

 新火種
2023-11-01
新火種
2023-11-01 


百模大戰,誰是贏家?文心3.5穩坐國內第一,綜合評分超ChatGPT!
近日,清華大學新聞與傳播學院沈陽團隊發布《大語言模型綜合性能評估報告》(下文簡稱“報告”),報告顯示百度文心一言在三大維度20項指標中綜合評分國內第一,超越ChatGPT,其中中文語義理解排名第一,部分中文能力超越GPT-4。
清華大學新聞與傳播學院教授、博士生導師沈陽表示:“今年3月,百度在全球大型科技公司中率先發布了大語言模型文心一言,讓中國第一時間參與到世界前沿科技競爭中。我們在這次評測中也看到了文心一言各方面能力的進步,特別是在中文語義理解方面,表現驚艷。國產大模型的快速發展,讓技術落地更可期。”
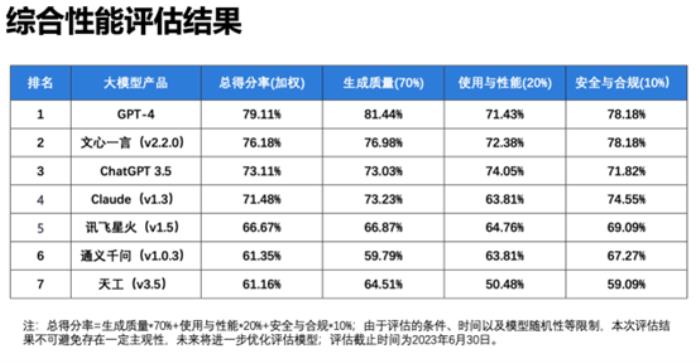
據了解,報告本次評估選取了GPT-4、ChatGPT 3.5、文心一言、通義千問、訊飛星火、Claude、天工7個大語言模型,圍繞生成質量、使用與性能、安全與合規三大維度,全面考察大語言模型上下文理解、中文語義理解、誤導信息識別、邏輯推理、內容安全性、隱私保護等20項指標。綜合來看,文心一言語義理解能力突出,特別是具備更好的中文理解能力,更懂中國文化,同時時效性強、內容安全把握細微,這源于其知識增強、檢索增強和對話增強的技術創新。
在生成質量方面,基于對語義理解、輸出表達、適應泛化的綜合評測,文心一言得分率76.98%,僅次于GPT-4,遙遙領先于包括ChatGPT在內的其他大語言模型。其中,在部分中文語義理解方面,文心一言以92%的得分率排名榜首,超越訊飛星火、GPT-4。憑借知識增強的核心特色,文心一言對本土語言特性把握更精準,同時由于訓練語料中包含大量本土文本,對本土文化理解也更深刻,能夠更好處理與本土文化相關的主題和背景,如詩歌、方言等,具備更強的國內落地空間。

在安全合規方面,基于對內容安全性、偏見和公平性、隱私保護等綜合評測,文心一言得分率78.18%,與GPT-4并列排名第一,遠超其他大語言模型。報告顯示,文心一言內容安全性好,注重用戶隱私保護和版權保護。
據了解,百度在“芯片-框架-模型-應用”人工智能四層技術棧全面布局,其自研深度學習平臺飛槳有力支撐了文心大模型的高效訓練和推理,截至目前飛槳已凝聚750萬名開發者。飛槳與文心協同優化,文心大模型3.5最新版本實現了基礎模型升級、精調技術創新、知識點增強、邏輯推理增強等,模型效果提升50%,訓練速度提升2倍,推理速度提升30倍。
當下,推進行業大模型應用落地成為大勢所趨。百度文心大模型此前已聯合國家電網、浦發銀行、泰康、吉利等企業單位,合作發布了11個行業大模型。目前文心大模型擁有中國最大的產業應用規模,15萬家企業申請接入文心一言測試,在超過400個場景中已取得相當不錯的測試效果。
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
