

 新火種
2023-11-02
新火種
2023-11-02 



改進機器學習模型,怎么少的了主動學習?!
全文共2059字,預計學習時長4分鐘

圖片來源:pexels.com/@pixabay
本文將闡述如何通過主動學習迭代改善機器學習模型的性能。這項技能適用于任何模型,但是本文將對主動學習如何改進二進制文本分類器進行說明。以下所有內容基于微軟2018年Strata數據會議教程《將R和Python用于可擴展的數據科學、機器學習和人工智能》。

方法
數據集
通過在Wikipedia Detox數據集上構建一個二進制文本分類器來闡述主動學習的概念,以檢測注釋是否造成人身攻擊。這里有一些例子來說明這個問題:

訓練集有115,374個被標注的例子。現將這個訓練集分為三個集合,即初始訓練集、未標注訓練集和測試集,具體如下:

此外,標注在初始訓練集中分布均勻,但在測試集中只有13%的標注為1。
通過這種方式分割訓練集來模擬現實情況。其對應情況是有10285個高質量的被標注的例子,決定105089個“未標注”的例子中哪些需要標注,以得到更多的訓練數據來訓練分類器。因為標注數據很昂貴,所以確定對模型性能最有用的例子是一個挑戰。
就未標注訓練集來說,主動學習相對于隨機抽樣是一種更好的抽樣法。
最后使用Glove單詞嵌入將注釋轉換為50維嵌入式。
抽樣法
使用的抽樣法是不確定性抽樣和聯合抽樣二者的結合。其工作方式是:
1. 從未標注訓練集中隨機選擇1000個樣本。
2. 使用歐氏距離作為距離度量(這是集合部分),在這1000個樣本上構建一個分集聚類。
3. 將分集聚類的輸出分為20組。
4. 對每一組選擇熵entropy最大的樣本。即選取模型最不確定的觀測值。
以上是為了模擬一次只能得到20個高質量標注的情況,例如,一名放射科醫生一天只能處理20張醫學圖像。沒有對整個未標注訓練集聚類,是因為計算熵需要進行模型推導,而這在大型數據集中可能需要花很長的時間。
聚類樣本的原因是為了最大化增加標注樣本的多樣性。例如,若簡單從1000個樣本中選出熵最高的前20個,如果這些樣本緊密,就有可能選出非常相似的樣本。這種情況最好只從這個組中選擇一個例子,剩余從另一個組中選擇,因為不同例子有助于更好學習模型。
模型
通過FastTrees來構建分類器,用注釋的矢量嵌入作為輸入。FastTrees是FastRank的實現,FastRank是梯度提升算法的一種變體。
評價指標
由于測試集不平衡,將使用AUC作為主要的評價指標。
實現細節
下面的圖表來說明主動學習在此實驗中所起的作用:
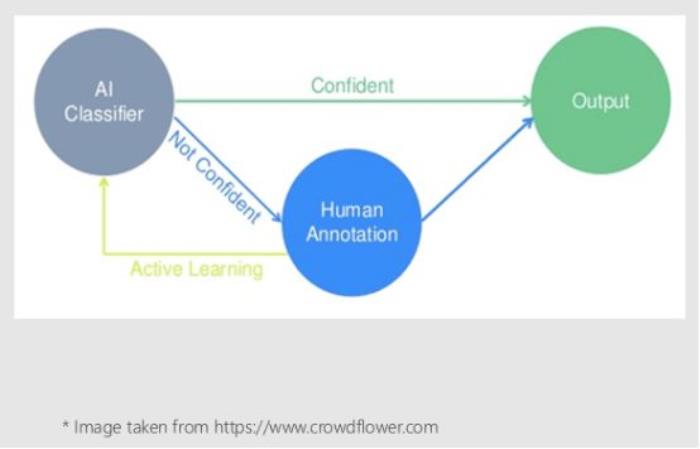
首先會在初始訓練集上訓練模型,然后使用這個模型和上述的抽樣法來識別未標注訓練集中分類最不確定即沒有信心的20個注釋,并進行人工標注。現在可以擴展初始訓練集,包括人工新的標注樣本,和重新訓練模型(從零開始)。這是實驗的主動學習部分。會重復20次迭代擴展初始訓練集的步驟,并在每次迭代結束時評估模型在測試集上的性能。
結果
為了比較,可以通過從未標注的訓練集中隨機抽取任意20個例子來迭代擴展初始訓練集。下圖比較了主動學習方法(active)和3次隨機抽樣(random),根據訓練集(tss)大小使用不同度量。

看得出最初隨機抽樣優于主動學習方法。然而,在訓練集大小為300左右時,主動學習方法在AUC方面開始大幅度超過隨機抽樣。
在實踐中可能會繼續擴展初始訓練集,直到模型改進(例如AUC的增加)相對于標注成本的比率下降到預先確定的閾值以下。
驗證結果
為了確保得到的結果并非巧合,可以模擬隨機抽樣法進行100次20個迭代,并計算產生的AUC大于主動學習方法的次數。模擬結果只產生了一個隨機抽樣的AUC比主動學習高的例子。這表明主動學習的結果有5%的統計學意義。最后得出,隨機抽樣與主動學習的AUC平均差異為-0.03。
結論
在有大量未標注的數據和有限的預算來標注這些數據的情況下,采用主動學習的方法來確定哪些未標注的數據,通過人工標注可以在給定預算的限制下將模型的性能最大化。

留言 點贊 關注
我們一起分享AI學習與發展的干貨
歡迎關注全平臺AI垂類自媒體 “讀芯術”
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
