

 新火種
2023-11-01
新火種
2023-11-01 


阿里云千億新“模王”打底,5分鐘可以開發一款大模型應用了
剛剛,阿里云搬出通義大模型“全家桶”炸場了!
就在今天的云棲大會上,不僅通義千問升級至千億級參數2.0版本,在10個權威評測中,綜合性能超越GPT3.5、加速追趕GPT-4,可以通過通義千問APP體驗,阿里云還把打造大模型應用的“秘籍”也給公開了。

現在,只需給出問題,基于阿里云通義代碼大模型打造的智能編碼助手“通義靈碼”,就會自動編寫代碼。
比如,跟它說“幫我用Python寫一個飛機游戲”,短短幾秒,它就能迅速吐出100+行代碼,替換參數直接用:

開發一個大模型應用,最快也只需5分鐘就能搞定:
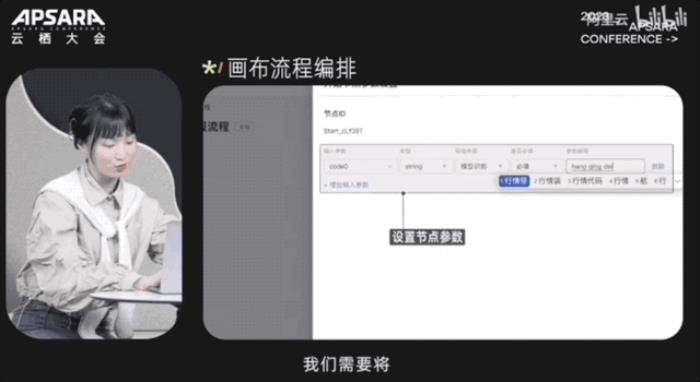
大會現場,阿里云CTO周靖人還透露,這波全家桶背后,阿里云將底層算力到AI平臺再到模型服務全棧升級:
總之,信息量爆炸,咱們一項一項拆解來看。
千億參數通義千問2.0來了先來看通義千問2.0。
這是上個月底,阿里云開源通義千問140億參數版本的Qwen-14B及其對話模型Qwen-14B-Chat后的最新動作。
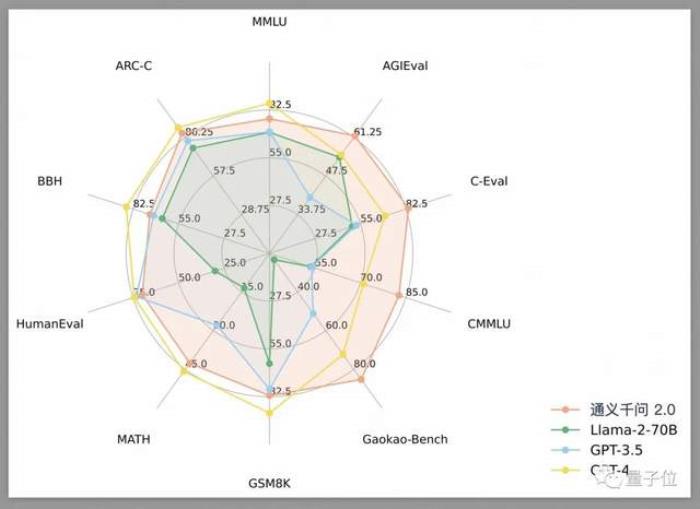
2.0版本的通義千問有了更龐大的參數,達到千億級參數規模,也“利用了更先進的對齊技術”,得到的成績是在10個權威測評中,全面超越GPT-3.5和LLaMA-2,也大有迎頭追趕GTP-4的架勢。
不僅是官網全面更新,多模態和插件都來了。

而且就在昨天,各個安卓應用市場已經上線了通義千問APP,大家玩兒起來更方便(iOS區小伙伴們再忍忍,聽說快了)。
我們也第一時間上手試玩了一番,看看2.0到底有怎樣的能力躍升。
我們直接來一道中文十級理解選擇題(手動狗頭)。
列出6個看起來長得很像的詞組,看看通義千問能不能從中找出不同:

一次成功!
通義千問2.0很果斷地發現了B選項中兩個詞組表達的不是同一個意思。
抱著“打起來”的心態,這個問題我們也丟給了ChatGPT(GPT-4)。
GPT-4發現了新的華點,但不知道為什么繞過了B選項,只指出了C選項的問題。

云棲大會現場,阿里云官方提到,“通用數學能力”的進步是通義千問2.0的一大亮點。
那我們也不客氣了:
這道題曾被知乎網友用來遍問中外大模型,結果Claude和NewBing紛紛翻車。
通義千問2.0這次經受住了考驗,給出的過程簡練,答案也沒有問題:

記憶能力與理解能力并駕齊驅,是大模型理解意圖的重要“考點”。
Let’s開啟一些多輪對話大戰,測測通義千問2.0能不能記住對話中的前言后語。
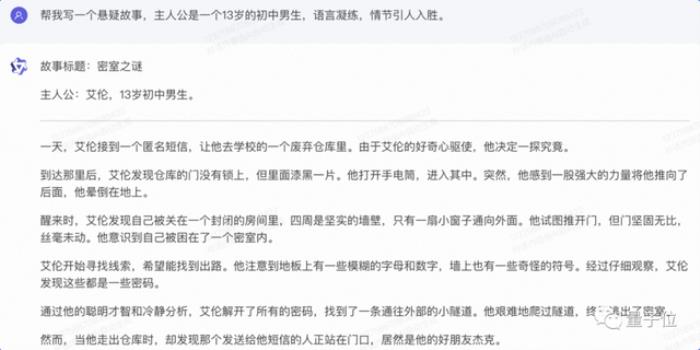
通義千問2.0很快搞出了一個密室探秘劇情,還給自己編出的懸疑故事起了個名字,叫做《密室之謎》。
但這不夠——我們提出新的要求,在故事里加個新的角色,女孩肉絲(Rose)。
可以看到,通義千問2.0沒有忘記原本的故事設定,還不是直接在段落中強行硬加,而是更改了部分劇情設定,來讓肉絲的出現更加自然:

整體來看,在復雜指令理解、文學創作能力、通用數學能力、知識記憶等方面,通義千問2.0確實實力大增,正面對上ChatGPT也并不遜色。
但通義大模型“全家桶”,還不止如此。
與通義千問2.0版本一同登場的,還有8個行業大模型,分別覆蓋金融、醫療、法律、編程、個性化創作等等領域。

行業大模型的主要特點,就是更容易在業務場景中被集成。
以通義靈碼為例,它就是給阿里云通義大模型投喂海量優秀開源代碼數據集和編程教科書后,調教出的智能編碼助手。
話不多說,依然是實測走起。
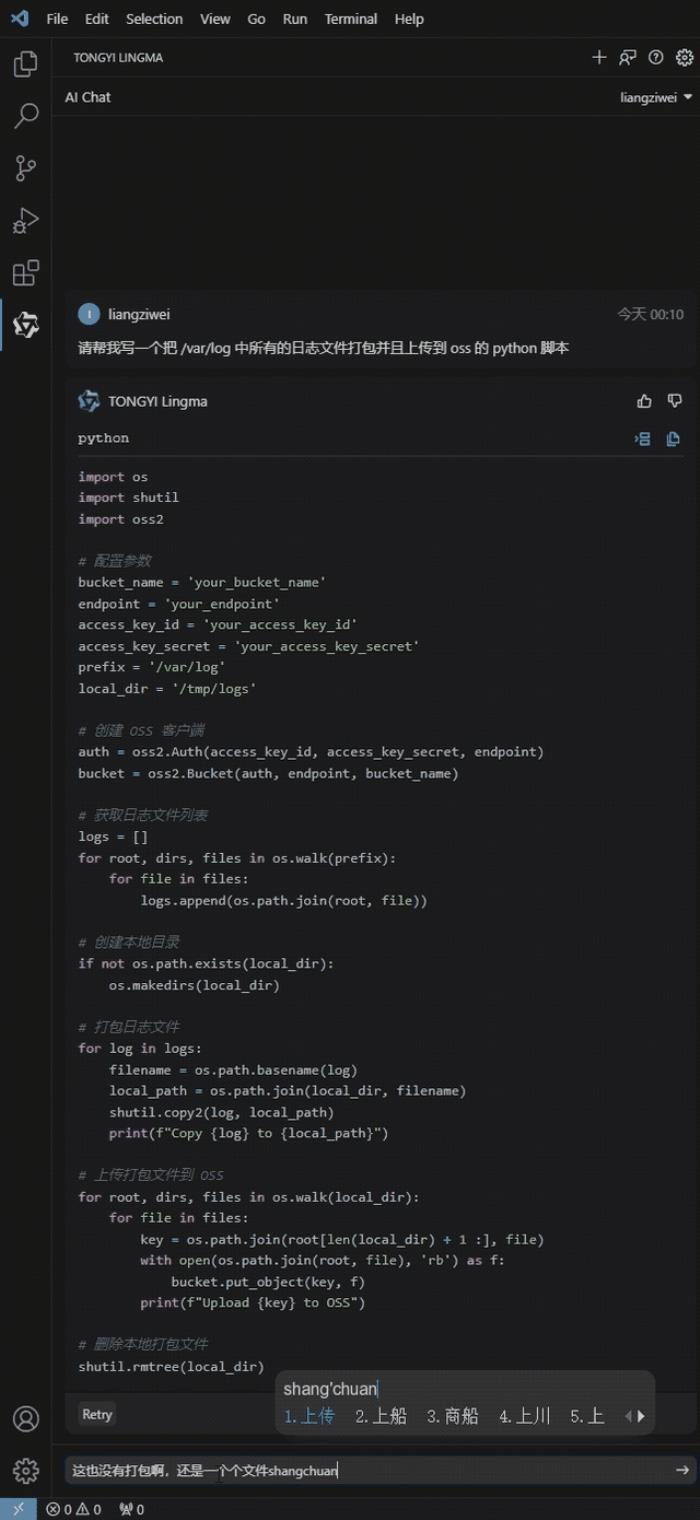
題目是日常運維工作中的一個常見需求:寫一個把/var/log中所有的日志文件打包并且上傳到oss的Python腳本。
一開始,通義靈碼雖然把代碼生成出來了,但漏掉了“打包”這個要求。不過在我們指出它的問題之后,它馬上把代碼修正了。
這波啊,是通義千問2.0打底,一籮筐大模型紛紛在云棲大會上秀出自己的肌肉了。

而在行業大模型發布背后,更關鍵的是,這次阿里云還把大模型應用落地的“秘籍”也公布了出來。
阿里云大模型應用秘籍公開現在,越來越多行業觀點認為,大模型競爭正在進入下一階段,主戰場正在由模型層轉向應用層。
為此,在基礎模型之外,阿里云此番另一項值得關注的發布,便是一站式大模型應用開發平臺——阿里云百煉。
基于百煉,開發者可在5分鐘內開發一款大模型應用,幾小時即可“煉”出一個企業專屬模型,開發者可把更多精力專注于應用創新。
模型方面,阿里云百煉集成了國內主流優質大模型,既有阿里云自研的通義系列大模型,也有Llama2、Baichuan、ChatGLM、姜子牙等第三方模型。另外,也支持用戶上傳自行訓練的模型。
有意思的是,百煉還提供了一個模型選型的參考榜單,綜合能力、推理能力、語言能力等等維度哪家模型更具優勢,一下就能整明白。
功能方面,百煉主要面向兩重需求:
針對需要訓練專屬模型的用戶,百煉提供從數據處理,到微調訓練,再到模型評估部署的一站式服務。支持SFT、LoRA等多種微調方式,所有訓練信息均能可視化顯示,訓練完成后還支持模型一鍵部署和能力測評。
針對需要開發大模型應用的用戶,百煉支持將大模型與實際業務系統結合構建Agent,提供靈活的應用集成能力。比如,插件中心提供了官方系統插件和用戶自定義插件,可以根據實際業務需要以插件的形式增強大模型的交互能力。
值得一提的是,在阿里云百煉上,還有一個“應用廣場”,提供了豐富的預置應用模板。
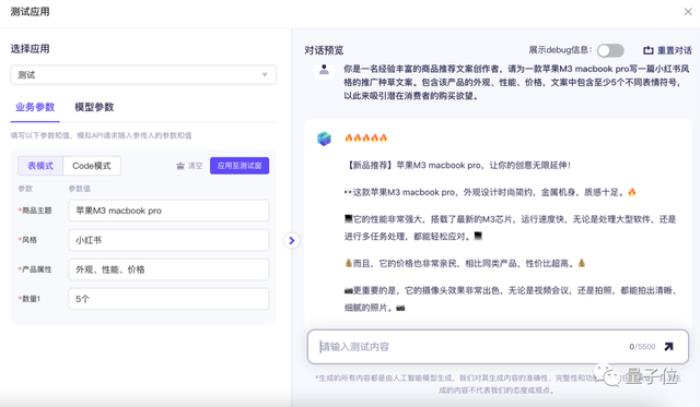
我們試著用“商品推廣文案生成”這個模板,簡單創建了一個生成小紅書種草文案的應用,效果是醬嬸的:
另外,在安全方面,阿里云為所有模型提供基礎安全套件。即,用戶無需任何操作,就能將安全能力集成和部署到自行開發的模型和應用程序中。
目前,央視網、朗新科技、亞信科技等早期用戶已在阿里云百煉上開發了專屬模型和應用。
朗新科技在云上訓練出電力專屬大模型,開發“電力賬單解讀智能助手”“電力行業政策解析/數據分析助手”,為客戶接待提效50%、降低投訴70%。
央視網則調教出了一個媒體行業大模型,提供內容創作輔助應用。相比通用模型,編輯人員對于生成內容的滿意度和采納率均有大幅提升。
值得關注的是,在加速應用落地的背后,作為大模型時代的“基礎設施”,阿里云人工智能平臺PAI也已全面升級:
PAI底層采用HPN 7.0新一代AI集群網絡架構,支持高達10萬卡量級的集群可擴展規模,超大規模訓練線性拓展效率大96%,超過業界水平。在大模型訓練任務中,同樣的效果可節省超50%算力資源,性能達到全球領先水平。
百川智能、智譜AI、零一萬物、昆侖萬維、vivo、復旦大學等頭部企業及機構目前均在阿里云上訓練大模型。
 “打造AI時代最開放的大模型平臺”
“打造AI時代最開放的大模型平臺”在AI 2.0階段,大模型步入第二篇章的當下,當主戰場從模型層轉向應用層,如今的兩大行業標桿,有著兩種鮮明的風格:
OpenAI靠API,Meta靠開源。
不過無論是何種路線,這兩家巨頭都在以自己的方式繁榮著生態。

為什么要發展大模型生態?
一方面,沒有應用層的發展,基礎模型的價值發揮就會嚴重受限。
另一方面,應用層和模型層的協同發展,生態系統中的各個參與者的競爭,帶來的效應能夠加速整個大模型圈層的提質與創新。
在云棲大會現場,周靖人也言辭懇切地明確表示,阿里云的目標不是只服務一類客戶,阿里云希望在AI時代,為各種各樣的企業提供支持,“幫助它們在擅長的領域去創業”。
提出目標后,要打造AI時代最開放大模型平臺的阿里云,具體是這么做的:
8月初,開源通義千問70億參數模型Qwen-7B;而后,基于Qwen-7B打造的大規模視覺語言模型Qwen-VL登場,支持圖像、文本、檢測框等多種輸入;9月底,新開源的模型參數量來到了140億,即Qwen-14B。
現在,延續一整套“國內大模型開源全系列”的味兒,阿里云又宣布將開源720億參數的Qwen-72B。這個版本開源后,它就是目前國內參數量最大的開源模型。

在更深一層的,阿里云攢局的AI模型開源社區魔搭ModelScope,去年剛發布,今年已經是開發者的常駐扎堆地。
啪啪幾個數據甩到眼前:一年時間,下載量1億+、AI開發者280萬+,模型總量2300+、……
更值得一提的是,即便已經做大、做強,魔搭社區還是有很值得的羊毛可薅。
魔搭為新用戶提供免費GPU算力100小時/人,目前已累計為開發者提供免費GPU算力3000萬小時+。

回到當下,大模型徹底改變傳統工作流的驚人能力,已然在千行百業中掀起新一輪的智能升級浪潮。
對于當局者,“百模大戰”的硝煙逐漸平息,現在已經來到了一個可以更加冷靜、客觀、理性挑選大模型的階段。
從大模型的三個要素——算力、模型和應用角度考慮,關鍵評價指標如今已經在各方動作中逐漸清晰:更具性價比的算力、更強大的模型能力、更繁榮的開發者生態。
以此為標準,以阿里云的整體布局而言,長期來看確實值得期待。
并且有“開源”這個選項加持,意味著在這個新時代里,不用完全把命運交到別人手中。
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
