

 新火種
2023-10-28
新火種
2023-10-28 


你的GPU能跑Llama2等大模型嗎?用這個開源項目上手測一測
你的 GPU 內存夠用嗎?這有一個項目,可以提前幫你查看。
在算力為王的時代,你的 GPU 可以順暢的運行大模型(LLM)嗎?
對于這一問題,很多人都難以給出確切的回答,不知該如何計算 GPU 內存。因為查看 GPU 可以處理哪些 LLM 并不像查看模型大小那么容易,在推理期間(KV 緩存)模型會占用大量內存,例如,llama-2-7b 的序列長度為 1000,需要 1GB 的額外內存。不僅如此,模型在訓練期間,KV 緩存、激活和量化都會占用大量內存。
我們不禁要問,能不能提前了解上述內存的占用情況。近幾日,GitHub 上新出現了一個項目,可以幫你計算在訓練或推理 LLM 的過程中需要多少 GPU 內存,不僅如此,借助該項目,你還能知道詳細的內存分布情況、評估采用什么的量化方法、處理的最大上下文長度等問題,從而幫助用戶選擇適合自己的 GPU 配置。
項目地址:https://github.com/RahulSChand/gpu_poor
不僅如此,這個項目還是可交互的,如下所示,它能計算出運行 LLM 所需的 GPU 內存,簡單的就像填空題一樣,用戶只需輸入一些必要的參數,最后點擊一下藍色的按鈕,答案就出來了。
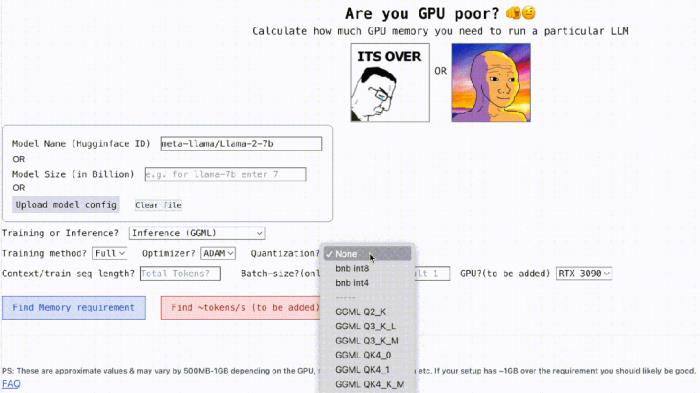
交互地址:https://rahulschand.github.io/gpu_poor/
最終的輸出形式是這樣子的:
{ "Total": 4000, "KV Cache": 1000, "Model Size": 2000, "Activation Memory": 500, "Grad & Optimizer memory": 0, "cuda + other overhead": 500}至于為什么要做這個項目,作者 Rahul Shiv Chand 表示,有以下原因:
在 GPU 上運行 LLM 時,應該采用什么的量化方法來適應模型;
GPU 可以處理的最大上下文長度是多少;
什么樣的微調方法比較適合自己?Full? LoRA? 還是 QLoRA?
微調期間,可以使用的最大 batch 是多少;
到底是哪項任務在消耗 GPU 內存,該如何調整,從而讓 LLM 適應 GPU。
那么,我們該如何使用呢?
首先是對模型名稱、ID 以及模型尺寸的處理。你可以輸入 Huggingface 上的模型 ID(例如 meta-llama/Llama-2-7b)。目前,該項目已經硬編碼并保存了 Huggingface 上下載次數最多的 top 3000 LLM 的模型配置。
如果你使用自定義模型或 Hugginface ID 不可用,這時你需要上傳 json 配置(參考項目示例)或僅輸入模型大小(例如 llama-2-7b 為 70 億)就可以了。
接著是量化,目前該項目支持 bitsandbytes (bnb) int8/int4 以及 GGML(QK_8、QK_6、QK_5、QK_4、QK_2)。后者僅用于推理,而 bnb int8/int4 可用于訓練和推理。
最后是推理和訓練,在推理過程中,使用 HuggingFace 實現或用 vLLM、GGML 方法找到用于推理的 vRAM;在訓練過程中,找到 vRAM 進行全模型微調或使用 LoRA(目前項目已經為 LoRA 配置硬編碼 r=8)、QLoRA 進行微調。
不過,項目作者表示,最終結果可能會有所不同,具體取決于用戶模型、輸入的數據、CUDA 版本以及量化工具等。實驗中,作者試著把這些因素都考慮在內,并確保最終結果在 500MB 以內。下表是作者交叉檢查了網站提供的 3b、7b 和 13b 模型占用內存與作者在 RTX 4090 和 2060 GPU 上獲得的內存比較結果。所有值均在 500MB 以內。
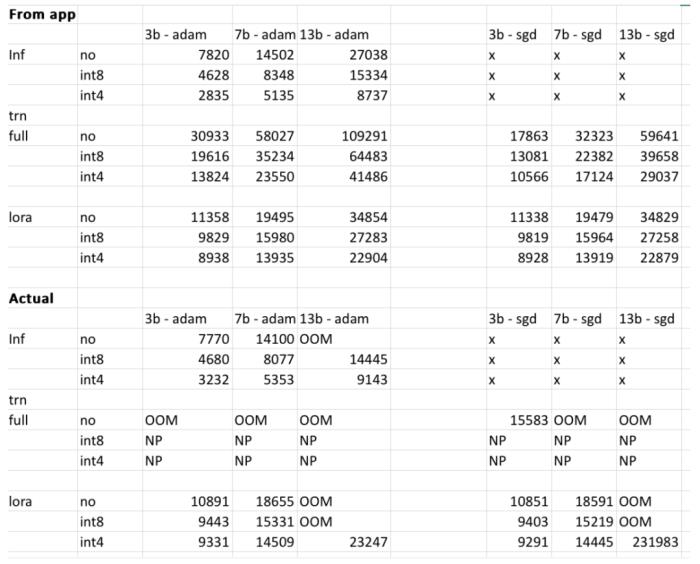
感興趣的讀者可以親自體驗一下,假如給定的結果不準確,項目作者表示,會對項目進行及時優化,完善項目。
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
