

 新火種
2023-10-31
新火種
2023-10-31 


對戰6億用戶競技手游:聚焦復雜游戲中的多智能體博弈

2021年11月,全球首屆“ AI《球球大作戰》:Go-Bigger多智能體決策智能挑戰賽”已正式開賽。作為面向全球技術開發者和在校學生的科技類競賽活動,本次比賽旨在推動決策智能相關領域的技術人才培養,打造全球領先、原創、開放的決策AI開源技術生態。
在比賽之際,雷鋒網&AI科技評論對話了本次競賽的核心設計團隊成員劉宇和周航,他們二人,一個為商湯科技研究總監,也是OpenDILab項目負責人;一個為前星際職業選手iA,目前任商湯決策智能游戲AI組高級研究員;殊途而同歸,他們如何通過 「游戲 × 決策」方式走到一起,他們會更看中什么樣的“策略高手”?
在現實之外,還有另一個世界,游戲世界。它將人情世故、弱肉強食、情義背叛、謀略運籌挪于方寸之間,功成名就,皆在俯仰間。以游戲世界之有涯,演繹人際種種浮沉。古人制蠱王,今人造腦王,科技的進步,將對抗的秘密搬上臺面。
而今這場競技,被命名為Go-Bigger多智能體決策智能挑戰賽。比賽由OpenDILab主辦,上海人工智能實驗室作為學術指導,商湯決策智能團隊和巨人網絡等多元化組織聯合打造。靈感來自于巨人網絡自主研發的一款超火爆休閑競技手游《球球大作戰》,多方共同開啟全球首屆AI版《球球大作戰》。

Go-Bigger游戲環境:https://github.com/opendilab/GoBigger
AI球球大作戰采用了類似《球球大作戰》的物理引擎設計,具有相對較大的地圖,球球具有分裂、吐孢子、中吐等高階動作空間,但是提供了適合強化學習或行為樹AI編寫的抽象接口。
劉宇說到,“Go-Bigger并不像星際爭霸或Dota2這種重型游戲環境,我們對它的定位是人人可以參加的中型游戲AI競技環境,推動學術界關注更大一些的決策問題。相比學術界用的最多的Atari、Mojoco、SMAC要大不少,但又可以在小型的實驗室中完成——一臺機器、一塊GPU就能訓練起來。它面向大眾、學生、研究員,更適合用 「學術比賽」來描述它。”
從參與籌辦比賽的各方來看,學術價值,在Go-Bigger身上非常明顯。它由上海人工智能實驗室作為學術指導,商湯科技、巨人網絡、上汽集團人工智能實驗室聯合主辦,全球高校人工智能學術聯盟、浙江大學上海高等研究院、上海交通大學清源研究院聯合協辦,OSCHINA、深度強化學習實驗室作為支持。
從產業出發,關注底層技術,并進一步攏合各大高校和實驗室,其實就是商湯的原創基因。
一、Go-Bigger比拼決策戰術
周航和劉宇都說到,“球球大作戰的門檻很低,但是上限很高。”
與風靡全球的agar.io、《球球大作戰》等游戲類似,在Go-Bigger中,每局比賽十分鐘,大球吃掉小球而獲得更大重量和體積,但同時要避免被更大的球吃掉。當球達到足夠大時,玩家(AI)可使其分裂或融合,和同伴完美配合來輸出博弈策略。每個隊伍都需和其他隊伍對抗,總重量更大的團隊獲勝。
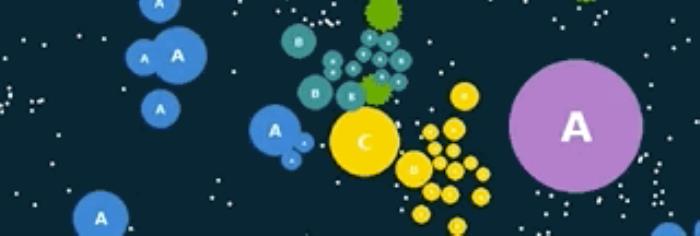
Go-Bigger游戲環境演示圖
游戲中有四類小球,分別為分身球、孢子球、食物球、荊棘球,挑戰不同決策路徑。
分身球是玩家在游戲中控制移動或者技能釋放的球,可以通過覆蓋其他球的中心點來吃掉比自己小的球。
孢子球由玩家的分身球發射產生,會留在地圖上且可被其他玩家吃掉。
食物球是游戲中的中立資源,其數量會保持動態平衡。如玩家的分身球吃了一個食物球,食物球的重量將被傳遞到分身球。
荊棘球也是游戲中的中立資源,其尺寸更大、數量更少。如玩家的分身球吃了一個荊棘球,荊棘球的大小將被傳遞到分身球,同時分身球會爆炸并分裂成多個(10個)分身。此外,荊棘球可通過吃掉孢子球而被玩家移動。

分身球

孢子球,食物球
荊棘球
此外,Go-Bigger還包含一系列與《球球大作戰》類似的游戲規則:
球重量越小,移動速度越快;
分身更多可以快速發育,但自身重量被分散,面臨被吃的風險。
每個玩家的總重量會隨著時間緩慢衰減,體重越大,衰減速度越大在戰斗階段,分裂后的玩家需要盡快合球,因此,同一隊伍中不同球球的配合尤為關鍵。
同隊伍玩家之間不會完全吞噬(會保留最后一個球)。
由于這種規則設置,球球在不同發展階段,策略各不相同。
在球球發育前期,重量太小無法分裂,一邊吃食物完成原始積累,一邊防御被吃,就催化了團隊合作--多球行動。
比如,當自己進食足夠多,并達到分身程度時,將小分身喂給隊友,只留一個,同伴和自己都會完成第一次原始積累,并增加團隊整體重量。
隨著大家爭相完成原始積累,比賽進入中期。防御轉為攻擊,暗爭轉為明爭。而此時,持久戰還是速度戰、先滅大還是先滅小、霸屏攻擊還是輕騎后抄,不同策略組合將游戲推向高潮。
距離,方向,速度以及分身后的密度成為影響獲勝關鍵。
其中一種攻擊策略為先滅小而后搏大,大球率先攻擊發育不良的球,合成大球,隨后尋找實力略弱的大球,判斷距離、分身快速逼近、近身后合球鯨吞。幾輪下來,大球進入排行榜頭列,為后續決戰做好準備。
隨著游戲進入后期,戰場上的玩家也所剩無幾,實力相當的大球決戰,成為賽點關鍵!
首先,大球的移動速度非常慢,選擇時機分身移動,快速移動并合成干掉對方,成為大球玩家心中既心照不宣,又秘而不發的護身之法。你死我亡,弱肉強食,生命法則向是如此。
但與此同時,作戰的另一機制——自我衰亡被觸發。
大球的體重并不是一成不變的,而是以一個相當快的速度流失體重,體重衰減率是每秒鐘千分之二。因此,游戲進入下一階段——霸屏團隊的優勢維持、其它團隊的反擊。
由于霸屏團隊體重流失速度相當快,如果只是用常規的攻擊手段,增加的體重往往不能和流失的體重相抵。而同時,大球的移動速度十分緩慢,攻擊效率十分低下,多數大球團隊會采用多分身模式攻擊。
因為已經是優勢團隊,即便多分身,其它團隊也往往不能對多分身造成威脅,因此大球往往以相對高的速度地毯式掃蕩。
縱觀決戰之勢,無論是大球燃燒心火,擊潰其身;還是分身求勝,蠶食殆盡,往往并不隨心所欲。在對抗同時,作戰時間所剩無幾。
此外,還有多少小球蟄伏暗處,醞釀反擊,在最后階段逆轉局勢,并非新事。
在萌萌的小球之內,涌動著規則和博弈的暗流。周航回應道,這就是Go-Bigger門檻很低,但是上限很高的原因。
“游戲環境非常簡單直觀,因為大家都玩過類似的游戲,像大魚吃小魚、剪刀石頭布、圍棋。它們都有很直觀的名字,都用簡單的環境系統構建出博弈場景。但不同的是,Go-Bigger涉及到多智能體的配合和對抗,會有更高的決策復雜度。”
二、游戲環境如何設計
人工智能現在已經廣泛應用在感知優化場景,但是想讓模型具有真正的智能,則需要將其落實到一些需要進行決策的場景。
游戲,則是決策智能(DI)天然的訓練場。
如果將一個游戲環境比作一個小社會,那么不同的游戲角色則是生活其中的人類。只有人類數量足夠多,才足以反映其中的群體關系,并進一步模擬人類社會的生活圖景。因此,在復雜游戲中的多智能體博弈,成為推動決策智能發展的關鍵。
Go-Bigger涉及多智能體博弈,不可避免要權衡同一團隊中的個體行動與合作行動、不同團隊間的合作與競爭、表征和交換與其它智能體的環境信息。但要從零開始實現上述算法和訓練流程非常復雜,決策智能框架DI-engine大大簡化了設計過程。
其內部已經集成了支持多智能體的DQN算法實現和一系列相關訣竅,以及玩家自我對戰和對抗機器人的訓練組件,只需實現相應的環境封裝,神經網絡模型和訓練主函數即可。
此外,Go-Bigger支持RL環境,提供了三種交互模式。
為幫助用戶在強化學習領域的多智能體策略學習,Go-Bigger提供了符合gym.Env標準的接口供其使用。在一局游戲中,Go-Bigger默認設置含有20個狀態幀和5個動作幀。每個狀態幀都會對當前地圖內所有單位進行仿真和狀態處理,而動作幀會在此基礎上,附加對單位的動作控制,即改變單位的速度、方向等屬性,或使單位啟用分裂、發射或停止等技能。
為了更方便地對環境進行探索,Go-Bigger還提供了必要的可視化工具。在與環境進行交互的時候,可以直接保存本局包含全局視角及各個玩家視角的錄像。此外,Go-Bigger提供了單人全局視野、雙人全局視野、單人局部視野三種人機交互模式,使得用戶可以快速了解環境規則。

單人全局視野、雙人全局視野、單人局部視野
可視化除了方便用戶設計智能體的決策路徑,還將智能體的決策進化提供一個參考。
目前基于強化學習等方法的決策智能,主要還是在學習「狀態」到「動作」的映射,離可解釋的、因果關系的、可互動的決策還有很遠距離。但游戲本身的可視化形式,會直接展示智能體的策略。
整個游戲環境的搭建,不僅涉及到大的封裝模塊,還有小的動作設計。劉宇說到,我們在設計這個引擎的時候,不僅要兼顧它是否有趣(可視化、難度低),還要考慮它對研究者來說是否有用(動作歧義、公平)。
在復雜的游戲環境中,如何做到公平性,保證所有智能體從同一起點進化,并演化出最多的決策路徑,除了球球背后的參賽選手出奇斗勇,還要有公平的評測系統--天梯系統。參賽選手只需基于大賽提供的接口,給出智能體在每一幀的動作,最后將代碼以及相關模型或文件提交即可加入測試天梯。OpenDILab團隊將使用選手提供的環境及代碼進行指定競賽的模型測試工作,決出最后的贏家!
三、決策智能研究剛剛上路
在Go-Bigger游戲中,設計了球球對抗時間、成長加速度、分裂、消失、衰亡等約束條件,它們其實廣泛存在于現實世界,比如人的生命周期,微觀生物學中細胞免疫等。
天然擁有很高的社會擬合度,是用游戲做決策智能研究的優勢。
劉宇說,Go-Bigger項目只想做好一件事,就是想通過打造一款類似于球球大作戰和AGAR這樣家喻戶曉的游戲,讓大家先把游戲AI和決策智能聯系起來,且人人可上手。
“現在Go-Bigger希望做的,其實非常像CV領域的ImageNet。”
十年來,計算機視覺一直是最火爆的領域。但是CV是如何發展起來的,“其實就是開源了更大的數據集。”
劉宇說到,“在ImageNet比賽之前,數據集都非常小,研究員很難定義產業界真正需要的算法問題。但ImageNet的推出,為當時的技術帶來了挑戰,隨著GPU的算力提升,越來越多的人涌入到CV領域,成就了現在深度學習+計算機視覺的蓬勃發展。”
現在決策智能領域的大多數工作者,很難接觸到像星際、DOTA2這樣的資源,在相對較理想的小數據集和仿真環境中做實驗、發論文,是學術研究的常態。
“而決策智能將走向何方,其實就是從訓練平臺和仿真環境兩個方向發力。我們希望在保持現有資源能夠接觸的情況下,能讓決策智能更接近真實場景,并逐漸推動行業中更多的平臺開源。”劉宇說到。
決策智能的研究剛剛上路,首先是數據的問題,其次是標準化的問題。
目前,決策智能的標準化難題是三塊:
一個是環境觀測的標準化
二個是動作空間的標準化
三個是算法工作流的標準化
“CV標準化做得好,因為這里面所有的數據都可以用非常規整的tensor來表示,像PyTorch、 TensorFlow。”
但在決策智能領域,會涉及到多模態的輸入,比如空間信息(Spatial info)、實體信息(Entity info)、Scalar info(標量信息)。“難點是將所有模態都統一到一個數據格式下。”劉宇說到,“目前一些做法是將各種模態的數據統一到一個encoder,讓它們映射到同一個observation space(觀測空間)。”
有了狀態空間后,就需要決策做什么動作。
比如,強化學習領域很多算法很難同時支持離散和連續兩種動作空間。而真實場景里還有更復雜的動作空間,比如前后依賴的動作空間、序列的動作空間,跟馬爾可夫鏈性質不太相關的或者違背的動作空間。“這些動作空間如何大一統到一個訓練的平臺和一個訓練流里,也是非常難的問題。”
“我們希望通過算法設計出新的head(決策智能訓練網絡的頭),后期只需要做一些plug in(插件)的工作,幾乎能夠適配所有的算法。”
第三塊是算法的標準化。各種算法之間的差異性非常大且難以抽象,如果強行把所有算法兼容到一套框架內,代碼會非常冗余。“我們現在想要從計算流的角度思考強化學習的優化過程,把強化學習里所有原子模塊拆分,類似PyTorch里operator,那么以后只需要拼算法積木,或者研發一個新的強化學習算法。”
這件事本身是很長期主義的一件事,Go-Bigger只是一個開始。
劉宇說,“我們希望用5年時間,從工具和學術問題定義兩個方面推動決策智能落地,能夠讓平臺、算法集、生產的工具鏈適配到幾乎所有決策智能行業應用上,將行業和學術的各自為陣,變成欣欣向榮。”
比賽持續到明年4月,那時,“我們期待所有選手百家爭鳴,能夠定義出新的問題,也會設計出更多樣性的算法,既有純強化學習的,也有結合硬編碼和強化學習的。當然,我們希望訓練出的AI不僅能處理好輸贏,還能兼顧到游戲的擬人性。”
如今,全球首屆“AI《球球大作戰》:Go-Bigger多智能體決策智能挑戰賽”已正式開賽。作為面向全球技術開發者和在校學生的科技類競賽活動,本次比賽旨在推動決策智能相關領域的技術人才培養,打造全球領先、原創、開放的決策AI開源技術生態。協作、博弈、對抗,精彩紛呈,歡迎前來挑戰!
比賽詳情請見:https://mp.weixin.qq.com/s/1hVFFWBVSUx-BT6Fnn_sMA

相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
