

 新火種
2023-11-08
新火種
2023-11-08 


HuggingFace聯創發推:高質量微調數據集才是“卷”大模型的正確姿勢
最近,NLP大牛、HuggingFace聯合創始人Thomas Wolf 發了一條推特,內容很長,講了一個 “全球三大洲的人們公開合作,共同打造出一個新穎、高效且前沿的小型AI模型” 的故事。
故事是這樣開始的,在幾個月前,巴黎的一個新團隊發布了他們首個模型:Mistral 7B,這個模型體積小巧但性能強勁,在基準測試中的表現超過了所有同類模型。
這還是個開源項目,意味著大家都可以在此基礎上進行開發。
另一個研究模型微調和對齊的H4團隊的兩名成員,在Hugging Face舉辦的一次小聚中,他們邊喝咖啡邊討論用斯坦福大學新發表的DPO方法對Mistral 7B這個模型進行微調的可能性,最后他們決定用已經構建好的代碼庫先來嘗試下。
之后,他們在HF hub上找到了一些公開的數據集,包括由面壁智能和清華大學NLP共同支持的OpenBMB新近開源的兩個大規模、高質量的微調數據集:UltraFeedback和UltraChat。
UltraFeedback,一個大規模、多樣化、細粒度 的偏好數據集,包括 25萬 條對話數據以及相應的偏好標注數據。在非社區標注的偏好數據集中,這一數據規模排在首位。并且,其中每條偏好標注均包含四個方面的細粒度得分與的詳細文字說明。
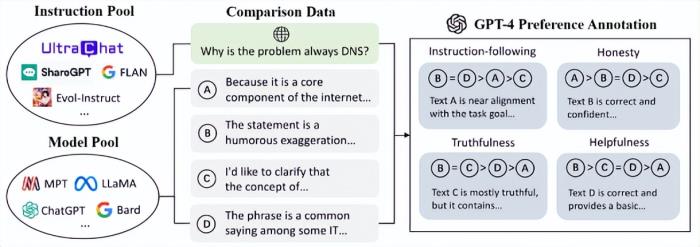
UltraChat則是高質量的對話數據集,包含了 150 余萬條多輪指令數據。調用多個 ChatGPT API 相互對話,從而生成多輪對話數據。
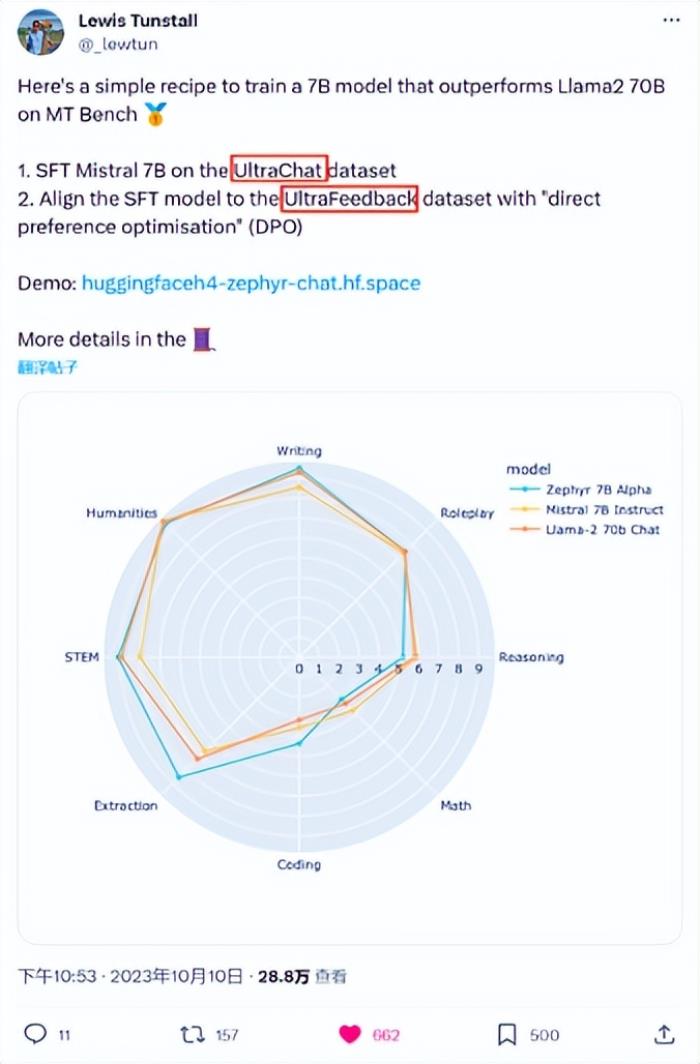
經過幾輪實驗證明,使用OpenBMB兩個數據集訓練出來的新模型非常強大,是H4團隊 在伯克利和斯坦福的基準測試中見過的最強模型。
不久,這個名為“Zephyr”的模型、研究論文以及所有細節都向世界公開了,此后全球各地的公司開始應用這一模型。LlamaIndex,一個知名的數據框架和社區,分享了這個模型在實際用例基準測試中超乎預期的表現,與此同時,研究者和實踐者們在Hugging Face hub上熱烈討論著這篇論文和相關工作。
Zephyr-7B性能 超越參數十倍之大的 LLaMA2-70B-Chat。
短短幾周就創造了這個 開源神話。Thomas Wolf指出,這一切都得益于世界各地(歐洲、加利福尼亞、中國)對知識、模型、研究和數據集的開放獲取,以及人們在AI上相互建設、相互借鑒,共同創造出真正有價值的高效開放模型的理念。
開源精神以自由和合作為信條,讓人類再次聯合起來重建通天巴別塔。開源旨在打破人為壁壘,通過開放透明的方式促進技術和知識的創新共享。對于個體或組織而言,擁抱開源則是一種強者心態。
值得一提的是,OpenBMB開源社區背后的國內領先的人工智能公司 面壁智能,一直聯合清華大學NLP實驗室為大模型事業做高質量的開源貢獻的同時,一直深耕大模型底層的數據工作。
就拿此次被Zephyr-7B運用的UltraFeedback為例,UltraFeedback 從多個社區開源的指令數據集中收集了約 6 萬條指令。基于這些指令,UltraFeedback 從 17 種不同架構、參數量、訓練數據的模型中隨機選取 4 種不同模型,為每條指令生成4種有區分度的回復,極大地提升了指令和模型的多樣性。
基于 UltraFeedback,團隊還訓練了UltraRM、UltraCM兩個模型來進一步輔助模型評測和模型反饋學習。
在大家都在卷模型參數時,一個基于高質量數據集的7B模型就打敗了參數十倍之大的 LLaMA2-70B-Chat。這說明了什么?
說明,底層的數據工作才是最稀缺的和有時間價值的,這或許是各家各派大模型在百模大戰中的突破口之一。
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
