

 新火種
2023-11-14
新火種
2023-11-14 


破解自注意力推理缺陷的奧秘,螞蟻?zhàn)匝行乱淮鶷ransformer或?qū)崿F(xiàn)無損外推
隨著大語言模型的快速發(fā)展,其長度外推能力(length extrapolating)正日益受到研究者的關(guān)注。盡管這在 Transformer 誕生之初,被視為天然具備的能力,但隨著相關(guān)研究的深入,現(xiàn)實(shí)遠(yuǎn)非如此。傳統(tǒng)的 Transformer 架構(gòu)在訓(xùn)練長度之外無一例外表現(xiàn)出糟糕的推理性能。研究人員逐漸意識到這一缺陷可能與位置編碼(position encoding)有關(guān),由此展開了絕對位置編碼到相對位置編碼的過渡,并產(chǎn)生了一系列相關(guān)的優(yōu)化工作,其中較為代表性的,例如:旋轉(zhuǎn)位置編碼(RoPE)(Su et al., 2021)、Alibi (Press et al., 2021)、Xpos (Sun et al., 2022) 等,以及近期 meta 研發(fā)的位置插值(PI)(Chen et al., 2023),reddit 網(wǎng)友給出的 NTK-aware Scaled RoPE (bloc97, 2023),都在試圖讓模型真正具備理想中的外推能力。然而,當(dāng)研究人員全力將目光放在位置編碼這一眾矢之的上時(shí),卻忽視了 Transformer 中另一個(gè)重量級角色 --self-attention 本身。螞蟻人工智能團(tuán)隊(duì)最新研究表明,這一被忽視的角色,極有可能成為扭轉(zhuǎn)局勢的關(guān)鍵。Transformer 糟糕的外推性能,除了位置編碼外,self-attention 本身仍有諸多未解之謎。基于此發(fā)現(xiàn),螞蟻人工智能團(tuán)隊(duì)自研了新一代注意力機(jī)制,在實(shí)現(xiàn)長度外推的同時(shí),模型在具體任務(wù)上的表現(xiàn)同樣出色。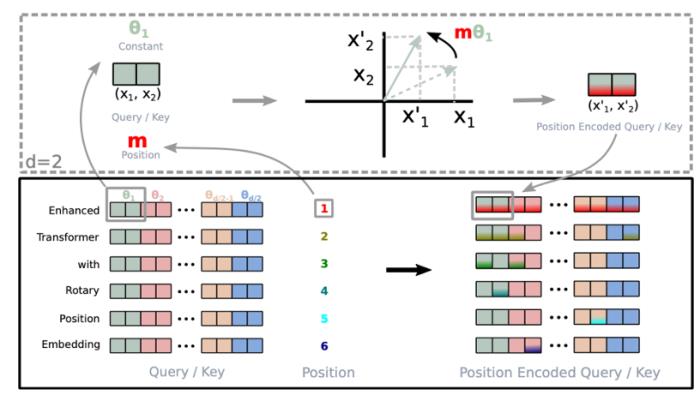
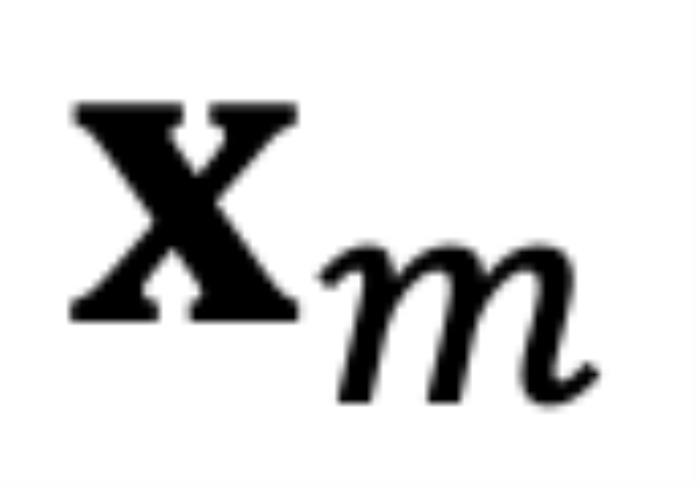 和
和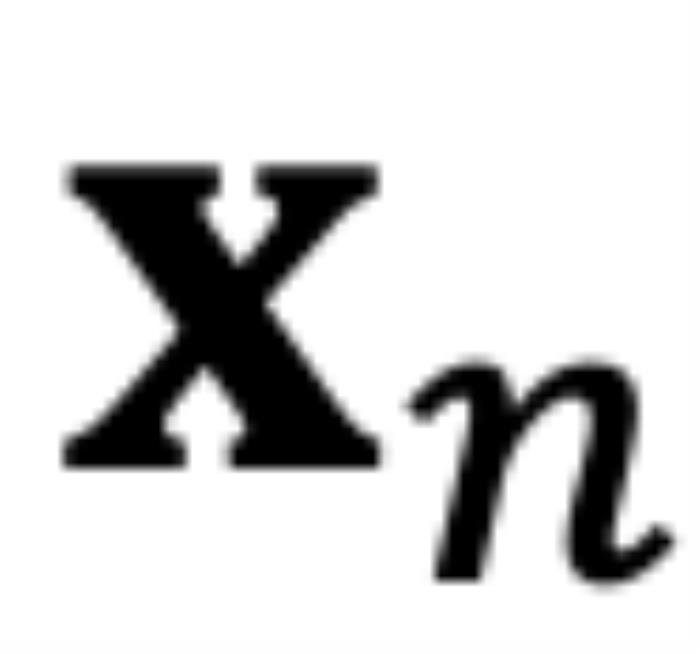 ,分別代表輸入序列中的m個(gè)和第n個(gè)位置索引對應(yīng)的 token,其 query 和 key 分別為
,分別代表輸入序列中的m個(gè)和第n個(gè)位置索引對應(yīng)的 token,其 query 和 key 分別為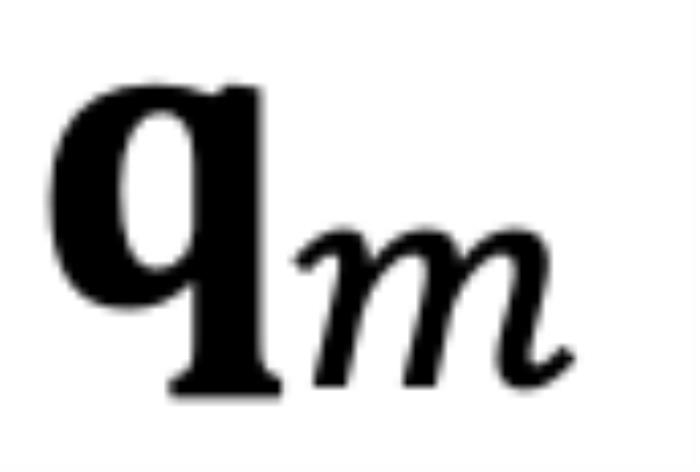 和
和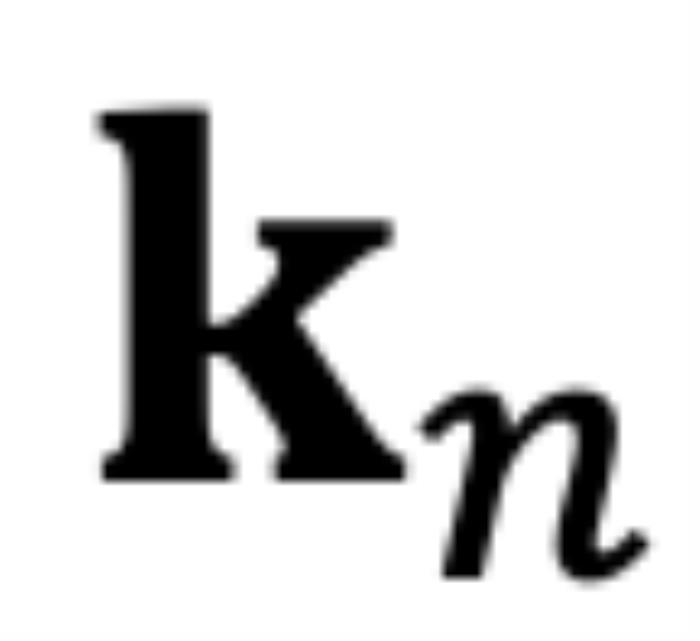 。它們之間的注意力可以表示為一個(gè)函數(shù)
。它們之間的注意力可以表示為一個(gè)函數(shù)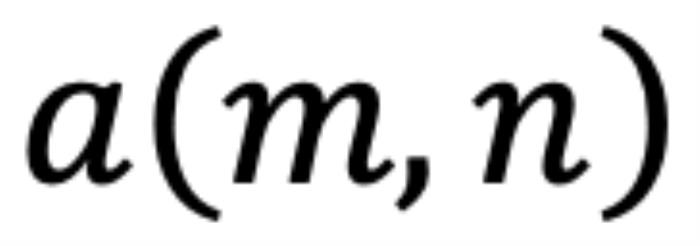 ,如果應(yīng)用 RoPE,則可以進(jìn)一步簡化為僅依賴于m和n相對位置的函數(shù)
,如果應(yīng)用 RoPE,則可以進(jìn)一步簡化為僅依賴于m和n相對位置的函數(shù)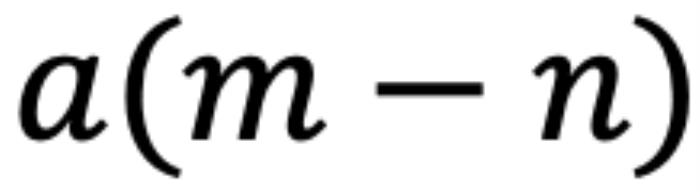 。從數(shù)學(xué)角度看,
。從數(shù)學(xué)角度看,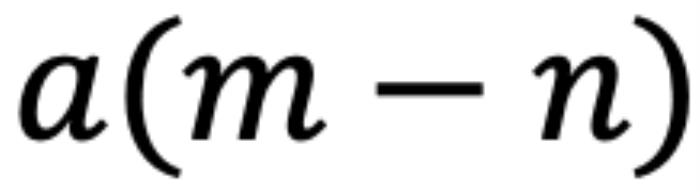 可以解釋為
可以解釋為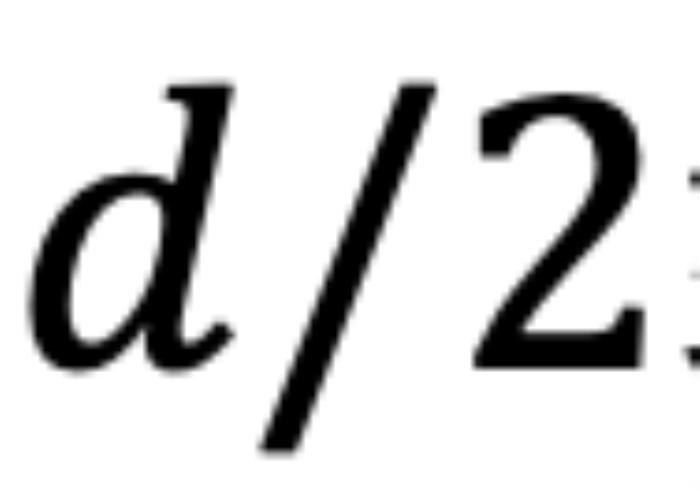 組復(fù)數(shù)(
組復(fù)數(shù)(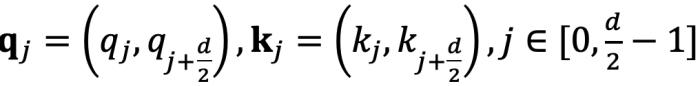 ,其中d為 hidden dimension 維度,省略位置索引m,n)經(jīng)過旋轉(zhuǎn)后的內(nèi)積之和。這在直覺上是有意義的,因?yàn)槲恢镁嚯x可以建模為一種序,并且兩個(gè)復(fù)數(shù)的內(nèi)積隨著旋轉(zhuǎn)角度
,其中d為 hidden dimension 維度,省略位置索引m,n)經(jīng)過旋轉(zhuǎn)后的內(nèi)積之和。這在直覺上是有意義的,因?yàn)槲恢镁嚯x可以建模為一種序,并且兩個(gè)復(fù)數(shù)的內(nèi)積隨著旋轉(zhuǎn)角度 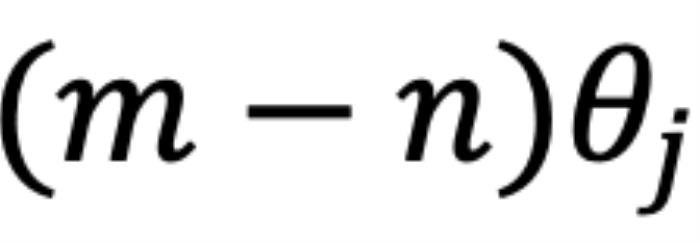 的變化而變化,以圖 5 為例,其中
的變化而變化,以圖 5 為例,其中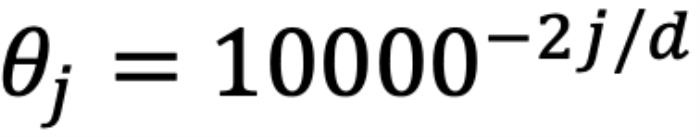 ,
,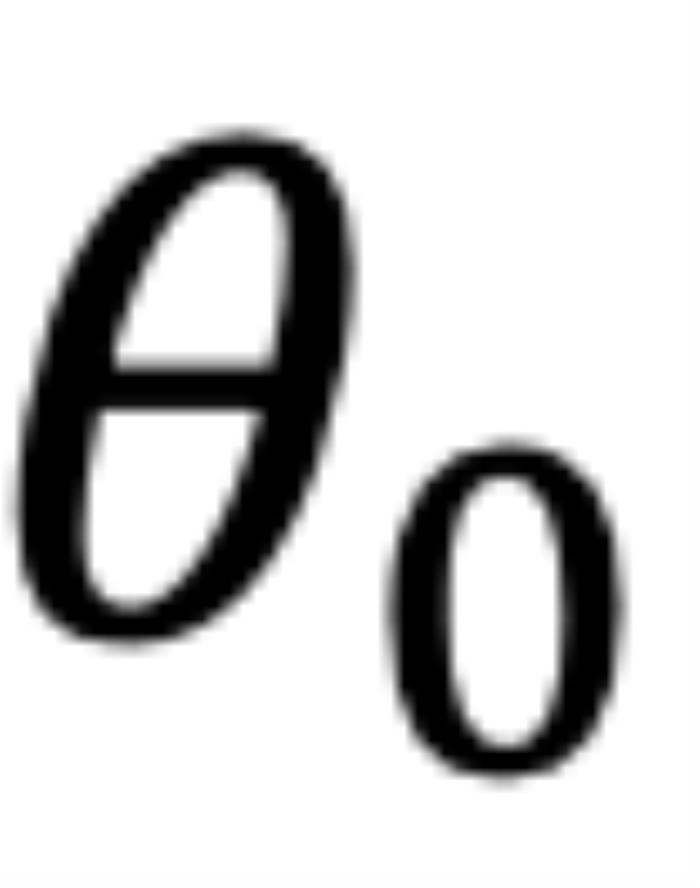 為
為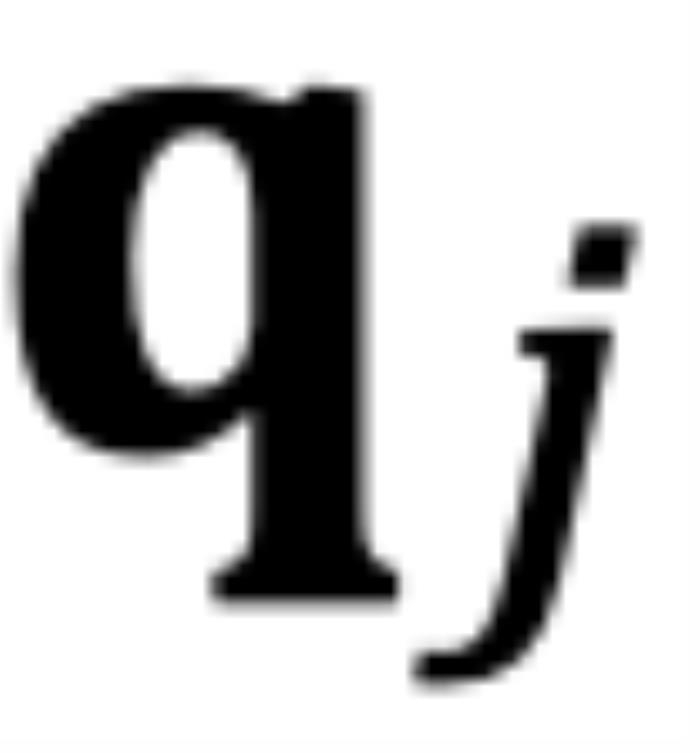 和
和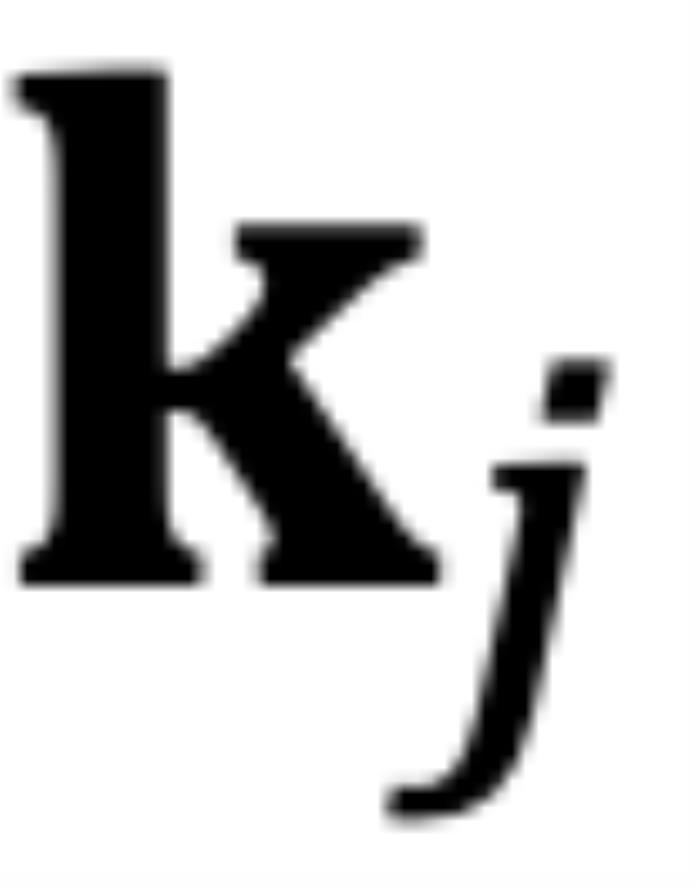 的初始夾角。然而,它隱藏著一個(gè)此前一直被忽略的技術(shù)缺陷。為了便于理解,我們首先考慮雙向注意力模型,例如 Bert (Devlin et al., 2019) 和 GLM (Du et al., 2021) 等。如圖 5 所示,對于
的初始夾角。然而,它隱藏著一個(gè)此前一直被忽略的技術(shù)缺陷。為了便于理解,我們首先考慮雙向注意力模型,例如 Bert (Devlin et al., 2019) 和 GLM (Du et al., 2021) 等。如圖 5 所示,對于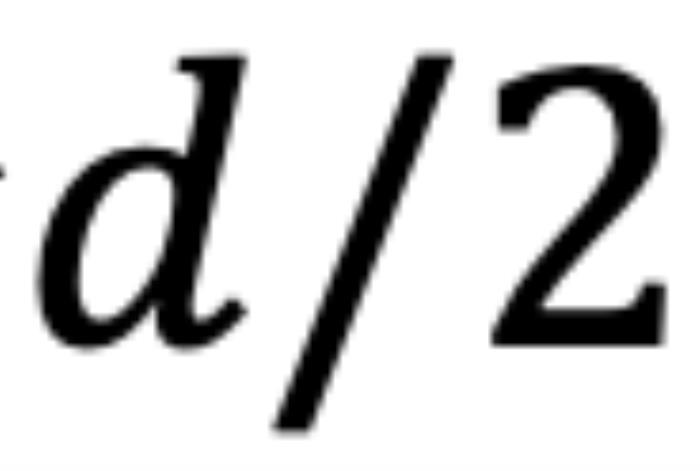 組復(fù)數(shù)中的任意一組
組復(fù)數(shù)中的任意一組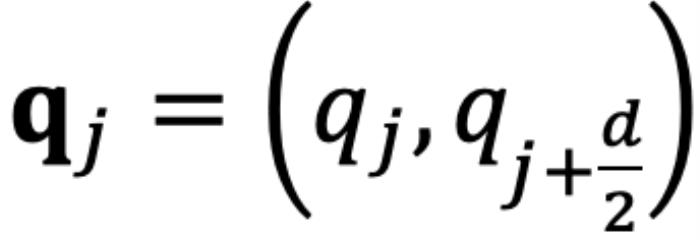 ,
,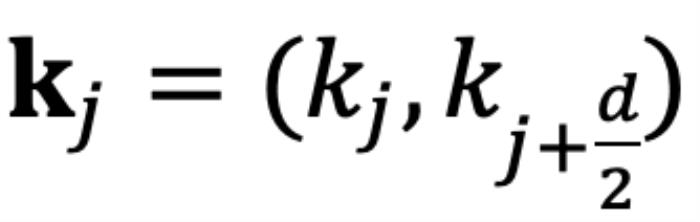 ,它們分別具有位置索引m和n。不失一般性,我們假設(shè)復(fù)平面上有一個(gè)小于
,它們分別具有位置索引m和n。不失一般性,我們假設(shè)復(fù)平面上有一個(gè)小于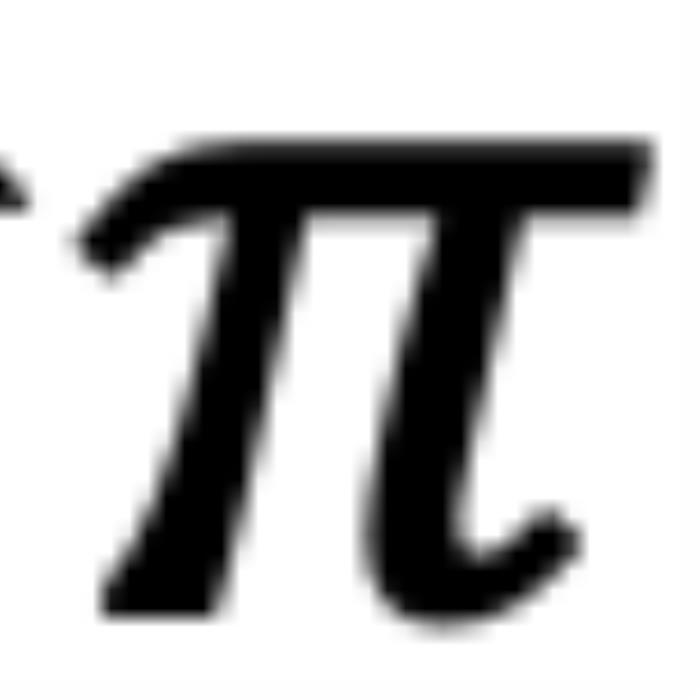 的角度
的角度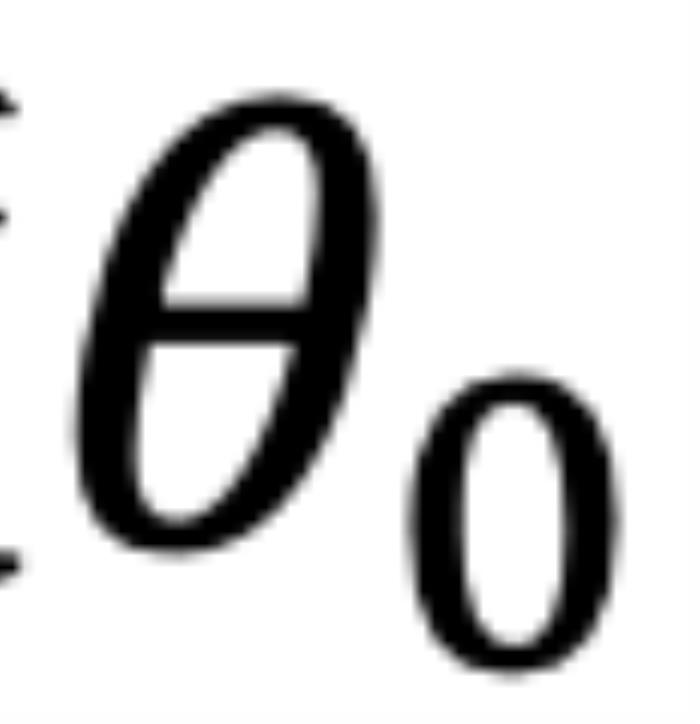 逆時(shí)針從
逆時(shí)針從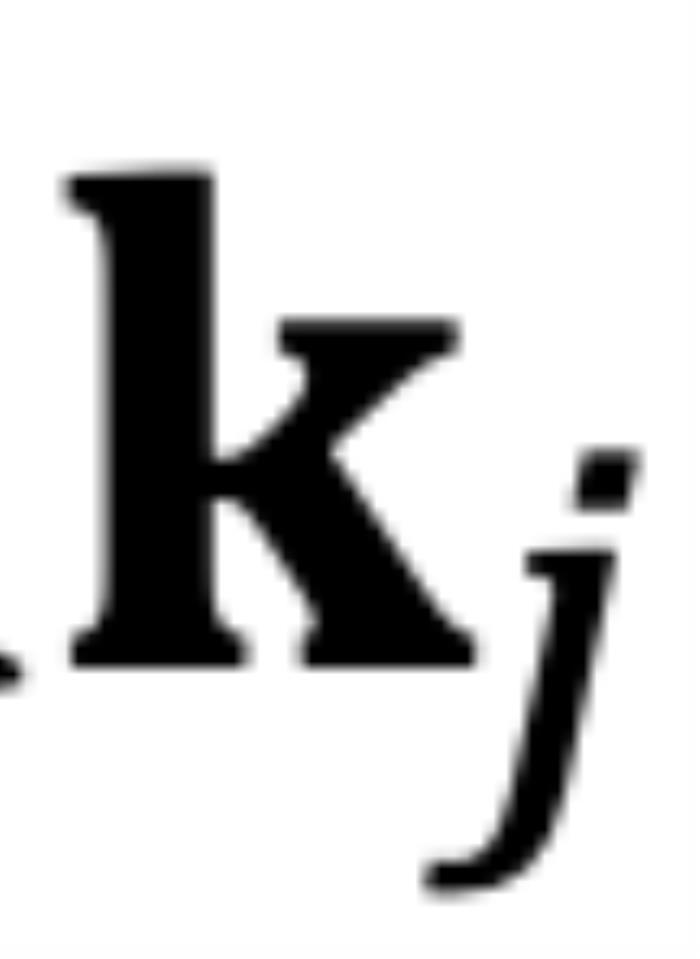 旋轉(zhuǎn)到
旋轉(zhuǎn)到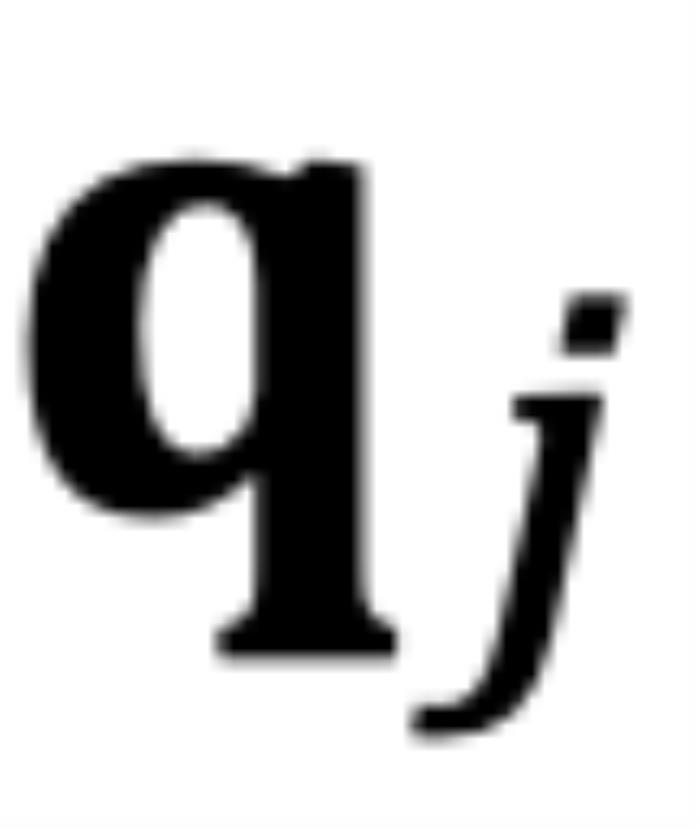 ,那么它們的位置關(guān)系有兩種可能的情況(不考慮 =,因?yàn)樗瞧椒驳模U1P蜿P(guān)系:當(dāng)
,那么它們的位置關(guān)系有兩種可能的情況(不考慮 =,因?yàn)樗瞧椒驳模U1P蜿P(guān)系:當(dāng) 時(shí),如圖 5 右側(cè)所示。注意力分?jǐn)?shù)隨著位置距離的增加而降低(直到它們相對角度超出
時(shí),如圖 5 右側(cè)所示。注意力分?jǐn)?shù)隨著位置距離的增加而降低(直到它們相對角度超出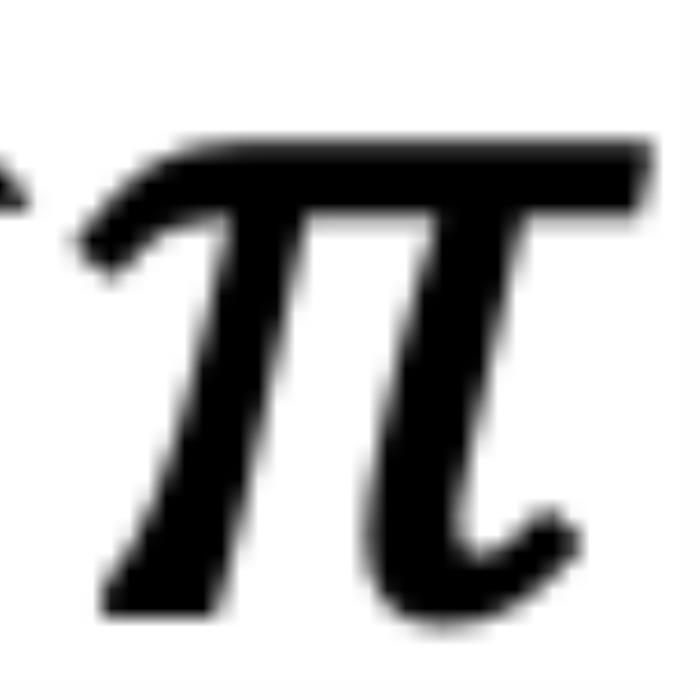 ,超出
,超出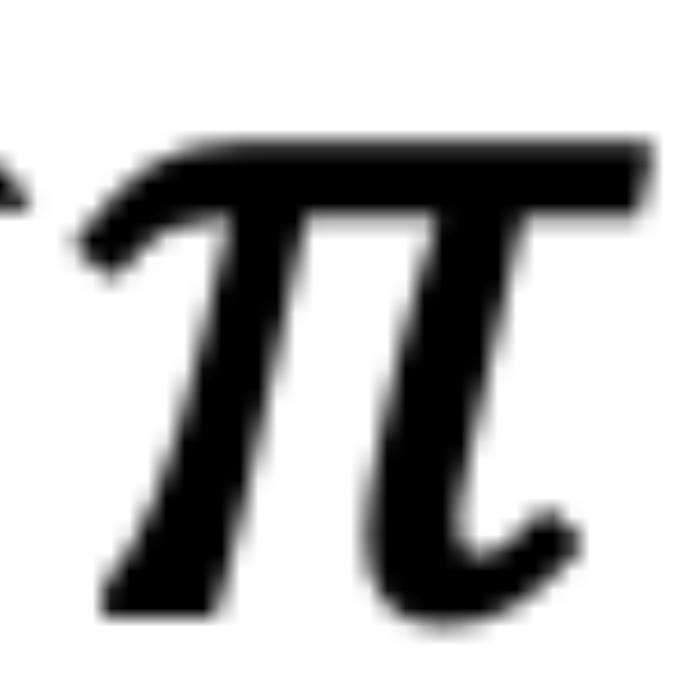 的這部分在原論文附錄中進(jìn)行了討論 (Zhu et al., 2023))。異常行為:然而,當(dāng)
的這部分在原論文附錄中進(jìn)行了討論 (Zhu et al., 2023))。異常行為:然而,當(dāng) 時(shí),如圖 5 左側(cè)所示,異常行為打亂了
時(shí),如圖 5 左側(cè)所示,異常行為打亂了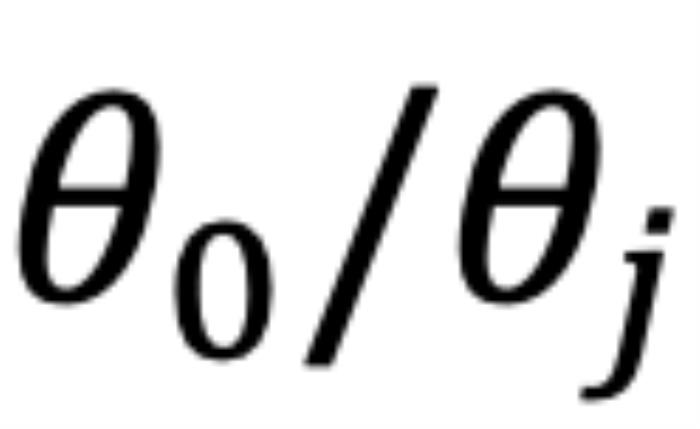 個(gè)最鄰近的 token 的序。當(dāng)
個(gè)最鄰近的 token 的序。當(dāng)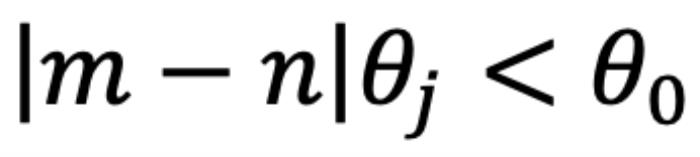 時(shí),
時(shí),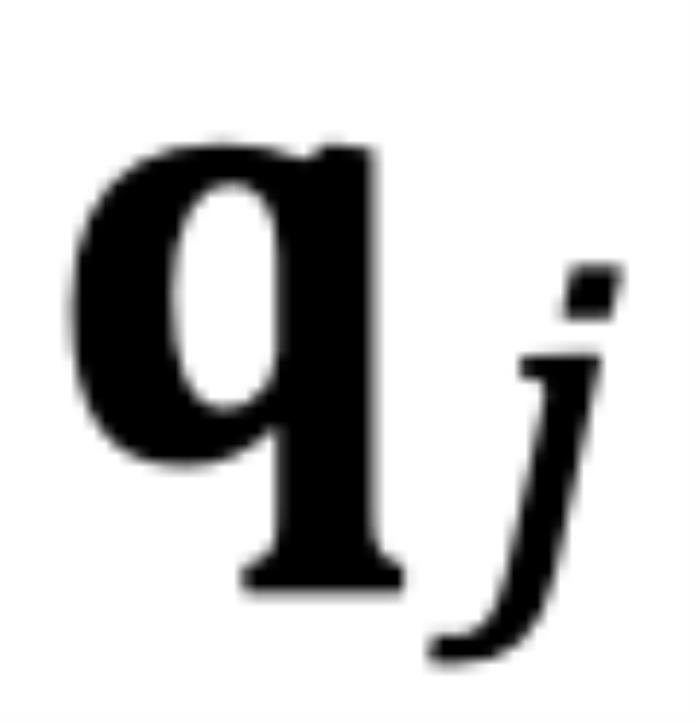 和
和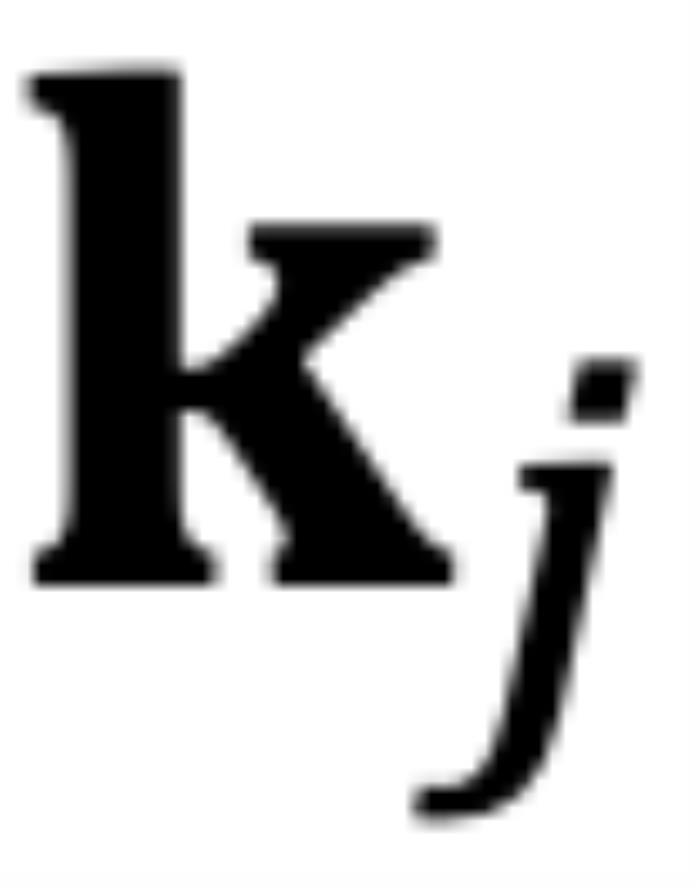 之間的相對角度將隨著
之間的相對角度將隨著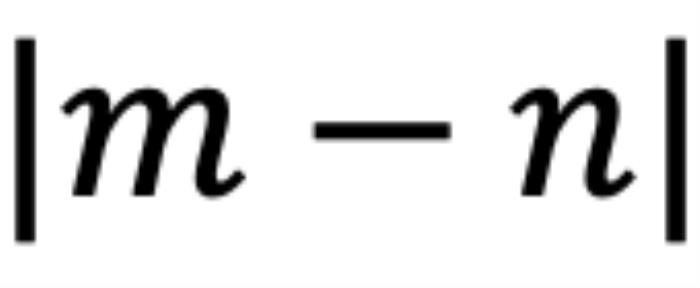 的增大而減小,這意味著最接近的 token 可能會獲得較小的注意力分?jǐn)?shù)。(我們在這里使用 “可能”,因?yàn)樽⒁饬Ψ謹(jǐn)?shù)是
的增大而減小,這意味著最接近的 token 可能會獲得較小的注意力分?jǐn)?shù)。(我們在這里使用 “可能”,因?yàn)樽⒁饬Ψ謹(jǐn)?shù)是 個(gè)內(nèi)積的總和,也許其中一個(gè)是微不足道的。但是,后續(xù)實(shí)驗(yàn)證實(shí)了這一重要性。)并且,無論應(yīng)用 PI 還是 NTK-aware Scaled RoPE,均無法消除這一影響。
個(gè)內(nèi)積的總和,也許其中一個(gè)是微不足道的。但是,后續(xù)實(shí)驗(yàn)證實(shí)了這一重要性。)并且,無論應(yīng)用 PI 還是 NTK-aware Scaled RoPE,均無法消除這一影響。 的角度
的角度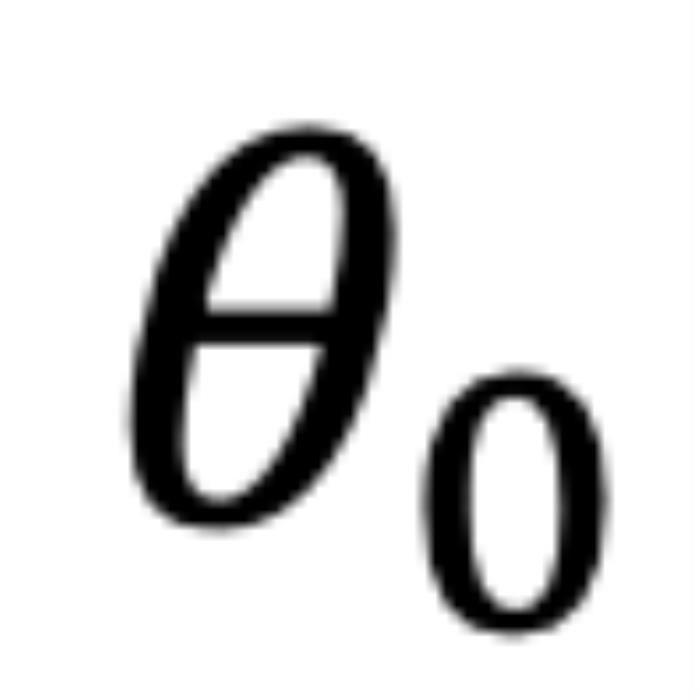 從
從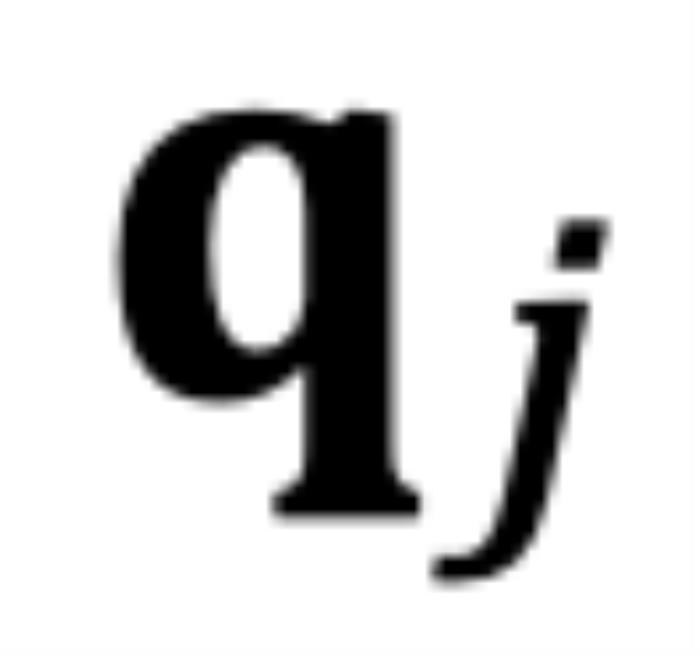 逆時(shí)針旋轉(zhuǎn)到
逆時(shí)針旋轉(zhuǎn)到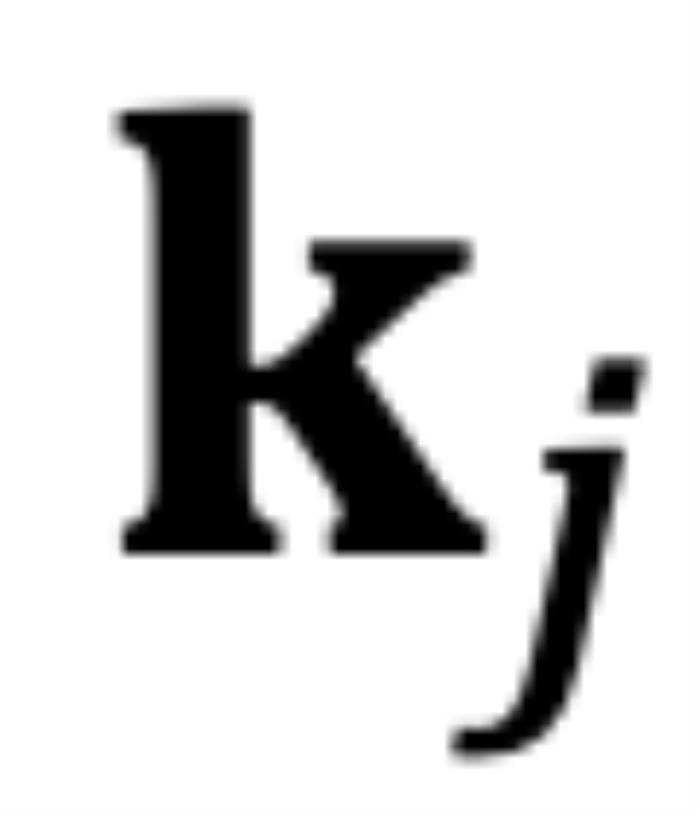 時(shí),而不是從
時(shí),而不是從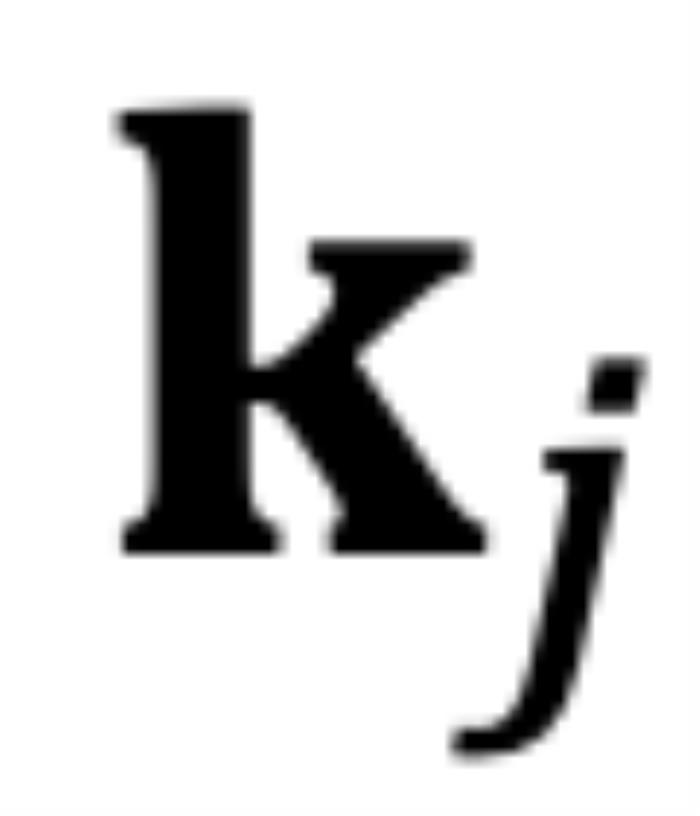 到
到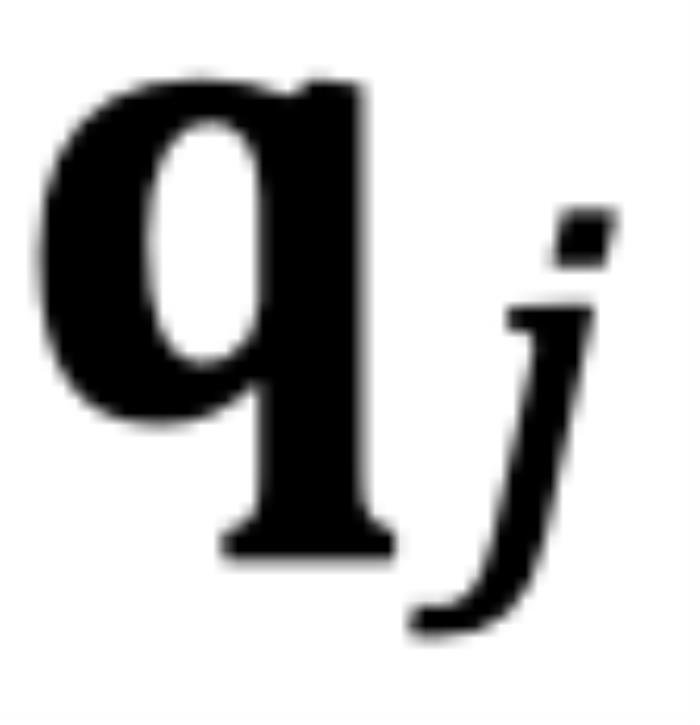 。
。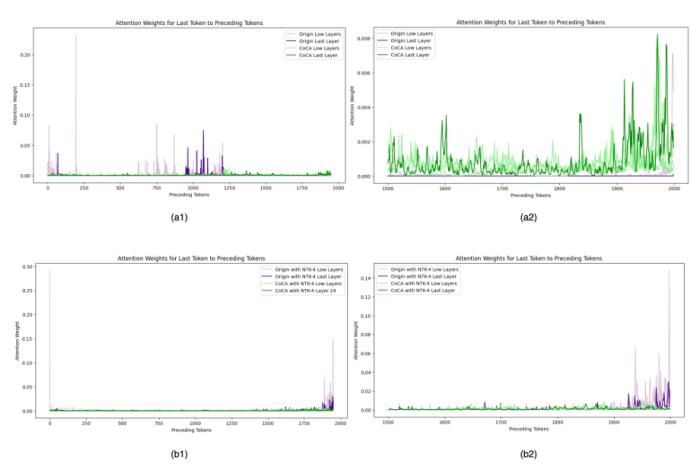 圖11. 外推中的注意力得分,引自(Zhu et al., 2023)Human Eval在論文之外,我們使用相同的數(shù)據(jù)(120B token),相同的模型規(guī)模(1.3B),相同訓(xùn)練配置,基于 CoCA 和 Origin 模型進(jìn)一步評測了 human eval 上的表現(xiàn),與 Origin 模型對比如下:跟 Origin 模型比起來,兩者水平相當(dāng),CoCA 并沒有因?yàn)橥馔颇芰Χ鴮?dǎo)致模型表達(dá)能力產(chǎn)生損失。Origin 模型在 python、java 的表現(xiàn)比其他語言好很多,在 go 上表現(xiàn)較差,CoCA 的表現(xiàn)相對平衡,這與訓(xùn)練語料中 go 的語料較少有關(guān),說明 CoCA 可能有潛在的小樣本學(xué)習(xí)能力。
圖11. 外推中的注意力得分,引自(Zhu et al., 2023)Human Eval在論文之外,我們使用相同的數(shù)據(jù)(120B token),相同的模型規(guī)模(1.3B),相同訓(xùn)練配置,基于 CoCA 和 Origin 模型進(jìn)一步評測了 human eval 上的表現(xiàn),與 Origin 模型對比如下:跟 Origin 模型比起來,兩者水平相當(dāng),CoCA 并沒有因?yàn)橥馔颇芰Χ鴮?dǎo)致模型表達(dá)能力產(chǎn)生損失。Origin 模型在 python、java 的表現(xiàn)比其他語言好很多,在 go 上表現(xiàn)較差,CoCA 的表現(xiàn)相對平衡,這與訓(xùn)練語料中 go 的語料較少有關(guān),說明 CoCA 可能有潛在的小樣本學(xué)習(xí)能力。

HuggingFace:敬請期待
背景知識在深入探討之前,我們快速回顧一些核心的背景知識。長度外推 (Length Extrapolating)長度外推是指大語言模型在處理比其訓(xùn)練數(shù)據(jù)中更長的文本時(shí)的能力。在訓(xùn)練大型語言模型時(shí),通常有一個(gè)最大的序列長度,超過這個(gè)長度的文本需要被截?cái)嗷蚍指睢5趯?shí)際應(yīng)用中,用戶可能會給模型提供比訓(xùn)練時(shí)更長的文本作為輸入,如果模型欠缺長度外推能力或者外推能力不佳,這將導(dǎo)致模型產(chǎn)生無法預(yù)期的輸出,進(jìn)而影響模型實(shí)際應(yīng)用效果。自注意力 (Self-Attention)(Vaswani et al., 2017) 于 2017 年提出的 multi-head self-attention,作為如今大語言模型的內(nèi)核,對于推動人工智能領(lǐng)域的發(fā)展起到了舉足輕重的作用。這里以下圖 1 給出形象化的描述,這項(xiàng)工作本身已經(jīng)被廣泛認(rèn)可,這里不再進(jìn)行贅述。初次接觸大語言模型,對這項(xiàng)工作不甚了解的讀者可以前往原論文獲取更多細(xì)節(jié) (Vaswani et al., 2017)。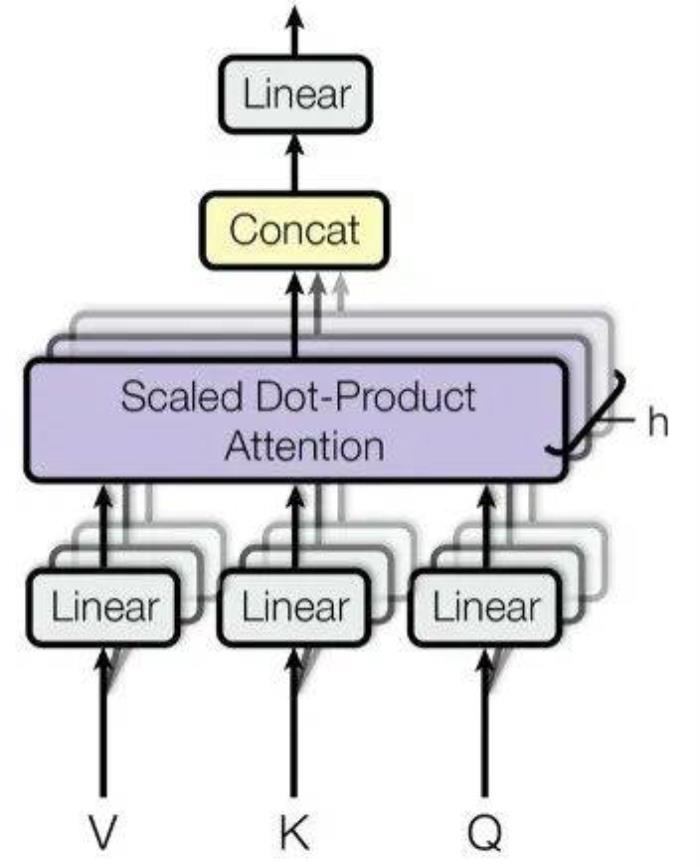
圖1. 多頭注意力機(jī)制示意圖,引自(Vaswani, et al., 2017)。
位置編碼 (Position encoding)由于 self-attention 機(jī)制本身并不直接處理序列中的位置信息,因此引入位置編碼成為必要。由于傳統(tǒng)的 Transformer 中的位置編碼方式由于其外推能力不佳,如今已經(jīng)很少使用,本文不再深入探討傳統(tǒng)的 Transformer 中的編碼方法,對于需要了解更多相關(guān)知識的讀者,可以前往原論文查閱詳情 (Vaswani et al., 2017)。在這里,我們將重點(diǎn)介紹目前非常流行的旋轉(zhuǎn)位置編碼(RoPE)(Su et al., 2021),值得一提的是,Meta 的 LLaMa 系列模型 (Touvron et al., 2023a) 均采用了此種編碼方式。RoPE 從建模美學(xué)的角度來說,是一種十分優(yōu)雅的結(jié)構(gòu),通過將位置信息融入 query 和 key 的旋轉(zhuǎn)之中,來實(shí)現(xiàn)相對位置的表達(dá)。圖2. 旋轉(zhuǎn)位置編碼結(jié)構(gòu),引自(Su et al., 2021)。
位置插值 (Position Interpolation)盡管 RoPE 相比絕對位置編碼的外推性能要優(yōu)秀不少,但仍然無法達(dá)到日新月異的應(yīng)用需求。為此研究人員相繼提出了各種改進(jìn)措施,以 PI (Chen et al., 2023) 和 NTK-aware Scaled RoPE (bloc97, 2023) 為典型代表。但要想取得理想效果,位置插值仍然離不開微調(diào),實(shí)驗(yàn)表明,即使是宣稱無需微調(diào)便可外推的 NTK-aware Scaled RoPE,在傳統(tǒng) attention 架構(gòu)下,至多只能達(dá)到 4~8 倍的外推長度,且很難保障良好的語言建模性能和長程依賴能力。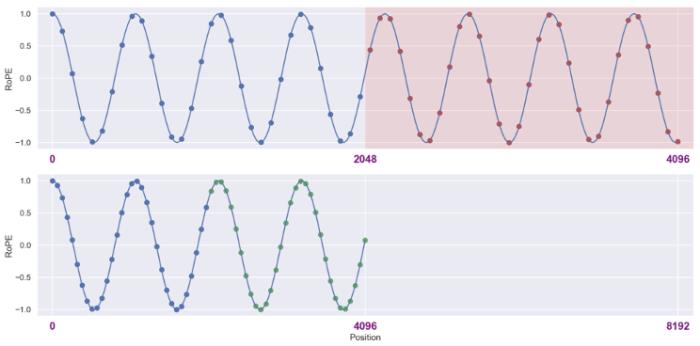
圖3. 位置插值示意圖,引自(Chen et al., 2023)。
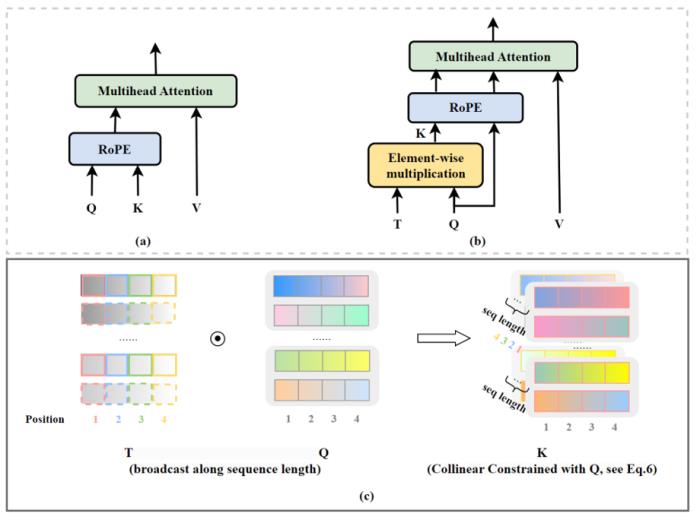
CoCA過去的研究主要集中在位置編碼上,所有相關(guān)研究工作均默認(rèn) self-attention 機(jī)制已經(jīng)被完美實(shí)現(xiàn)。然而,螞蟻人工智能團(tuán)隊(duì)近期發(fā)現(xiàn)了一個(gè)久被忽視的關(guān)鍵:要從根本上解決 Transformer 模型的外推性能問題,self-attention 機(jī)制同樣需要重新考量。圖4. CoCA 模型架構(gòu),引自(Zhu et al., 2023)。
RoPE 與 self-attention 的異常行為在 Transformer 模型中,self-attention 的核心思想是計(jì)算 query(q)和 key(k)之間的關(guān)系。注意力機(jī)制使用這些關(guān)系來決定模型應(yīng)該 “關(guān)注” 輸入序列中的哪些部分。考慮輸入和,分別代表輸入序列中的m個(gè)和第n個(gè)位置索引對應(yīng)的 token,其 query 和 key 分別為和。它們之間的注意力可以表示為一個(gè)函數(shù),如果應(yīng)用 RoPE,則可以進(jìn)一步簡化為僅依賴于m和n相對位置的函數(shù)。從數(shù)學(xué)角度看,可以解釋為組復(fù)數(shù)(,其中d為 hidden dimension 維度,省略位置索引m,n)經(jīng)過旋轉(zhuǎn)后的內(nèi)積之和。這在直覺上是有意義的,因?yàn)槲恢镁嚯x可以建模為一種序,并且兩個(gè)復(fù)數(shù)的內(nèi)積隨著旋轉(zhuǎn)角度 的變化而變化,以圖 5 為例,其中,為和的初始夾角。然而,它隱藏著一個(gè)此前一直被忽略的技術(shù)缺陷。為了便于理解,我們首先考慮雙向注意力模型,例如 Bert (Devlin et al., 2019) 和 GLM (Du et al., 2021) 等。如圖 5 所示,對于組復(fù)數(shù)中的任意一組,,它們分別具有位置索引m和n。不失一般性,我們假設(shè)復(fù)平面上有一個(gè)小于的角度逆時(shí)針從旋轉(zhuǎn)到,那么它們的位置關(guān)系有兩種可能的情況(不考慮 =,因?yàn)樗瞧椒驳模U1P蜿P(guān)系:當(dāng)時(shí),如圖 5 右側(cè)所示。注意力分?jǐn)?shù)隨著位置距離的增加而降低(直到它們相對角度超出,超出的這部分在原論文附錄中進(jìn)行了討論 (Zhu et al., 2023))。異常行為:然而,當(dāng)時(shí),如圖 5 左側(cè)所示,異常行為打亂了個(gè)最鄰近的 token 的序。當(dāng)時(shí),和之間的相對角度將隨著的增大而減小,這意味著最接近的 token 可能會獲得較小的注意力分?jǐn)?shù)。(我們在這里使用 “可能”,因?yàn)樽⒁饬Ψ謹(jǐn)?shù)是個(gè)內(nèi)積的總和,也許其中一個(gè)是微不足道的。但是,后續(xù)實(shí)驗(yàn)證實(shí)了這一重要性。)并且,無論應(yīng)用 PI 還是 NTK-aware Scaled RoPE,均無法消除這一影響。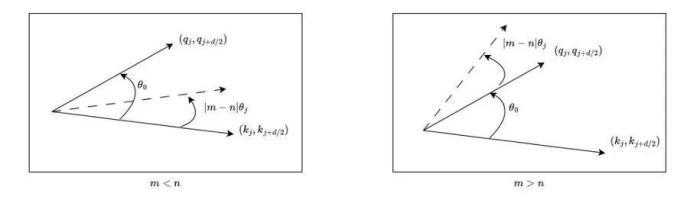
圖5.雙向模型中的序被破壞,引自(Zhu et al., 2023)。
對于因果模型來說,雖然m總是大于n,但問題同樣存在。如圖 6 所示,對于某些j,當(dāng)存在小于的角度從逆時(shí)針旋轉(zhuǎn)到時(shí),而不是從到。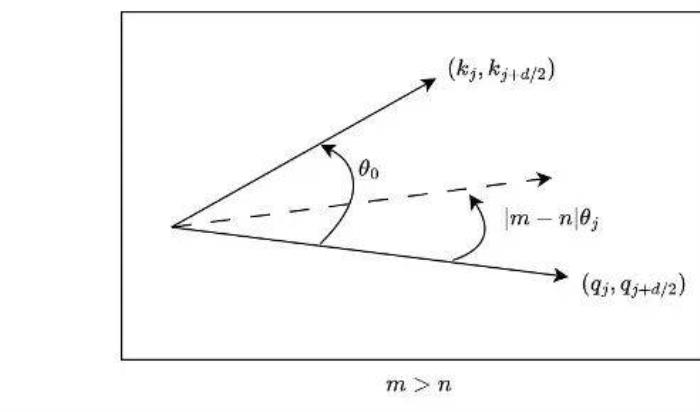
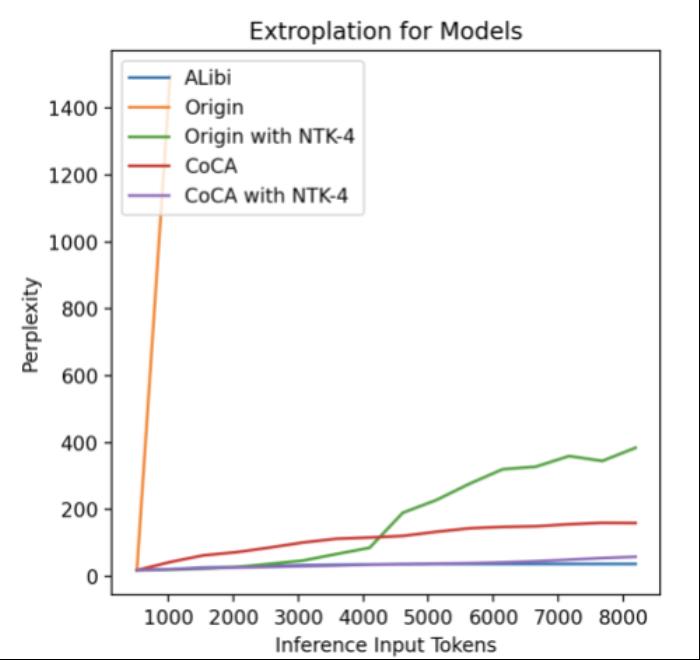
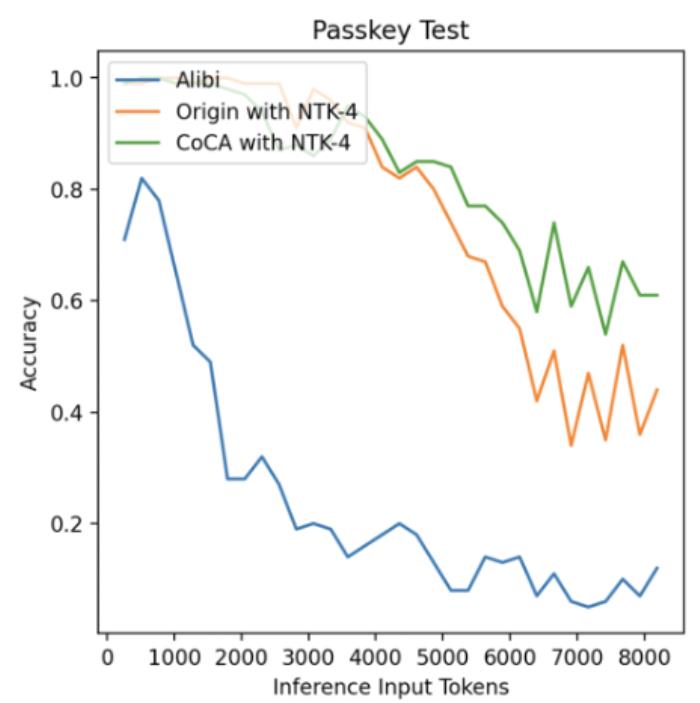
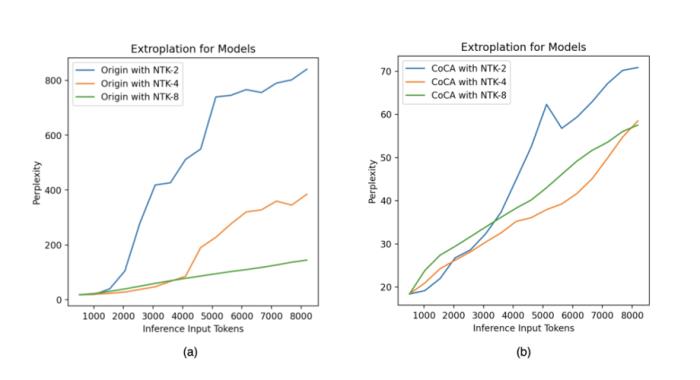
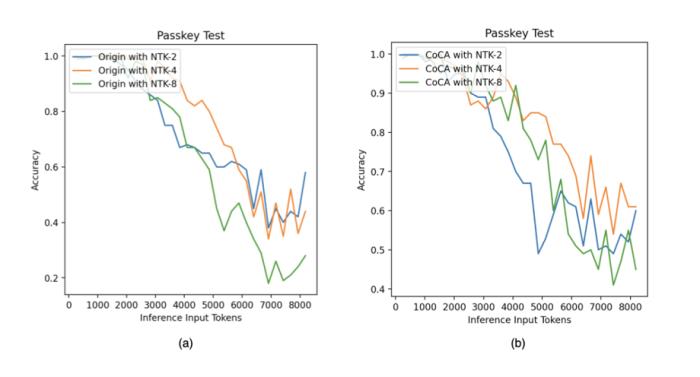
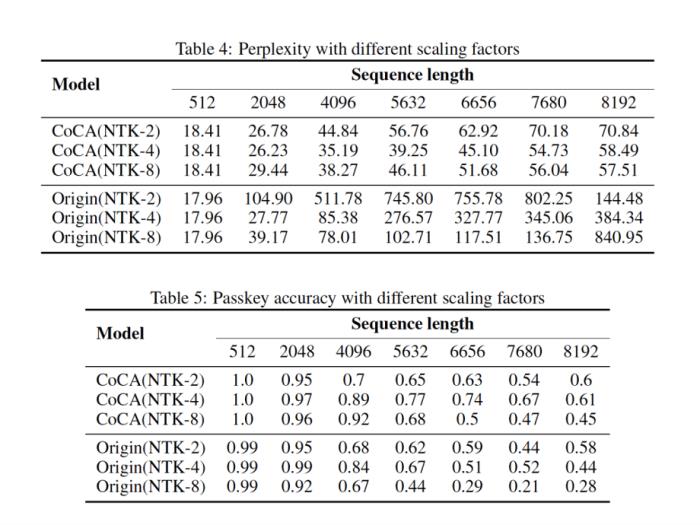
圖11. 外推中的注意力得分,引自(Zhu et al., 2023)Human Eval在論文之外,我們使用相同的數(shù)據(jù)(120B token),相同的模型規(guī)模(1.3B),相同訓(xùn)練配置,基于 CoCA 和 Origin 模型進(jìn)一步評測了 human eval 上的表現(xiàn),與 Origin 模型對比如下:跟 Origin 模型比起來,兩者水平相當(dāng),CoCA 并沒有因?yàn)橥馔颇芰Χ鴮?dǎo)致模型表達(dá)能力產(chǎn)生損失。Origin 模型在 python、java 的表現(xiàn)比其他語言好很多,在 go 上表現(xiàn)較差,CoCA 的表現(xiàn)相對平衡,這與訓(xùn)練語料中 go 的語料較少有關(guān),說明 CoCA 可能有潛在的小樣本學(xué)習(xí)能力。python
java
cpp
js
go
AVG
CoCA
6.71%
6.1%
3.66%
4.27%
6.1%
5.37%
Origin
7.32%
5.49%
5.49%
5.49%
1.83%
5.12%
總結(jié)在這項(xiàng)工作中,螞蟻人工智能團(tuán)隊(duì)發(fā)現(xiàn)了 RoPE 和注意力矩陣之間的某種異常行為,該異常導(dǎo)致注意力機(jī)制與位置編碼的相互作用產(chǎn)生紊亂,特別是在包含關(guān)鍵信息的最近位置的 token。為了從根本上解決這個(gè)問題,論文引入了一種新的自注意力框架,稱為共線約束注意力(CoCA)。論文提供的數(shù)學(xué)證據(jù)展示了該方法的優(yōu)越特性,例如更強(qiáng)的遠(yuǎn)程衰減形式,以及實(shí)際應(yīng)用的計(jì)算和空間效率。實(shí)驗(yàn)結(jié)果證實(shí),CoCA 在長文本語言建模和長程依賴捕獲方面都具有出色的性能。此外,CoCA 能夠與現(xiàn)有的外推、插值技術(shù)以及其他為傳統(tǒng) Transformer 模型設(shè)計(jì)的優(yōu)化方法無縫集成。這種適應(yīng)性表明 CoCA 有潛力演變成 Transformer 模型的增強(qiáng)版本。
關(guān)于 DevOpsGPTDevOpsGPT 是我們發(fā)起的一個(gè)針對 DevOps 領(lǐng)域大模型相關(guān)的開源項(xiàng)目,主要分為三個(gè)模塊。本文介紹的 DevOps-Eval 是其中的評測模塊,其目標(biāo)是構(gòu)建 DevOps 領(lǐng)域 LLM 行業(yè)標(biāo)準(zhǔn)評測。此外,還有 DevOps-Model、DevOps-ChatBot 兩個(gè)模塊,分別為 DevOps 領(lǐng)域?qū)俅竽P秃?DevOps 領(lǐng)域智能助手。我們的目標(biāo)是在 DevOps 領(lǐng)域,包含開發(fā)、測試、運(yùn)維、監(jiān)控等場景,真正地結(jié)合大模型來提升效率、成本節(jié)約。我們期望相關(guān)從業(yè)者一起貢獻(xiàn)自己的才智,來讓 “天下沒有難做的 coder”,我們也會定期分享對于 LLM4DevOps 領(lǐng)域的經(jīng)驗(yàn) & 嘗試。歡迎使用 & 討論 & 共建
相關(guān)推薦




- 免責(zé)聲明
- 本文所包含的觀點(diǎn)僅代表作者個(gè)人看法,不代表新火種的觀點(diǎn)。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對本文可能提及或鏈接的任何項(xiàng)目不表示認(rèn)可。 交易和投資涉及高風(fēng)險(xiǎn),讀者在采取與本文內(nèi)容相關(guān)的任何行動之前,請務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨(dú)立判斷。新火種不對因依賴本文觀點(diǎn)而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
