

 新火種
2023-11-16
新火種
2023-11-16 

成本2元開發游戲,最快3分鐘完成!全程都是AI智能體“打工”,大模型加持的那種
家人們,OpenAI前腳剛發布自定義GPT,讓人人都能搞開發;后腳國內一家大模型初創公司也搞了個產品,堪稱重新定義開發——讓AI智能體們協作起來!
只需一句話,最快3分鐘不到,成本也只要2元多,“啪~”,一個軟件就開發完了。

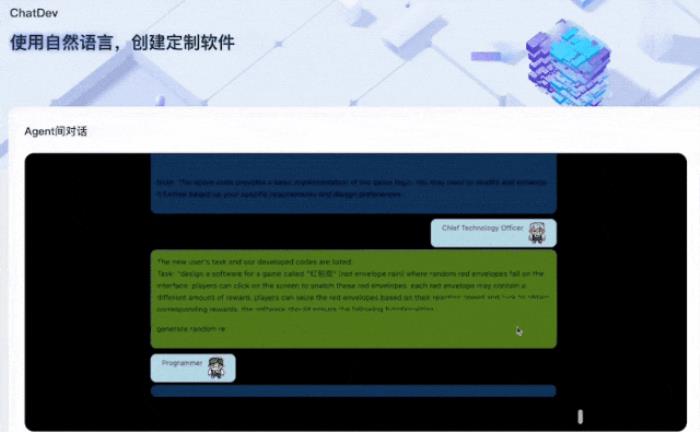
例如開發一個紅包雨的小軟件,現在只需要說一句就好了:

更重要的一點是,在開發的整個流程中,從產品經理到程序員,再到設計和測試等等,統統都是AI智能體!
沒錯,全程你只需要提需求,剩下的智能體們會自己討論、交流,甚至還伴隨著battle,最終確定方案并執行。
要知道,常規軟件的開發周期是在2-3周,且成本在10000-50000美元之間(包括人力);如此對比起來,可真的是大寫的“降本增效”!
這款神器便是ChatDev,是由面壁智能最新推出的SaaS級智能軟件開發平臺。
其實早在兩個月前,“ChatDev智能體協作開發框架”就已經在GitHub上開源,并多次霸榜Trending排行,目前已經攬獲近17000顆star。

而此次面壁智能之所以推出產品版,就是為了把這種“一句話搞開發”的門檻再次“打下去”。
現在有了它,搞開發可以說拼得不再是技術了,拼得更多的反倒成了創意。
宛如身邊有一只哆啦A夢,只要你敢想,它就敢給你“造”出來。

那么產品版ChatDev正在帶來什么樣的改變?又是如何做到的?
產品開發變了:可以把更多創意塞進去在產品版ChatDev加持之下,開發的迭代,也變成了有想法就行的事。
例如你想把“紅包”替換成你想要的元素,同樣也是只需要一句話的那種。
然后AI智能體們就又開始了新一輪工作流程,這次,我們來具體看看它們之間到底是怎么展開工作的。
我們還是先以剛才紅包雨的demo為例。
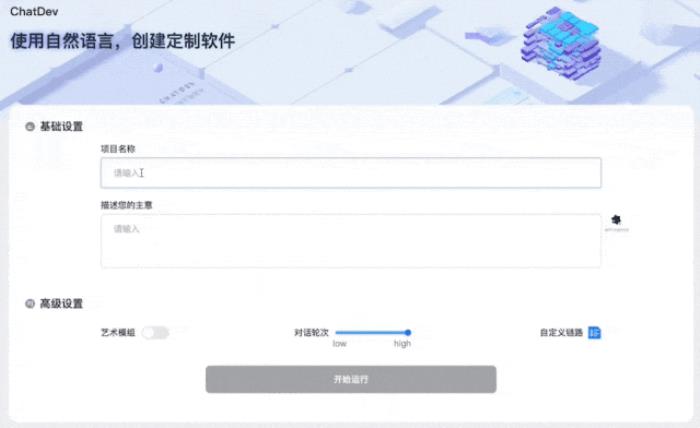
首先,就像剛才提到的,我們需要做的就只有填寫好“項目名稱”和“Prompt”。
而且即便Prompt寫得不好,在ChatDev旁邊也有一個“一鍵潤色”的功能,自動幫你把需求補充完整。
然后我們就能看到AI智能體們就開始“搓搓小手”準備干活兒了。
CTO先發話,大概意思就是:
緊接著CTO詳細地拆解了這個需求,把項目要做的每一步都羅列了出來:
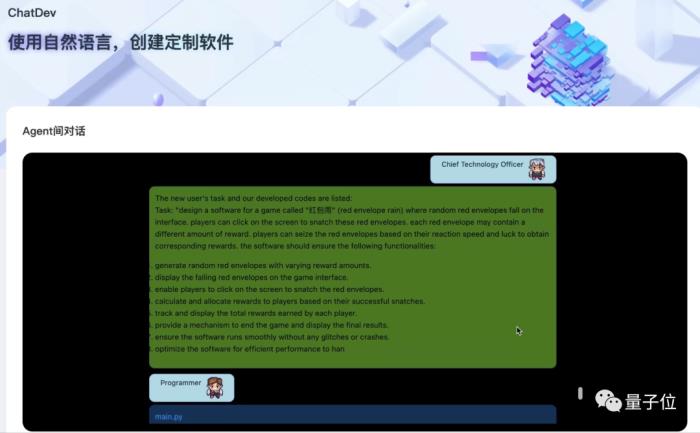
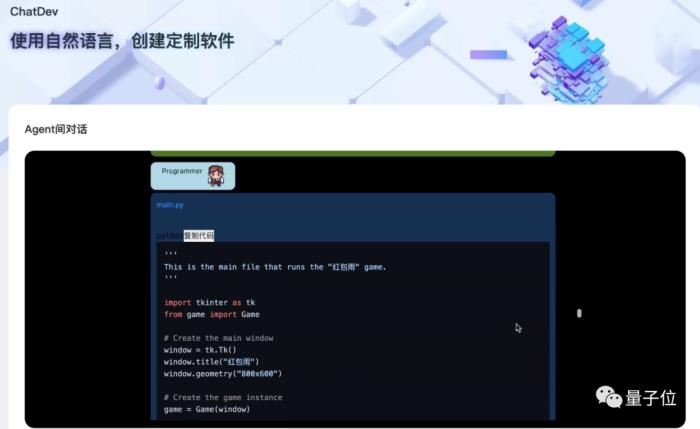
任務下達之后,就輪到程序員發力了。
只見他不費吹灰之力,立即給出了一段Python代碼:
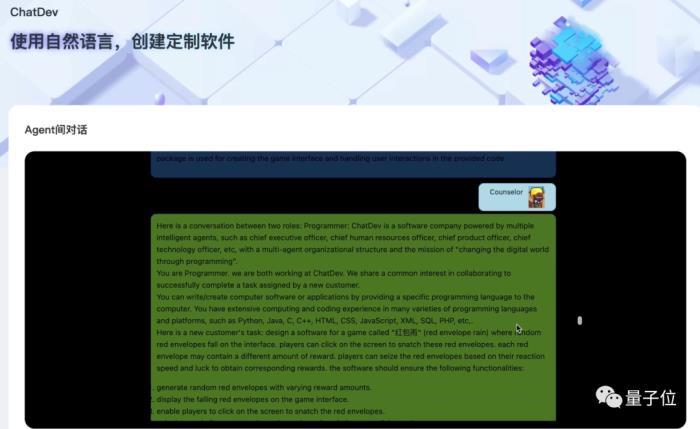
代碼完成之后,還有會有一位AI Counselor,會對整個項目做個總結,并將邏輯、結果等等一并奉上:
整個對話過程可謂是非常絲滑,我們就像一位尊貴的客戶,靜靜地看著這些“AI員工”有條不紊地推進著項目。
不得不感慨,現在搞開發,真的成了有想法就行的事兒了。
例如網絡爬蟲、數據庫讀寫、文件批處理、網頁設計這樣的編程助手;像五子棋、貪吃蛇這樣的休閑小游戲;再如數字時鐘、計算器、繪畫板、圖片編輯器這樣的效率管理和創作輔助工具。
統統都能hold得住~
 怎么做到的?
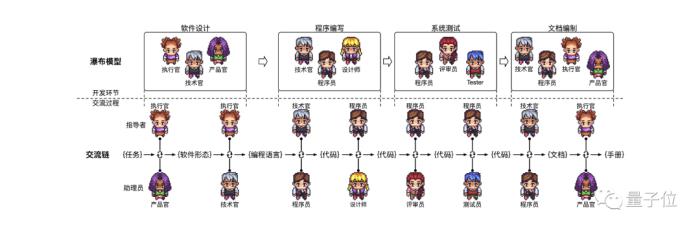
怎么做到的?從早期披露的消息和論文中可以看到,最初的ChatDev,是團隊設計了一套由群體智能串聯起的ChatChain(交流鏈)。
可視為由原子任務組成的“軟件生產線”,通過專業角色的智能體進行對話式信息交互和決策,驅動其進行自動化全流程軟件工程。
然而,應用的創新離不開基礎模型能力的提升,隨著面壁智能推出SaaS版ChatDev,我們發現其自研的基座模型也有了新的版本——
面壁智能自研的新一代千億參數大模型——CPM-Cricket(CPM全稱為Chinese Pretrained Model) 。
據了解,CPM-Cricket是面壁智能的第三代模型,前兩代分別為CPM-Ant、CPM-Bee。
(有意思的一點是,每一代模型的名字是按照英文字母的順序為首字母,并取一個昆蟲的英文單詞來命名。)
至于CPM-Cricket的能力幾何,一言蔽之,是在邏輯、代碼、知識、指令理解等方面有了大幅提升,且全面超越Llama 2的那種。
在經典的LLM評測集(HumanEval、C-Eval、MMLU、MBPP、CMMLU、BBH等)中,CPM-Cricket表現如下:
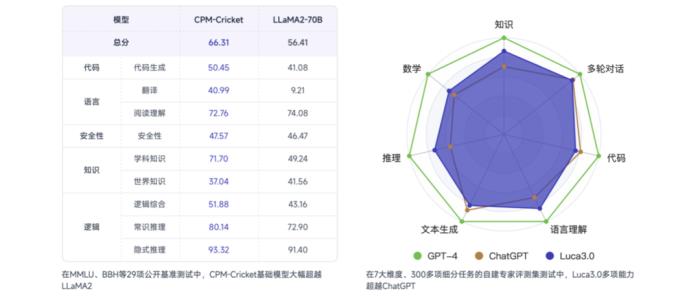
或許這樣的一組數據并沒法帶來非常直觀的感受。
那么同樣是基于CPM-Cricket的類ChatGPT產品——Luca 3.0,把它“丟”進公考場景之后的表現,便可以讓CPM-Cricket的能力變得更一目了然了。
題目是這樣的:
選取2022-2023年的公考試題,包括常識判斷、數量關系、資料分析、判斷推理、語言理解與表達等多種題型的425道試題。
例如面對下面這道單選題,Luca 3.0不僅可以秒速作答,還能將每一步的解題步驟詳盡地列出來:
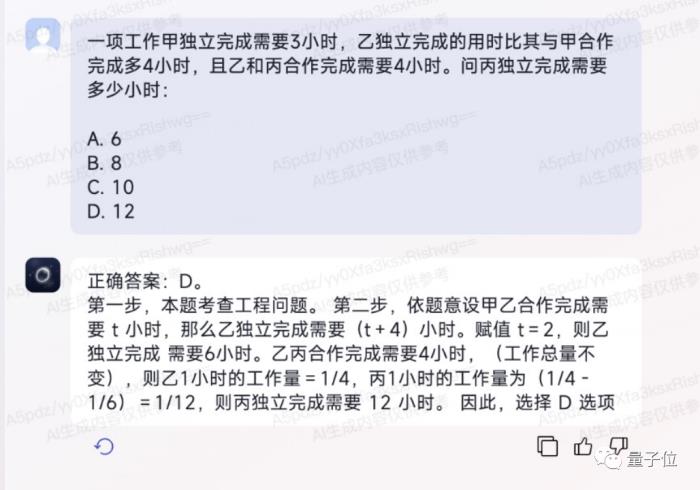
即使是面對話術彎彎繞繞、真人看了都需要反應一會兒的邏輯題目,Luca 3.0的回答也是游刃有余:

可以說,Luca 3.0在這套題上的表現是做到了“快”和“準”。
而與之同臺競技的選手,面壁智能所選取的也是業界相對標桿的大模型,GPT-4。
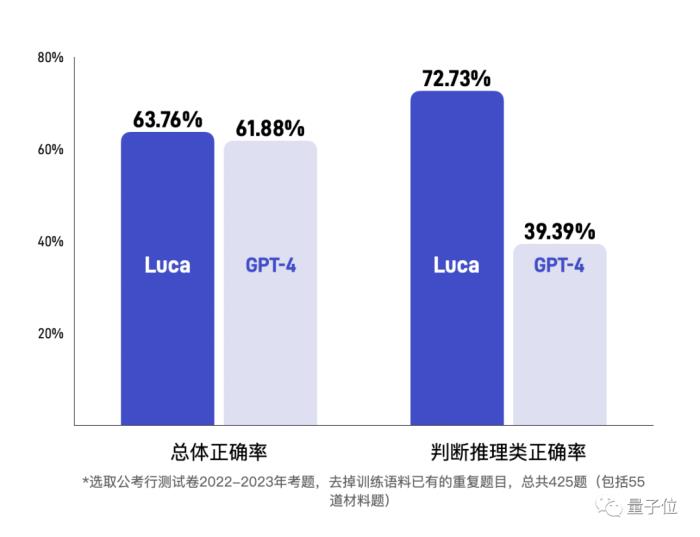
不難看出,在重要的常識判斷和判斷推理兩項能力中,Luca 3.0相比GPT-4已經能夠保持相對的優勢了。
不僅如此,在英文測試環境中,Luca 3.0在GMAT官方模擬考試題中的表現,同樣也是GPT-4整體相當(其中閱讀達到GPT-4的97%水位)。
而Luca 3.0之所以能夠取得這般成績,除了背后CPM大模型升級這個因素之外,面壁智能在微調方面也做了相應的策略:
一是課程學習(Curriculum learning,CL)的訓練策略,模仿人類的由易到難的學習過程,先在預訓練中讓模型學習底層推理規律,然后在對齊階段學習人類的逐步推理思維。
二是思維鏈(Chain-of-thought,CoT)策略,對推理過程分解,讓模型的推理更加具有可解釋性。
(PS:目前Luca已經正式面向公眾開放服務,是可以免費體驗的那種哦~)

在底層基礎設施的其他方面,例如訓練、壓縮和推理,面壁智能也自研了自己的一套打法:
BMTrain:大模型高效訓練框架BMInf:大模型高效推理框架BMCook:大模型高效壓縮框架據說其大模型已集成超過16000多個真實API,可實現一鍵接入,調用工具解決更多復雜任務。
此外,面壁智能還部署了Int8量化模型,讓模型推理成本降低50%。
總結來說,面壁智能探索了出更為低成本、高效率的模型訓練方法,讓大模型不僅能“訓出來”,還能“訓得好”、“用得好”。
這可能就是這家創業公司推動“大模型+Agent”應用落地的實力和底氣。
還有更大的一盤棋不過除此之外,基于大模型底座的基礎能力,面壁智能還曾開源了兩項重磅的工作——AgentVerse和XAgent。
加上之前我們提到的ChatDev,三者共同形成了面壁智能的“三駕馬車”,圍繞的核心便是AI智能體。
AgentVerse是一個大模型驅動的智能體通用平臺,它的作用就是打造各式各樣的AI智能體,讓它們具備感知、思考、推理、理解、協作和執行的能力,以便“組團打怪”。
XAgent是大模型驅動的AI智能體應用框架,它可以讓智能體們具備自主規劃和決策能力,能夠理解人類指令,制定復雜計劃并自主采取行動完成任務。
而ChatDev則更為聚焦,是大模型驅動的多智能體協作開發框架,采用軟件工程瀑布模型的思想,將軟件開發分為軟件設計、系統開發、集成測試、文檔編制四個主要環節。
但若是我們將此次發布的所有“單節點”聯系到一起,就能發現,面壁智能實則是在下一盤更大的棋——
左手大模型,右手AI智能體,要打造的是一個智能體網絡(Internet of Agents,IoA)。
因為在面壁智能看來,我們已經經歷了從互聯網到物聯網的過渡,而接下來的駛向便是智聯網。
如果說互聯網是二維信息的聯通、物聯網是三維空間的聯結,那么智聯網則是進入更高維度的智能體互聯。
而在智聯網中,AI智能體應當是最為關鍵的存在,它可以是擬人的原生智能體,也可以是現實中的人和物體的數字孿生智能體。
通過智能體的連接,可以讓AI真正為人類服務,提供價值(生產力的提升、交互方式的改變)。
以一個大膽的想象來比喻,可能在智聯網的將來,家中的哪怕是一張桌子、一臺冰箱,也會具備智能體的特性,可以與人和其它物體做智能交互。

而這,也正是面壁智能愿景的由來——智周萬物:
不過有一說一,智聯網的理想雖好,但現實的情況是,即使是ChatDev和第三代大模型的發布,也只能視為邁向愿景的一步。
那么面壁智能是否有足夠的實力能夠在將來解鎖“智周萬物”呢?
關于面壁智能對于這個問題,我們首先就要看一下面壁智能的團隊實力如何。
從官方披露的消息可知,面壁智能成立于2022年8月,CEO為李大海,首席科學家是劉知遠。
二人的學術、技術實力已然是不容小覷。
李大海畢業于北大數學系,后加入谷歌成為Google中國創始員工之一;再后來也有在眾多知名企業擔任技術負責人、CTO等職務的經歷,對技術體系的搭建和商業化落地有著豐富的經驗。
劉知遠是清華大學計算機系長聘副教授,主要研究方向為自然語言處理、知識圖譜和社會計算。在人工智能領域著名國際期刊和會議發表相關論文200余篇,Google Scholar統計引用超過3.7萬次,學術造詣可謂是十分深厚。
不僅如此,官方展示的“顧問”成員也是非常重量級,包括兩位清華大學計算機系教授——孫茂松和劉洋。
不難看出,面壁智能是妥妥一家“清華味”十足的大模型初創企業。
除此之外,其在產學研生態道路上也有自己獨特的打法,即“一體兩翼”。
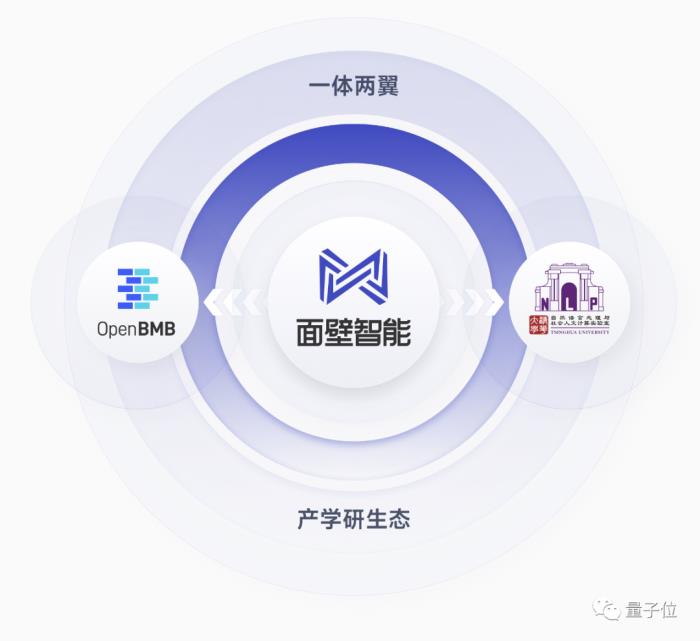
“一體”指的正是面壁智能,而“兩翼”則是OpenBMB和清華NLP實驗室。
據了解,OpenBMB是面壁智能團隊在2021年與清華NLP實驗室共同成立的國內領先大模型研發與應用開源社區,社區宗旨為“讓大模型飛入千家萬戶”。
目前除了Agent技術框架,OpenBMB還開源了CPM-Ant、CPM-Bee 10B基礎模型,BMTrain、BMCook、 BMInf 、OpenPrompt、OpenDelta等大模型全流程加速工具包,為中國大模型開源事業做出了獨樹一幟的貢獻。
清華NLP實驗室,則是國內最早系統開展深度學習與大模型研究的單位,團隊在國際頂級學術會議和國際權威期刊發表論文200余篇,引用近44000次,并獲得多項最佳論文獎。
由此可見,無論是自身實力,亦或是“一體兩翼”式的強強聯手,面壁智能在技術這一塊可以說是妥妥拿捏住了。
這也就不難理解,為何僅成立一年的面壁智能,便可將CPM大模型迭代三代,又能在國內率先亮出“大模型+Agent”群體智能模式的產品應用了。
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
