到端的質量。給定一個輸入和兩個生成,人類注釋者選擇偏好哪一個。策略A優于策略B的百分比稱為“Win Rate of A vs. B".
五、實驗細節(Experimental Details)
5.1數據集
根據Stiennon等人(2020年)的工作,論文使用了由OpenAI管理的過濾后的Reddit TL;DR數據集。TL;DR包含了來自Reddit的300萬篇關于不同主題的文章(也被稱為“subreddits”),以及原作者所寫的文章的摘要。此外,OpenAI還會對數據進行過濾,以確保高質量,其中包括使用一般人群可以理解的子紅數據白名單。此外,只使用摘要中包含24到48個令牌的帖子。過濾后的數據集包含123,169篇文章,其中5%作為驗證集保存。關于該數據集的更多細節可以在原始論文中找到。
此外,OpenAI從過濾后的TL;DR數據集中整理了一個人類偏好數據集。對于一個給定的帖子,從不同的策略中生成兩個候選人摘要,并要求標簽人員對他們更喜歡的摘要進行評級。總數據集包括92k的成對比較。
5.2 LLM標簽(LLM Labeling)
為了評估人工智能標記技術的有效性(例如,驅動、自洽性),論文從TL;DR偏好數據集中選擇了一些例子,其中人類注釋者更喜歡一個摘要而不是另一個摘要。論文在數據集訓練分割的隨機15%子集上評估人工智能標簽對齊,以實現更快的實驗迭代,產生2851個用于評估的例子。對于反饋模型訓練,TL;DR偏好數據集的完整訓練分割由LLM標記,并用于訓練——而不管置信度分數如何。
論文使用PaLM 2作為標記偏好的LLM。除非另有說明,論文使用最大上下文長度為4096個標記的大模型大小。對于思想鏈的生成,論文設置了最大解碼長度為512個標記,樣本溫度為T=0(即貪婪解碼)。對于自洽性實驗,論文使用溫度T = 1和top-K采樣,其中K=為40。
5.3模型訓練(Model Training)
論文在OpenAI過濾后的TL;DR數據集上訓練一個SFT模型,使用PaLM 2超小值(XS)作為論文的初始檢查點。
然后,論文從SFT模型中初始化論文的RMs,并在OpenAI的TL;DR人類偏好數據集上訓練它們。對于表1和前文的結果,論文使用PaLM 2 L生成ai標記的偏好,使用“OpenAI+COT0-shot”提示符,沒有自洽性,然后在完整的偏好數據集上訓練RM。
對于強化學習,論文使用附錄b中描述的A2C來訓練策略。策略模型和價值模型都是從SFT模型中初始化的。論文使用過濾后的Reddit TL;DR數據集作為初始狀態來推出論文的策略。
有關更多的訓練細節,請參見附錄C。
5.4人工評估
論文從人類中收集了1200個排名來評估RLHF和RLAIF的策略。對于每個評級任務,評估者都會看到一個帖子和4個總結,它們來自不同的策略(來自RLAIF、RLHF、SFT和人類參考),并被要求按照無聯系的質量對它們進行排序。文章來自于TL的保留集;DR監督微調數據集,這沒有在任何其他評估中使用。一旦收集到這些排名,就有可能計算出任何兩種策略的獲勝率。
六、結果
6.1 RLAIF vs. RLHF
論文的結果表明,RLAIF具有與RLHF類似的性能(見表1)。在71%的情況下,人類評估者首選RLAIF。相比之下,RLHF有73%的時間比SFT更可取。雖然RLHF略優于RLAIF,但差異沒有統計學意義4。論文還直接比較了RLAIF和RLAIF的勝率。RLHF,發現他們同樣受歡迎——即獲勝率是50%。為了更好地理解RLAIF與RLHF之間的比較情況,論文定性地比較了第6節中由兩種策略生成的摘要。
論文還比較了RLAIF和RLHF摘要與人類編寫的參考摘要。79%的情況下RLAIF摘要優于參考摘要,80%的情況下RLHF優于參考摘要。RLAIF和RLHF之間的勝率與參考摘要之間的差異也沒有統計學意義。
在論文的研究結果中,一個混雜的因素是,論文的RLAIF和RLHF策略往往比SFT策略產生更長的總結,這可以解釋一些質量改進。與Stiennon等人(2020年)類似,論文進行了事后分析,結果表明,盡管RLAIF和RLHF策略都受益于產生較長的總結,但在控制了長度后,兩者的表現仍優于SFT策略。
這些結果表明,RLAIF是一種不依賴于人類注釋的RLHF的可行替代方案。為了理解這些發現如何很好地推廣到其他自然語言處理任務,需要在更廣泛的任務上進行實驗,論文將其留給未來的工作。
6.2驅動技術(Prompting Techniques)
論文實驗了三種類型的驅動技術——序言特異性、思維鏈推理和few-shot的上下文學習——并在表2中報告了結果。
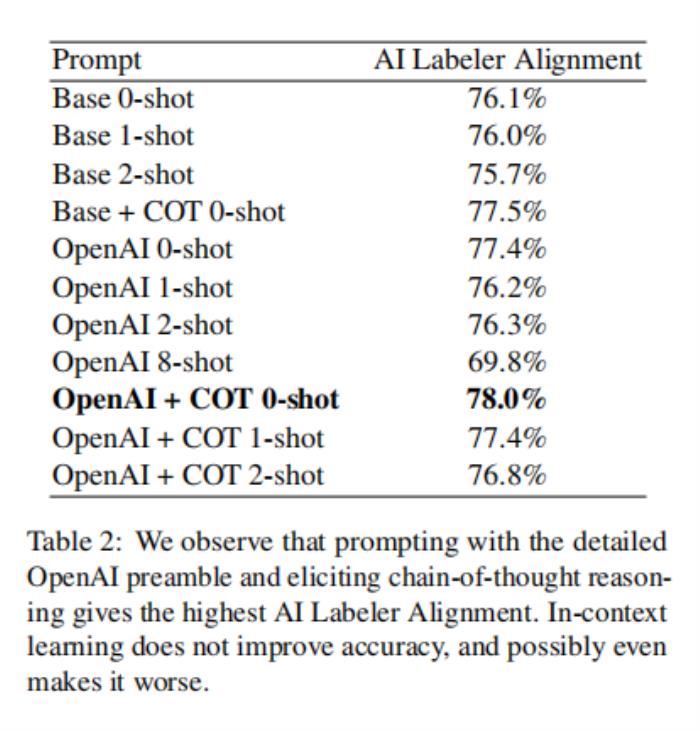
總的來說,論文觀察到最優配置使用了詳細的前導、思維鏈推理,而沒有上下文學習(“OpenAI+COT 0-shot”)。這個組合實現了78.0%的AI標簽對齊,比使用論文最基本的提示(“Base 0-shot”)高出1.9%。作為比較點,Stiennon等人(2020)估計,在人類偏好數據集上,人類注釋者之間的一致性為73-77%,這表明論文的LLM表現得相當好。論文對所有其他實驗使用“OpenAI+COT 0-shot”提示。
6.3自洽性(Self-Consistency)
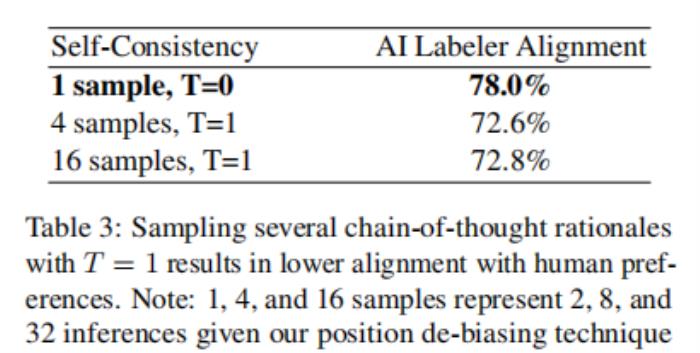
論文使用4個和16個樣本進行自洽性實驗,解碼溫度為1,如前文中描述的那樣,兩種設置都顯示自洽性下降大于5%。手動檢查鏈狀思維原理并沒有揭示為什么自洽性可能導致較低的準確性的任何共同模式(見表10中的例子)。
關于精度下降的一個假設是,與貪婪解碼相比,使用溫度為1會導致模型產生更低質量的思維鏈基本原理,最終導致整體精度下降。使用溫度在0到1之間的溫度可能會產生更好的結果。

6.4 LLM標簽的大小(Size of LLM Labeler)
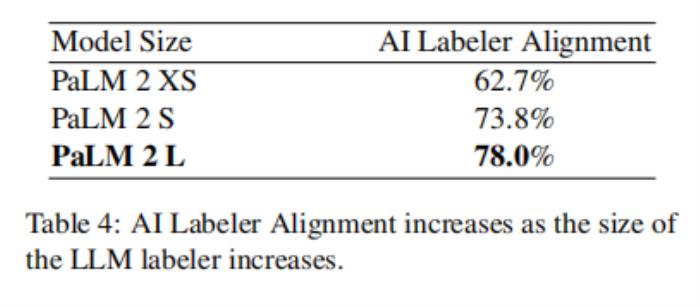
大尺寸的模型不能廣泛使用,運行起來可能緩慢和昂貴。論文實驗了不同模型大小的標記偏好,并觀察到對齊和大小之間的強關系。從PaLM 2 Large (L)到PaLM 2 Small (S)時,排列下降-4.2%,下降到PaLM 2 XS時,又下降-11.1%。這一趨勢與在其他工作中觀察到的標度律相一致(Kaplan等人,2020年)。導致性能下降的一個因素可能是在較小的LLM中,位置偏差的增加(見附錄A)。
在這一趨勢的最后,這些結果也表明,擴大人工智能標簽器的大小可能會產生更高質量的偏好標簽。由于AI標簽器只用于生成一次偏好示例,而在RL訓練中不會被查詢,因此使用更大的AI標簽器并不一定非常昂貴。此外,前文指出,少量的例子可能足以訓練一個強大的RM(例如,在O(1k)的順序上),進一步降低了使用一個更大的標記器模型的成本。
6.6 偏好示例數(Number of Preference Examples)
為了理解RM的準確性如何隨著訓練示例的數量而變化,論文對不同數量的人工智能標記偏好示例RM進行訓練,并對人類偏好的剔除集合評估成對的準確性。論文通過對全偏好數據集進行隨機子抽樣,獲得了不同數量的訓練示例。結果如圖5所示。
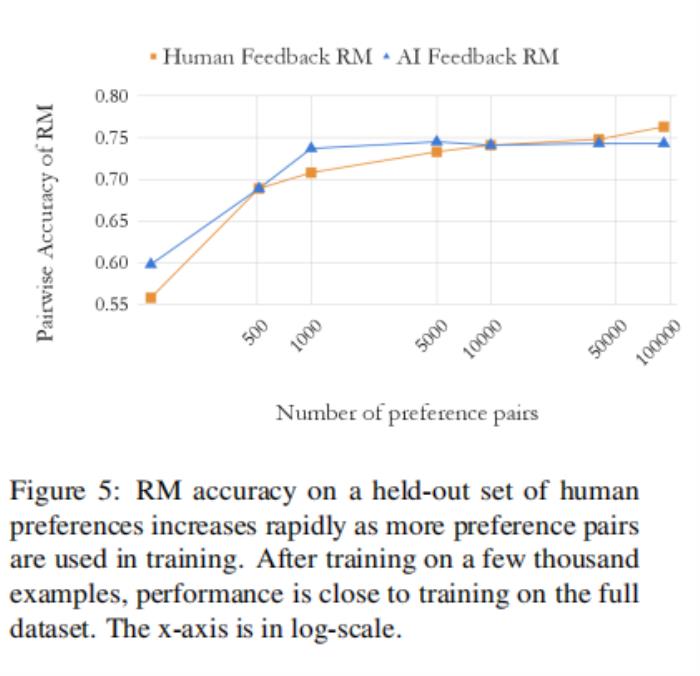
論文觀察到,經過幾千個例子的訓練后,AI偏好RM的表現很快趨于穩定。此RM在僅進行128個例子訓練時達到60%的精度,然后在只有5000個例子(大約1/20個完整數據集)訓練時達到接近于對完整數據集訓練的精度。
論文還在一個訓練了人類偏好的RM上進行了一組平行的實驗。論文發現人類和人工智能的RM遵循相似的比例曲線。一個不同之處在于,隨著訓練例子數量的增加,人類的偏好RM似乎在不斷提高,盡管更多的訓練例子只會給準確性帶來很小的提高。這一趨勢表明,根據人工智能偏好訓練的rm可能不會像根據人類偏好訓練的rm那樣受益那么多。
考慮到擴大人工智能偏好示例數量的有限改進,更多的資源可能會更好地花在標記具有更大的模型尺寸上,而不是標記更多的偏好示例。
七、定性分析
為了更好地理解RLAIF與RLHF的比較情況,論文手動檢查了由兩種策略生成的摘要。在許多情況下,這兩個策略產生了類似的總結,這反映在它們相似的獲勝率上。論文確定了兩種它們完全不同的模式。
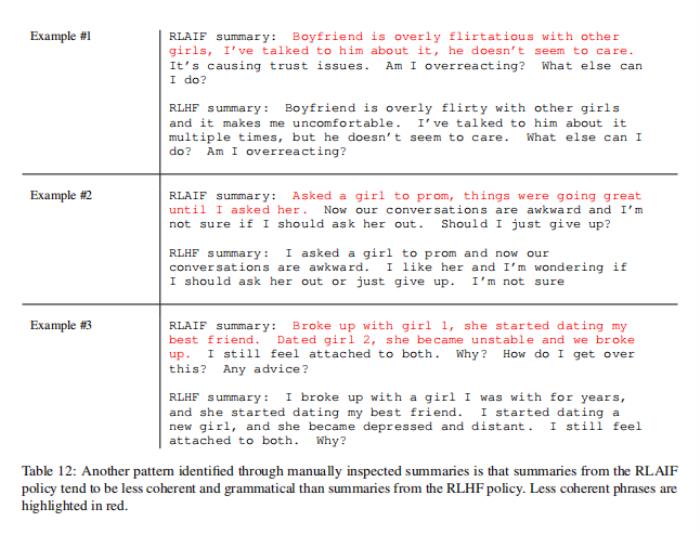
論文觀察到的一種模式是,RLAIF似乎比RLHF更不容易產生虛構。RLHF中的虛構通常是可信的,但與原文不一致。例如,在表11的示例#1中,RLHF摘要聲明作者是20歲,但原始文本中沒有提到或暗示這一點。

論文觀察到的另一種模式是,RLAIF有時在產生連貫或符合語法總結上不如RLHF。例如,在表12的示例#1中,RLAIF摘要生成不符合語法語句。
總的來說,雖然論文觀察到每項策略的某些趨勢,但兩者都產生了相對相似的高質量摘要。
八、結論

在這項工作中,論文展示了RLAIF可以在不依賴人類注釋者的情況下產生類似于RLHF的改進。論文的實驗表明,RLAIF在SFT基線上大大改善,改善的幅度與RLHF相當。在頭對頭的比較中,人類對RLAIF和RLHF的比例相似。論文還研究了各種人工智能標記技術,并進行了縮放研究,以了解生成對齊偏好的最佳設置。
雖然這項工作強調了RLAIF的潛力,但論文注意到這些發現的一些局限性。首先,這項工作只探索了總結的任務,留下了一個關于對其他任務的泛化性的開放問題。其次,論文沒有估計LLM推斷在金錢成本方面是否比人工標記更有利。此外,仍有許多有趣的開放問題,如RLHF結合RLAIF可以超越單一方法,如何使用LLM直接分配反饋執行,改進人工智能標簽調整是否意味著改善最終策略,以及是否使用LLM標簽相同大小的策略模型可以進一步提高策略(即模型是否可以“自我完善”)。論文把這些問題留給以后的工作吧。
作者希望本文能激發人們在RLAIF領域的進一步研究。
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
