

 新火種
2023-11-14
新火種
2023-11-14 


全新近似注意力機制HyperAttention:對長上下文友好、LLM推理提速50%
本文介紹了一項近似注意力機制新研究,耶魯大學、谷歌研究院等機構提出了 HyperAttention,使 ChatGLM2 在 32k 上下文長度上的推理時間快了 50%。Transformer 已經成功應用于自然語言處理、計算機視覺和時間序列預測等領域的各種學習任務。雖然取得了成功,但這些模型仍面臨著嚴重的可擴展性限制,原因是對其注意力層的精確計算導致了二次(在序列長度上)運行時和內存復雜性。這對將 Transformer 模型擴展到更長的上下文長度帶來了根本性的挑戰。業界已經探索了各種方法來解決二次時間注意力層的問題,其中一個值得注意的方向是近似注意力層中的中間矩陣。實現這一點的方法包括通過稀疏矩陣、低秩矩陣進行近似,或兩者的結合。然而,這些方法并不能為注意力輸出矩陣的近似提供端到端的保證。這些方法旨在更快地逼近注意力的各個組成部分,但沒有一種方法能提供完整點積注意力的端到端逼近。這些方法還不支持使用因果掩碼,而因果掩碼是現代 Transformer 架構的重要組成部分。最近的理論邊界表明,在一般情況下,不可能在次二次時間內對注意力矩陣進行分項近似。不過,最近一項名為 KDEFormer 的研究表明,在注意力矩陣項有界的假設條件下,它能在次二次時間內提供可證明的近似值。從理論上講,KDEFormer 的運行時大約為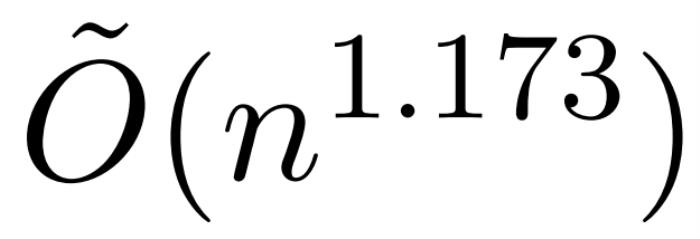 ;它采用核密度估計 (kernel density estimation,KDE) 來近似列范數,允許計算對注意力矩陣的列進行采樣的概率。然而,目前的 KDE 算法缺乏實際效率,即使在理論上,KDEFormer 的運行時與理論上可行的 O (n) 時間算法之間也有差距。在文中,作者證明了在同樣的有界條目假設下,近線性時間的
;它采用核密度估計 (kernel density estimation,KDE) 來近似列范數,允許計算對注意力矩陣的列進行采樣的概率。然而,目前的 KDE 算法缺乏實際效率,即使在理論上,KDEFormer 的運行時與理論上可行的 O (n) 時間算法之間也有差距。在文中,作者證明了在同樣的有界條目假設下,近線性時間的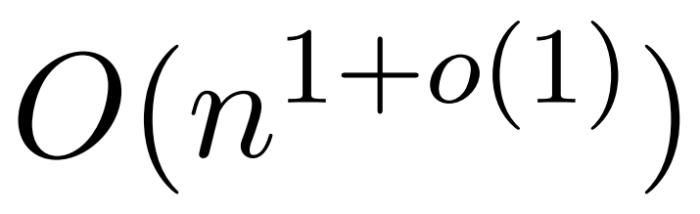 算法是可能的。不過,他們的算法還涉及使用多項式方法來逼近 softmax,很可能不切實際。而在本文中,來自耶魯大學、谷歌研究院等機構的研究者提供了一種兩全其美的算法,既實用高效,又是能實現最佳近線性時間保證。此外,該方法還支持因果掩碼,這在以前的工作中是不可能實現的。
算法是可能的。不過,他們的算法還涉及使用多項式方法來逼近 softmax,很可能不切實際。而在本文中,來自耶魯大學、谷歌研究院等機構的研究者提供了一種兩全其美的算法,既實用高效,又是能實現最佳近線性時間保證。此外,該方法還支持因果掩碼,這在以前的工作中是不可能實現的。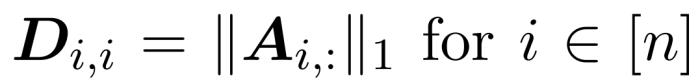 。在這種情況下,矩陣 A 被稱為「注意力矩陣」,(D^-1 ) A 被稱為「softmax 矩陣」。值得注意的是,直接計算注意力矩陣 A 需要 Θ(n2d)運算,而存儲它需要消耗 Θ(n2)內存。因此,直接計算 Att 需要 Ω(n2d)的運行時和 Ω(n2)的內存。研究者目標是高效地近似輸出矩陣 Att,同時保留其頻譜特性。他們的策略包括為對角縮放矩陣 D 設計一個近線性時間的高效估計器。此外,他們通過子采樣快速逼近 softmax 矩陣 D^-1A 的矩陣乘積。更具體地說,他們的目標是找到一個具有有限行數
。在這種情況下,矩陣 A 被稱為「注意力矩陣」,(D^-1 ) A 被稱為「softmax 矩陣」。值得注意的是,直接計算注意力矩陣 A 需要 Θ(n2d)運算,而存儲它需要消耗 Θ(n2)內存。因此,直接計算 Att 需要 Ω(n2d)的運行時和 Ω(n2)的內存。研究者目標是高效地近似輸出矩陣 Att,同時保留其頻譜特性。他們的策略包括為對角縮放矩陣 D 設計一個近線性時間的高效估計器。此外,他們通過子采樣快速逼近 softmax 矩陣 D^-1A 的矩陣乘積。更具體地說,他們的目標是找到一個具有有限行數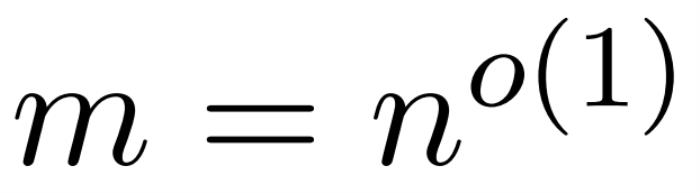 的采樣矩陣
的采樣矩陣 以及一個對角矩陣
以及一個對角矩陣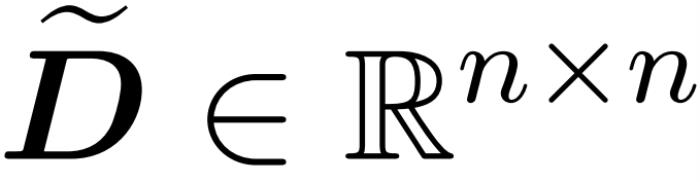 ,從而滿足誤差的算子規范的以下約束:
,從而滿足誤差的算子規范的以下約束: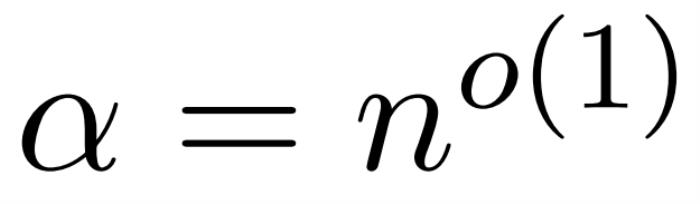 ,使得
,使得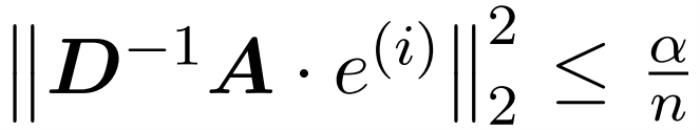 。算法的第一步是使用 Hamming 排序 LSH (sortLSH) 將鍵和查詢散列到大小均勻的桶中,從而識別注意力矩陣 A 中的大型條目。算法 1 詳細介紹了這一過程,圖 1 直觀地說明了這一過程。
。算法的第一步是使用 Hamming 排序 LSH (sortLSH) 將鍵和查詢散列到大小均勻的桶中,從而識別注意力矩陣 A 中的大型條目。算法 1 詳細介紹了這一過程,圖 1 直觀地說明了這一過程。 和近似
和近似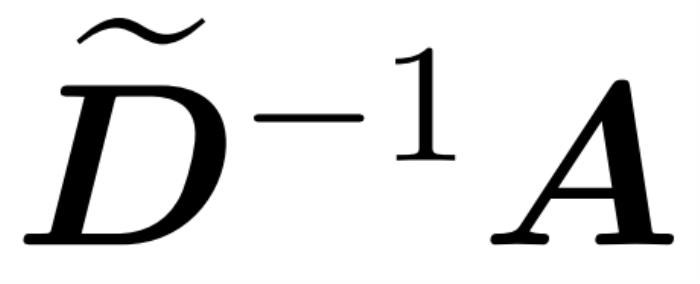 與值矩陣V 之間矩陣乘積的子程序。因此,研究者引入了 HyperAttention,這是一種高效算法,可以在近似線性時間內近似公式(1)中具有頻譜保證的注意力機制。算法 3 將定義注意力矩陣中主導條目的位置的掩碼 MH 作為輸入。這個掩碼可以使用 sortLSH 算法(算法 1)生成,也可以是一個預定義的掩碼,類似于 [7] 中的方法。研究者假定大條目掩碼 M^H 在設計上是稀疏的,而且其非零條目數是有界的
與值矩陣V 之間矩陣乘積的子程序。因此,研究者引入了 HyperAttention,這是一種高效算法,可以在近似線性時間內近似公式(1)中具有頻譜保證的注意力機制。算法 3 將定義注意力矩陣中主導條目的位置的掩碼 MH 作為輸入。這個掩碼可以使用 sortLSH 算法(算法 1)生成,也可以是一個預定義的掩碼,類似于 [7] 中的方法。研究者假定大條目掩碼 M^H 在設計上是稀疏的,而且其非零條目數是有界的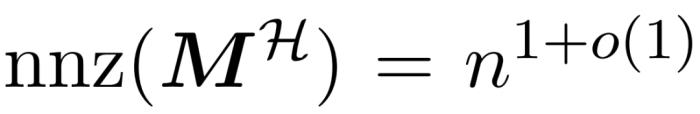 。如圖 2 所示,本文方法基于一個重要的觀察結果。屏蔽注意力 M^C⊙A 可以分解成三個非零矩陣,每個矩陣的大小是原始注意力矩陣的一半。完全位于對角線下方的 A_21 塊是未屏蔽注意力。因此,我們可以使用算法 2 近似計算其行和。圖 2 中顯示的兩個對角線區塊
。如圖 2 所示,本文方法基于一個重要的觀察結果。屏蔽注意力 M^C⊙A 可以分解成三個非零矩陣,每個矩陣的大小是原始注意力矩陣的一半。完全位于對角線下方的 A_21 塊是未屏蔽注意力。因此,我們可以使用算法 2 近似計算其行和。圖 2 中顯示的兩個對角線區塊 和
和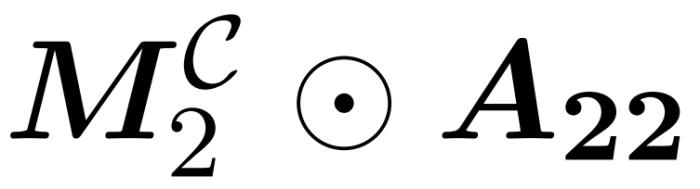 是因果注意力,其大小只有原來的一半。為了處理這些因果關系,研究者采用遞歸方法,將它們進一步分割成更小的區塊,并重復這一過程。算法 4 中給出了這一過程的偽代碼。
是因果注意力,其大小只有原來的一半。為了處理這些因果關系,研究者采用遞歸方法,將它們進一步分割成更小的區塊,并重復這一過程。算法 4 中給出了這一過程的偽代碼。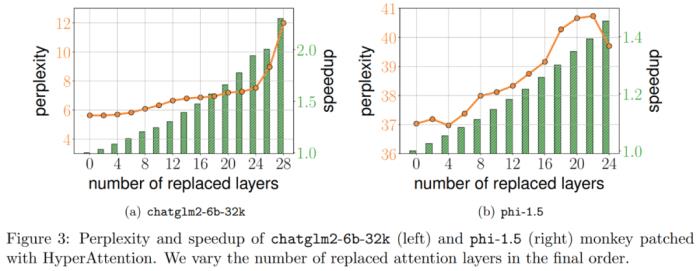 此外,研究者評估了 LongBench 數據集上 monkey patched chatglm2-6b-32k 的性能,并計算單 / 多文檔問答、摘要、小樣本學習、合成任務和代碼補全等各自任務上的評估分數。結果如下表 1 所示。雖然替換 HyperAttention 通常會導致性能下降,但他們觀察到它的影響會基于手頭任務發生變化。例如,摘要和代碼補全相對于其他任務具有最強的穩健性。
此外,研究者評估了 LongBench 數據集上 monkey patched chatglm2-6b-32k 的性能,并計算單 / 多文檔問答、摘要、小樣本學習、合成任務和代碼補全等各自任務上的評估分數。結果如下表 1 所示。雖然替換 HyperAttention 通常會導致性能下降,但他們觀察到它的影響會基于手頭任務發生變化。例如,摘要和代碼補全相對于其他任務具有最強的穩健性。
;它采用核密度估計 (kernel density estimation,KDE) 來近似列范數,允許計算對注意力矩陣的列進行采樣的概率。然而,目前的 KDE 算法缺乏實際效率,即使在理論上,KDEFormer 的運行時與理論上可行的 O (n) 時間算法之間也有差距。在文中,作者證明了在同樣的有界條目假設下,近線性時間的算法是可能的。不過,他們的算法還涉及使用多項式方法來逼近 softmax,很可能不切實際。而在本文中,來自耶魯大學、谷歌研究院等機構的研究者提供了一種兩全其美的算法,既實用高效,又是能實現最佳近線性時間保證。此外,該方法還支持因果掩碼,這在以前的工作中是不可能實現的。
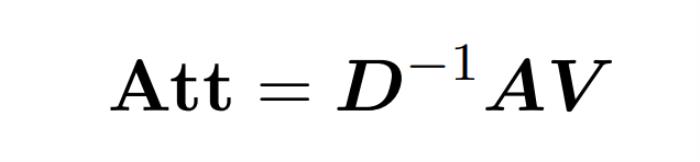
。在這種情況下,矩陣 A 被稱為「注意力矩陣」,(D^-1 ) A 被稱為「softmax 矩陣」。值得注意的是,直接計算注意力矩陣 A 需要 Θ(n2d)運算,而存儲它需要消耗 Θ(n2)內存。因此,直接計算 Att 需要 Ω(n2d)的運行時和 Ω(n2)的內存。研究者目標是高效地近似輸出矩陣 Att,同時保留其頻譜特性。他們的策略包括為對角縮放矩陣 D 設計一個近線性時間的高效估計器。此外,他們通過子采樣快速逼近 softmax 矩陣 D^-1A 的矩陣乘積。更具體地說,他們的目標是找到一個具有有限行數的采樣矩陣以及一個對角矩陣,從而滿足誤差的算子規范的以下約束: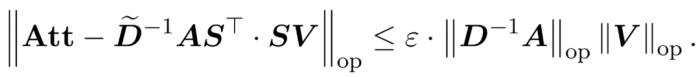
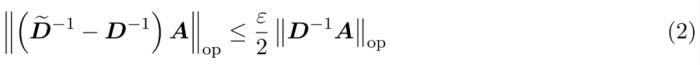
,使得。算法的第一步是使用 Hamming 排序 LSH (sortLSH) 將鍵和查詢散列到大小均勻的桶中,從而識別注意力矩陣 A 中的大型條目。算法 1 詳細介紹了這一過程,圖 1 直觀地說明了這一過程。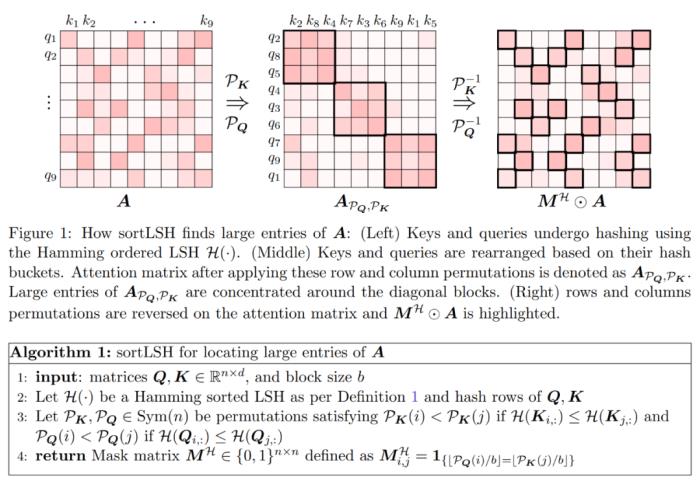


和近似與值矩陣V 之間矩陣乘積的子程序。因此,研究者引入了 HyperAttention,這是一種高效算法,可以在近似線性時間內近似公式(1)中具有頻譜保證的注意力機制。算法 3 將定義注意力矩陣中主導條目的位置的掩碼 MH 作為輸入。這個掩碼可以使用 sortLSH 算法(算法 1)生成,也可以是一個預定義的掩碼,類似于 [7] 中的方法。研究者假定大條目掩碼 M^H 在設計上是稀疏的,而且其非零條目數是有界的。如圖 2 所示,本文方法基于一個重要的觀察結果。屏蔽注意力 M^C⊙A 可以分解成三個非零矩陣,每個矩陣的大小是原始注意力矩陣的一半。完全位于對角線下方的 A_21 塊是未屏蔽注意力。因此,我們可以使用算法 2 近似計算其行和。圖 2 中顯示的兩個對角線區塊和是因果注意力,其大小只有原來的一半。為了處理這些因果關系,研究者采用遞歸方法,將它們進一步分割成更小的區塊,并重復這一過程。算法 4 中給出了這一過程的偽代碼。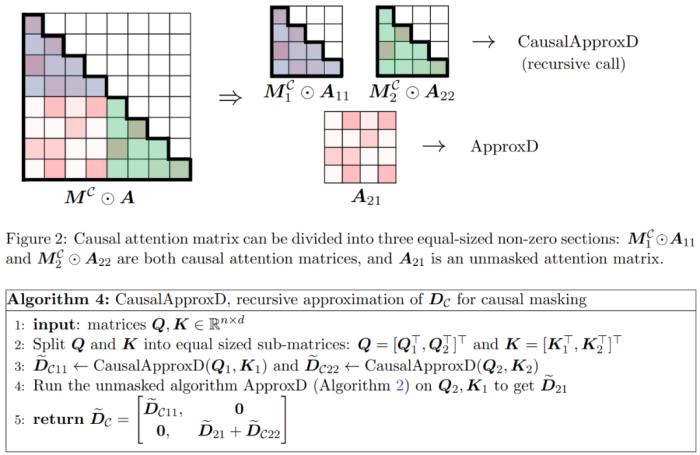
此外,研究者評估了 LongBench 數據集上 monkey patched chatglm2-6b-32k 的性能,并計算單 / 多文檔問答、摘要、小樣本學習、合成任務和代碼補全等各自任務上的評估分數。結果如下表 1 所示。雖然替換 HyperAttention 通常會導致性能下降,但他們觀察到它的影響會基于手頭任務發生變化。例如,摘要和代碼補全相對于其他任務具有最強的穩健性。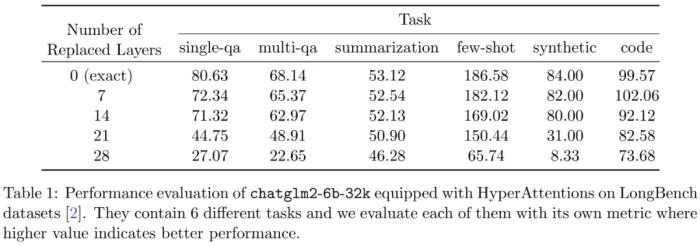
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
