

 新火種
2023-11-01
新火種
2023-11-01 

巨量模型時代,浪潮不做旁觀者:2457億,打造全球最大中文語言模型
戰鼓催征千嶂寒,陰陽交會九皋盤。
飛軍萬里浮云外,鐵騎叢中明月邊。
看到這首詩歌,有超過50%的人誤以為是人類的杰作
但其實,它出自巨量模型 源1.0
經過圖靈測試認證,源1.0 寫詩歌、寫對聯、生成新聞、續寫小說的能力已經讓人類的平均誤判率達到了50.84%。(超過30%即具備人類智能)
9月28日,浪潮人工智能研究院正式發布全球最大中文預訓練語言模型“源1.0”。歷時四個月研發,源1.0參數量已達2457億,約GPT-3的1.4倍。

中國工程院院士、浪潮首席科學家王恩東表示,源1.0巨量模型旨在打造更“博學”的AI能力,未來將聚合AI最強算力平臺、最優質的算法開發能力,支撐和加速行業智能轉型升級,以更具備通用性的智能大模型成就行業AI大腦。
“源1.0”定位中文語言模型,由5000GB中文數據集訓練而成。在國內,以中文語言理解為核心的大模型不在少數,參數規模均在億級以上,如悟道· 文源 26 億,阿里PLUG 270 億;華為&循環智能「盤古」1100億。相比之下,2457億的 源1.0 可以說是單體模型中絕對的王者。
更值得關注的是,源1.0是業界首個挑戰“圖靈測試”并且使平均誤判率超過50%的巨量模型。圖靈測試是判斷機器是否具有智能的最經典的方法。通常認為,進行多次測試后,如果人工智能讓平均每個參與者做出超過30%的誤判,那么這臺機器就通過了測試,并被認為具有人類智能。源1.0逼近通過圖靈測試,再次證明了大模型實現認知智能的潛力。
為何加入這股“浪潮”?
近幾年,巨量模型在人工智能領域大行其道,BERT、GPT-3、Switch Transformer、悟道2.0相繼問世,出道即巔峰,在產學各界掀起一陣陣巨浪。如今“巨量模型”一詞已經成功破圈,成為全民熱詞。那么,人工智能遭遇了哪些瓶頸,巨量模型又帶來了哪些可能性?
在會后采訪中,浪潮信息副總裁、AI&HPC產品線總經理劉軍表示,人工智能模型目前存在諸多挑戰,當前最首要的問題是模型的通用性不高,即某一個模型往往專用于特定領域,應用于其他領域時效果不好。

也就是說,面對眾多行業、諸多業務場景,人工智能需求正呈現出碎片化、多樣化的特點,而現階段的AI模型研發仍處于手工作坊式,從研發、調參、優化、迭代到應用,研發成本極高且難以滿足市場定制化需求。而訓練超大規模模型在一定程度上解決通用性問題,它可以被應用于翻譯,問答,文本生成等等,涵蓋自然語言理解的所有領域。
具體來說,從手工作坊式走向“工場模式”,大模型提供了一種可行方案:預訓練+下游微調”,大規模預訓練可以有效地從大量標記和未標記的數據中捕獲知識,通過將知識存儲到大量的參數中并對特定任務進行微調,極大地擴展了模型的泛化能力。同時大模型的自監督學習方法,使數據無需標注成為可能,在一定程度上解決了人工標注成本高、周期長、準確度不高的問題。
劉軍解釋說,大模型最重要的優勢是表明進入了大規模可復制的產業落地階段,只需小樣本的學習也能達到比以前更好的能力,且模型參數規模越大這種優勢越明顯,不需要開發使用者再進行大規模的訓練,使用小樣本就可以訓練自己所需模型,能夠大大降低開發使用成本。
現階段,零樣本學習和小樣本學習是最能衡量巨量模型智能程度的兩項測試。而源1.0在CLUE基準上刷新了多項任務的SOTA。
官方數據顯示:源1.0在零樣本榜單中,以超越第二名18.3%的絕對優勢遙遙領先。
l 在文獻分類、TNEWS,商品分類、OCNLIF、成語完型填空、名詞代詞關系6項任務中獲得冠軍。
l 在小樣本榜單中,文獻分類、商品分類、文獻摘要識別真假、名詞代詞關系4項任務中獲得冠軍。
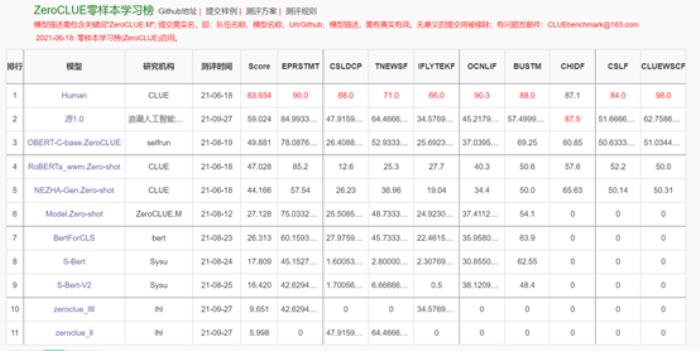
https://www.cluebenchmarks.com/zeroclue.html
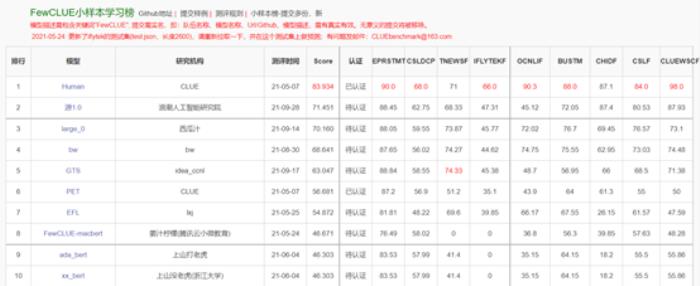
https://www.cluebenchmarks.com/fewclue.html
"面對產業AI化挑戰,巨量模型在多任務泛化及小樣本學習上突出能力,以及其探索深度學習的極限和實現通用智能的可能性,浪潮前瞻性的做出了開發巨量模型的重要決策"。劉軍表示,浪潮源1.0大模型只是一個開始,未來源1.0將面向學術研究單位和產業實踐用戶進行開源、開放、共享,降低巨量模型研究和應用的門檻,推進AI產業化和產業AI化的進步,
2457億 是如何煉成的?
大模型需要“大數據+大算力+強算法”三駕馬車并駕齊驅,而對于大部分企業和機構來說,其中任意一項的研發投入都是沉重的負擔,尤其是算力成本。比如1750億參數的GPT-3單次訓練需要 355 張 GPU,花費大約 2000 萬美元。所以在煉大模型浪潮中,我們只看到了全球頂級的科技企業和科研機構的身影,而浪潮本潮也在其中。
浪潮 源1.0 在算力、算法和數據三個方面都做到了超大規模和巨量化。
首先是數據,浪潮創建了 5000GB 大規模的中文數據集,將近5年互聯網上的內容濃縮成了2000億詞。2000億詞是什么概念?假如人一個月能讀十本書,一年讀一百本書,讀 50 年,一生也就讀 5000 本數,一本書假如 20 萬字,加起來也就 10 億字。也就是說,人類窮極一生也讀不完2000億詞。
在大數據時代,比數據量更珍貴的數據質量。作為AI的底層燃料,模型對數據集質量提出了更高的要求。為此浪潮創新中文數據集生成方法,研制高質量文本分類模型,收集并清洗互聯網數據過程中,有效過濾了垃圾文本,最終生成5000GB數據集可以說具備了夠大、夠真實、夠豐富的特點。

在算法層面,源1.0大模型使用了4095PD(PetaFlop/s-day)的計算量,獲得高達2457億的參數量,相對于GPT-3消耗3640PD計算量得到1750億參數,計算效率大幅提升;在算力層面,源1.0通過算法與算力協同優化,使模型更利于GPU性能發揮,極大的提升了計算效率,實現業界第一訓練性能的同時實現業界領先的精度。
談起浪潮很多人還是停留在初級的印象,這是一家老牌硬件廠商,每年服務器市場占有率在全球范圍內高居榜首。其實浪潮也一直活躍在AI前沿方向,自2018年成立浪潮人工智能研究院以來,其異構加速計算、深度學習框架、AI算法等領域已經戰績頗豐。例如,浪潮先后推出了深度學習并行計算框架Caffe-MPI、TensorFlow-Opt、全球首個FPGA高效AI計算開源框架TF2等;此外,在全球頂級的AI賽事上已累計獲得56個MLPerf全球AI基準測試冠軍。有了這些深厚的AI功底,浪潮在四個月內推出全球最大巨量模型不難理解了.
對于源1.0,業內專業人士評價稱,其在巨量數據、超大規模分布式訓練的擴展性、計算效率、巨量模型算法及精度提升等等難題上都有所創新和提升。
源1.0 更“博學”了嗎?
圖靈測試一直被認為是人工智能學術界的”北極星“,也是檢驗機器是否具有人類智能的唯一標準。以GPT-3為代表的巨量模型出現后,機器開始在多項任務中逼近圖靈測試,但直到源1.0之前,沒有任何大模型突破30%的關卡。
在“源1.0”的圖靈測試中,將模型生成的對話、小說續寫、新聞、詩歌、對聯與由人類創作的同類作品進行混合并由人群進行分辨,測試結果表明,人群能夠準確分辨人與“源1.0”作品差別的成功率已低于50%。
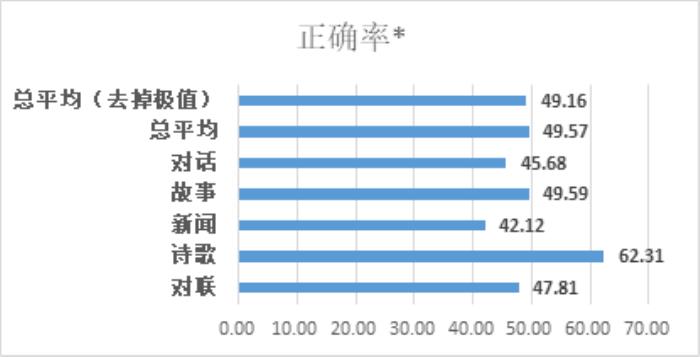
如圖,受訪者的平均誤判率為50.84%,在新聞生成領域誤判率高達57.88%。
而拋開數據,源1.0的詩歌、對聯的作品確實讓人驚艷
五湖四海皆春色,三江八荒任我游
春來人入畫,夜半月當燈
和風吹綠柳,細雨潤青禾
三江顧客盈門至,四季財源滾滾來.
疑是九天有淚,
為我偷灑。
滴進西湖水里,
沾濕一千里外的月光,
化為我夢里的云彩。
巨量模型的潛力
煉大模型熱潮的興起,離不開谷歌微軟、OpenAI、智源研究院等全球頂級科技企業和研發機構的追逐和熱捧,在它們看來,巨量模型代表了實現通用人工智能最具潛力的路徑,代表了當前傳統產業實現智能化轉型的新機遇.
而這次,浪潮重磅發布中文單體大模型源1.0,通過圖靈測試和小樣本學習能力再次印證了業界對超大模型潛力的普遍期望. 前者為模型推理\走向認知智能提供了可能性,后者降低了不同場景的適配難度,提升了模型的泛化應用能力。相信未來這股"浪潮"還會越來越洶涌.
雷鋒網雷鋒網雷鋒網

相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
