

 新火種
2023-10-28
新火種
2023-10-28 


論文投Nature先問問GPT-4!斯坦福實測5000篇一半意見跟人類評審沒差別
GPT-4有能力做論文評審嗎?
來自斯坦福等大學的研究人員還真測試了一把。
他們丟給GPT-4數千篇來自Nature、ICLR等頂會的文章,讓它生成評審意見(包括修改建議啥的),然后與人類給的意見進行比較。
結果發現:
GPT-4提出的超50%觀點與至少一名人類評審員一致;
以及超過82.4%的作者都發現GPT-4給的意見很有幫助。
那么,這項研究究竟能給我們帶來何種啟示?
結論是:
高質量的人類反饋仍然不可替代;但GPT-4可以幫助作者在正式同行評審前改進初稿。

具體來看。
實測GPT-4論文評審水平
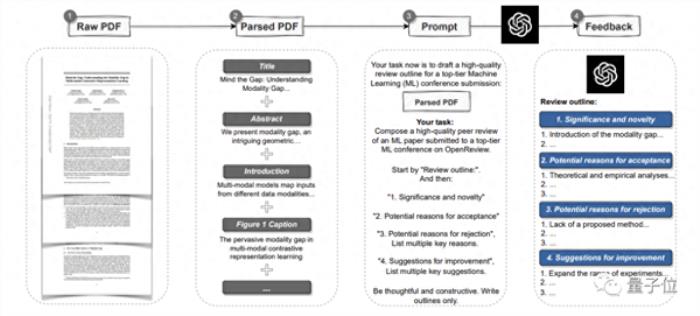
為了證明GPT-4的潛力,研究人員首先用GPT-4創建了一個自動pipeline。
它可以解析一整篇PDF格式的論文,提取標題、摘要、圖表、表格標題等內容來構建提示語。
然后讓GPT-4提供評審意見。
其中,意見和各頂會的標準一樣,共包含四個部分:
研究的重要性和新穎性、可以被接受的潛在原因或被拒絕的理由以及改進建議。
具體實驗從兩方面展開。
首先是定量實驗:
讀已有論文,生成反饋,然后與真實人類觀點系統地比較出重疊部分。
在此,團隊從Nature正刊和各大子刊挑選了3096篇文章,從ICLR機器學習會議(包含去年和今年)挑選了1709篇,共計4805篇。
其中,Nature論文共涉及8745條人類評審意見;ICLR會議涉及6506條。
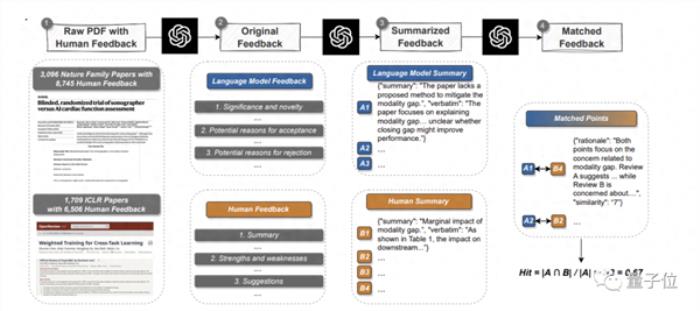
GPT-4給出意見之后,pipeline就在match環節分別提取人類和GPT-4的論點,然后進行語義文本匹配,找到重疊的論點,以此來衡量GPT-4意見的有效性和可靠度。
結果是:
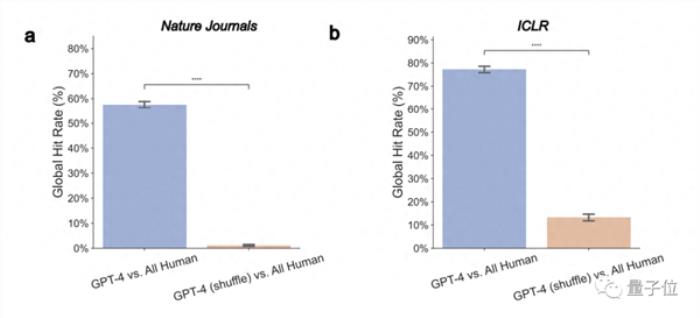
1、GPT-4意見與人類評審員真實意見顯著重疊
整體來看,在Nature論文中,GPT-4有57.55%的意見與至少一位人類評審員一致;在ICLR中,這個數字則高達77.18%。
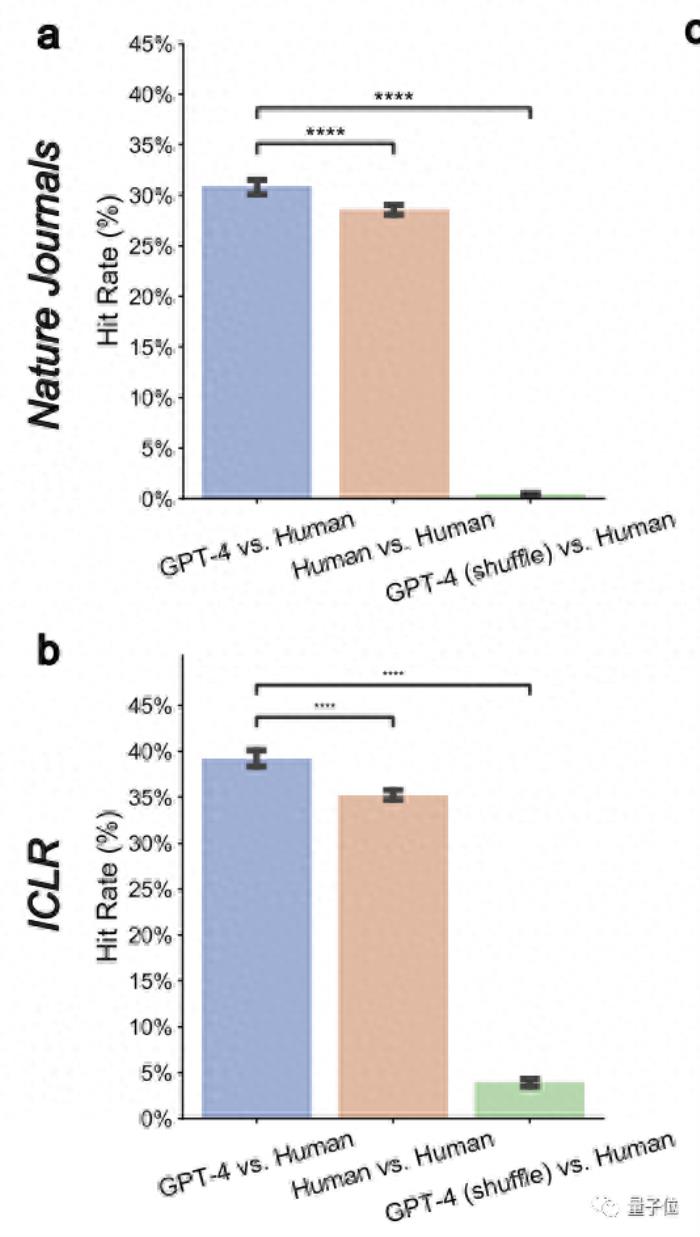
再進一步仔細比較GPT-4與每一位評審員的意見之后,團隊又發現:
GPT-4在Nature論文上和人類評審員的重疊率下降為30.85%,在ICLR上降為39.23%。
但這與兩位人類審稿人之間的重疊率相當:
人類在Nature論文上的平均重疊率為28.58%;在ICLR上為35.25%。
此外,他們還通過分析論文的等級水平(oral、spotlight、或是直接被拒絕的)發現:
對于水平較弱的論文來說,GPT-4和人類審稿人之間的重疊率更高,可以從上面的30%多升到近50%。
這說明,GPT-4對水平較差的論文的鑒別能力很高。
作者也因此表示,那些需要更實質性修改才能被接收的論文有福了,大伙兒可以在正式提交前多試試GPT-4給出的修改意見。
2、GPT-4可以給出非通用反饋
所謂非通用反饋,即GPT-4不會給出一個適用于多篇論文的通用評審意見。
在此,作者們衡量了一個“成對重疊率”的指標,結果發現它在Nature和ICLR上都顯著降低到了0.43%和3.91%。
這說明GPT-4是有針對性的。
3、能夠在重大、普遍問題上和人類觀點一致
一般來說,人類反饋中較先出現的意見以及多個評審員都提及的意見,最可能代表重要、普遍的問題。
在此,團隊也發現,LLM更有可能識別出多個評審員一致認可的常見問題或缺陷。
也就是說,GPT-4在大面上是過得去的。
4、GPT-4給的意見更強調一些與人類不同的方面
研究發現,GPT-4評論研究本身含義的頻率是人類的7.27倍,評論研究新穎性的可能性是人類的10.69倍。
以及GPT-4和人類都經常建議進行額外的實驗,但人類更關注于消融實驗,GPT-4更建議在更多數據集上試試。
作者表示,這些發現表明,GPT-4和人類評審員在各方面的的重視程度各不相同,兩者合作可能帶來潛在優勢。
定量實驗之外是用戶研究。
在此共包括308名來自不同機構的AI和計算生物學領域的研究員,他們都在本次研究中上傳了各自的論文給GPT-4進行評審。
研究團隊收集了他們對GPT-4評審意見的真實反饋。
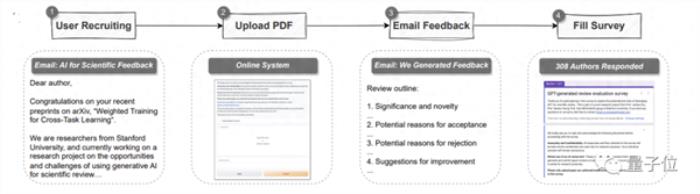
總體而言,超過一半(57.4%)的參與者認為GPT-4生成的反饋很有幫助,包括給到一些人類想不到的點。
以及82.4%的調查者認為它比至少一些人類評審員的反饋更有益。
此外,還有超過一半的人(50.5%)表示,愿意進一步使用GPT-4等大模型來改進論文。
其中一人表示,只需要5分鐘GPT-4就給出了結果,這個反饋速度真的非常快,對研究人員改善論文很有幫助。
當然,作者指出:
GPT-4也有它的局限性。
最明顯的是它更關注于“整體布局”,缺少特定技術領域(例如模型架構)的深度建議。
所以,如作者最后總結:
人類評審員的高質量反饋還是不可或缺,但大家可以在正式評審前拿它試試水,彌補遺漏實驗和構建等方面的細節。
當然,他們也提醒:
正式評審中,審稿人應該還是獨立參與,不依賴任何LLM。
一作都是華人
本研究一作共三位,都是華人,都來自斯坦福大學計算機科學學院。

他們分別是:
梁偉欣,該校博士生,也是斯坦福AI實驗室(SAIL)成員。他碩士畢業于斯坦福電氣工程專業,本科畢業于浙江大學計算機科學。Yuhui Zhang,同博士生在讀,研究方向為多模態AI系統。清華本科畢業,斯坦福碩士畢業。曹瀚成,該校五年級博士在讀,輔修管理科學與工程,同時加入了斯坦福大學NLP和HCI小組。此前畢業于清華大學電子工程系本科。

相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
